标签:lis 处理 无效 font 网址链接 turn bubuko ike 输入
此程序只是单纯的为了练习而做,首先这个顶点小说非收费型的那种小说网站(咳咳,我们应该支持正版,正版万岁,?)。经常在这个网站看小说,所以就光荣的选择了这个网站。此外,其实里面是自带下载功能的,而且支持各种格式:(TXT,CHM,UMD,JAR,APK,HTML),所以可能也并没有设置什么反爬措施,我也只设置了请求头。然后内容是保存为txt格式。
内容涉及到request的使用(编码问题),xpath的使用,字符串的处理(repalce产生列表达到换行效果),文件I/O
顶点小说:https://www.booktxt.net
代码功能:输入小说名,若顶点小说中存在,则可直接下载。最终效果如下:
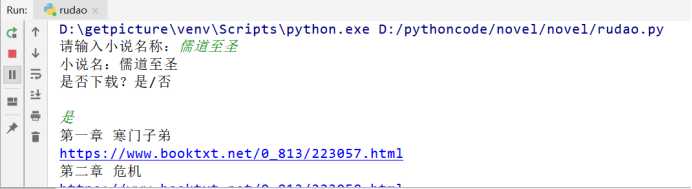
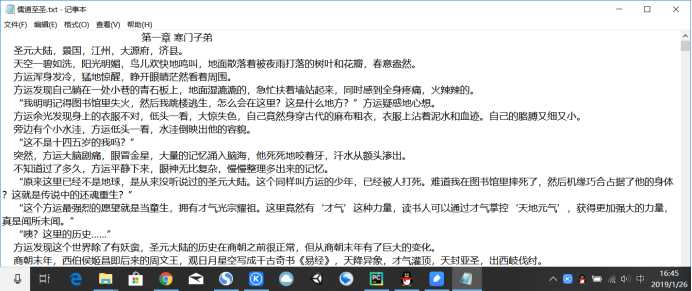
1 # -*- coding:utf-8 -*- 2 import requests 3 from lxml import etree 4 5 novel_name = ‘‘ #全局变量,存放小说名称 6 headers = { 7 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36‘} 8 9 def get_url(name): 10 ‘‘‘ 11 通过百度获取小说在顶点小说中的网址 12 name:小说名 13 ‘‘‘ 14 #site: booktxt.net + 小说名 指定为该网站搜索 15 baidu = ‘https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=site%3A%20booktxt.net%20‘+name 16 17 #获取该小说在顶点小说中的网址 18 r = requests.get(baidu, headers=headers) 19 html = etree.HTML(r.content) 20 try: 21 #提取网址链接,若不存在则退出程序 22 url = html.xpath(‘//*[@id="1"]/h3/a/@href‘)[0] 23 url =requests.get(url, headers=headers).url 24 except: 25 print("该小说不存在!") 26 exit(0) 27 if url[-4:] == ‘html‘: #搜索结果为某一章节,结果无效 28 print("该小说不存在!") 29 exit(0) 30 get_chapter(url) #获取小说章节 31 32 def get_chapter(url): 33 ‘‘‘ 34 获取搜索到的小说名,并询问是否下载 35 36 :param url: 小说的链接 37 ‘‘‘ 38 global novel_name 39 40 r = requests.get(url=url,headers=headers) 41 coding = r.apparent_encoding #获取网页编码格式 42 43 html = etree.HTML(r.content, parser=etree.HTMLParser(encoding=coding)) 44 45 novel_name = html.xpath(‘//*[@id="info"]/h1/text()‘)[0] 46 print(‘小说名:‘+novel_name+‘\n是否下载?是/否\n‘) 47 flag = input() 48 if flag==‘否‘: 49 print(‘退出系统‘) 50 exit(0) 51 52 list = html.xpath(‘//*[@id="list"]/dl/dd[position()>8]‘) #获取章节列表 53 for item in list: 54 chapter_name = item.xpath(‘./a‘)[0].text #每一章的名称 55 print(chapter_name) 56 link = item.xpath(‘./a/@href‘)[0] #每章的网址链接 57 full_link = url+link #每章的完整地址 58 print(full_link) 59 get_text(chapter_name,full_link) 60 61 def get_text(name,link): 62 ‘‘‘ 63 获取每章的内容并写入至txt文件中 64 :param name: 小说章节名 65 :param link: 章节链接 66 :return: 67 ‘‘‘ 68 69 r = requests.get(url=link, headers=headers) 70 coding = r.apparent_encoding 71 r = r.content 72 73 html = etree.HTML(r, parser=etree.HTMLParser(encoding=coding)) 74 #获取一章内容,并以空格为界分割成字符串列表 75 text = html.xpath(‘string(//*[@id="content"])‘).split() 76 #print(text) 77 #创建小说名.txt文件 78 with open(‘{}.txt‘.format(novel_name),‘a+‘,encoding=‘utf-8‘) as f: 79 f.write(‘\t‘*3+name+‘\n‘) #章节名 80 for i in range(len(text)): 81 f.write(‘ ‘*4+text[i]+‘\n‘) 82 83 if __name__ == ‘__main__‘: 86 novel_name = input(‘请输入小说名称:‘) 88 get_url(novel_name)
标签:lis 处理 无效 font 网址链接 turn bubuko ike 输入
原文地址:https://www.cnblogs.com/emmm/p/10324205.html