标签:文件 缓存 mini 延迟 work 水平 计算 element 高峰
原文:网站服务架构对于访问量大的网站而言,将网站的各个部分拆分分别部署到不同服务器上是很有必要的。例如将图片和web站点分开。一般而言,在网站的整个服务器部署上分为如下几种类型:
文件服务器:一般存储系统的相关图片和文件,给各个子系统提供统一的文件调用
代理服务器:一般使用linux+Nginx作为反向代理
web服务器:.net中最常用的Web服务器IIS,Mono中一般使用Nginx
应用服务器:负责系统中各个业务逻辑的提供,比如用户中心,结算中心,支付中心等
缓存服务器:提供MemCached缓存服务
数据库服务器:负责网站数据的提供,一般为Sqlserver,mysql,oracle等
假设网站每天要承受100万pv的访问量,计算带宽要涉及到两个指标(峰值流量和页面平均大小),带宽单位为bps(bit/s)。
1、假设峰值流量为平均流量的5倍;
2、假设每次访问的平均页面大小为100KB左右。
1B=8b---------------------1B/s=8b/s(1Bps=8bps)
1KB=1024B ------------- 1KB/s=1024B/s
1MB=1024KB------------1Mps=1024KB/s
100万pv访问量一天平均分布,折合每秒大约访问12次,页面大小为字节(Byte),总共访问页面大小就是12*100KB=1200KB,1Byte=8bit,则1200KB=9600Kb,9600Kb/1024大约9Mb/s(9Mbps),我们网站在峰值流量时一定要保持正常访问,则真实带宽应该在9M*5=45Mbps左右。
公司刚刚起步,业务量不大,往往可能在某个虚拟主机空间商租用一个虚拟主机和一个数据库就搭建了一个最基本的网站
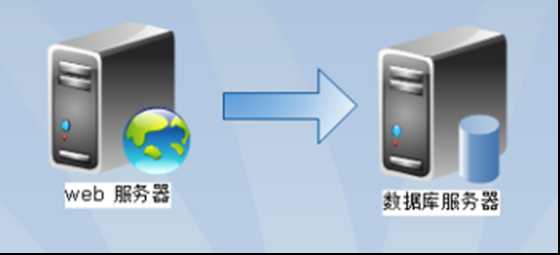
随着业务量增加,用户的访问越来越多,网站经常性的打不开,慢,甚至出现数据库链接达到最大限制数,这个时候需要针对网站做一些优化策略:
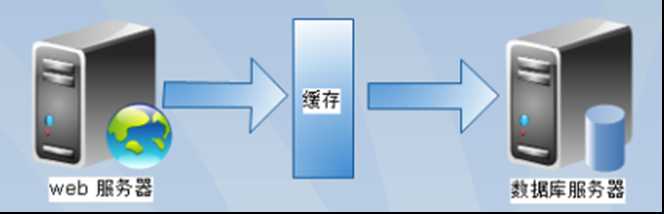
当系统访问量的再度增加,webserver机器的压力在高峰会上升到比较高,这个时候开始考虑增加一台WebServer,但是增加一台WebServer的时候意味着要在两台的服务器上分别建立相同的站点,那么就会出现如下问题:
如何让访问分配到这两台机器上?Nginx
如何保持状态信息的同步,例如用户session等?
正常考虑的方案有写入数据库、开启状态服务器、cookie、写入缓存等。
如何保持数据缓存信息的同步?
缓存服务器
如何让上传文件这些类似的功能继续正常?
采用文件服务器统一管理
通过增加web服务器享受了一段快速访问的幸福后,发现系统又开始变慢了,经过查找,发现数据库写入、更新的这些操作的部分数据库连接的 资源竞争非常激烈,导致了系统变慢,这下怎么办呢?
分库
分表
Memcache,Redis分布式缓存
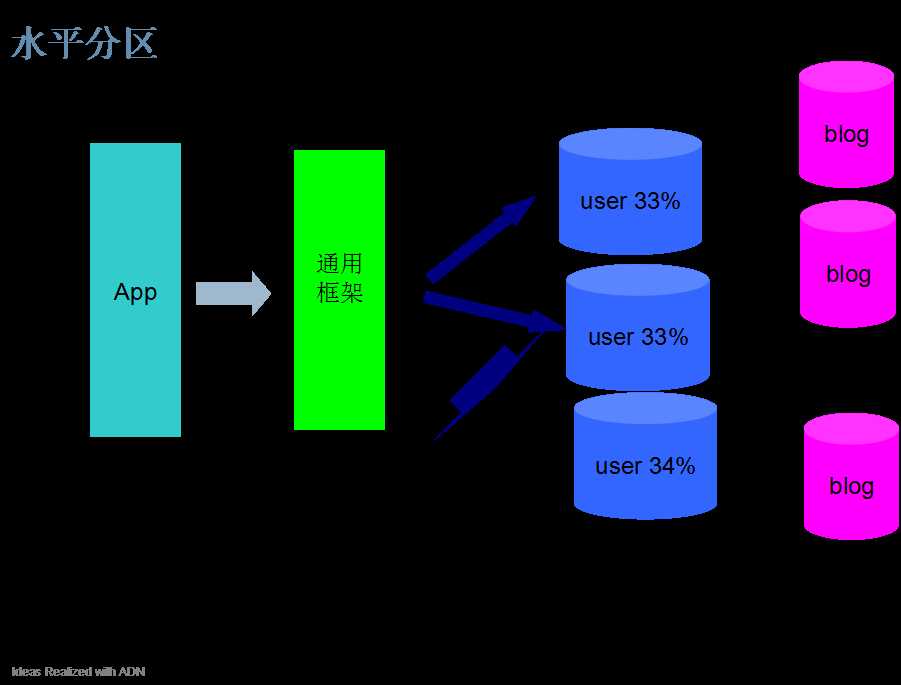
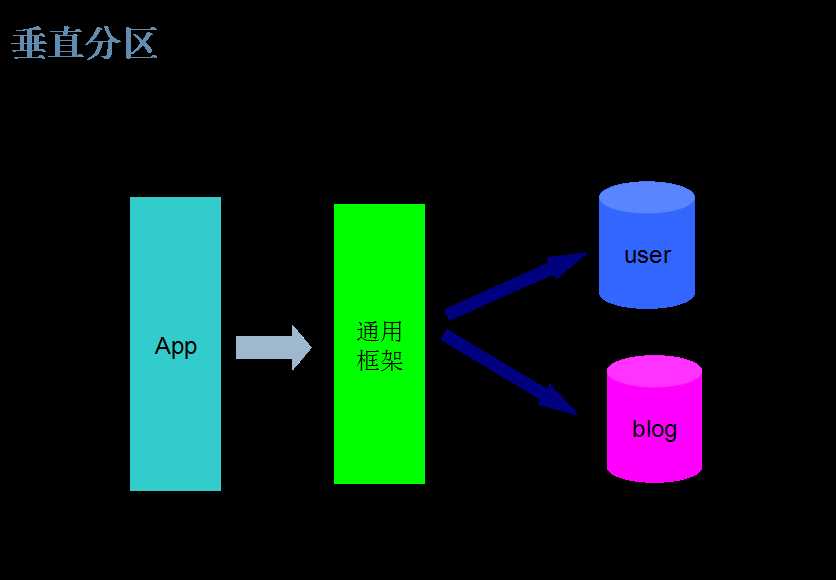
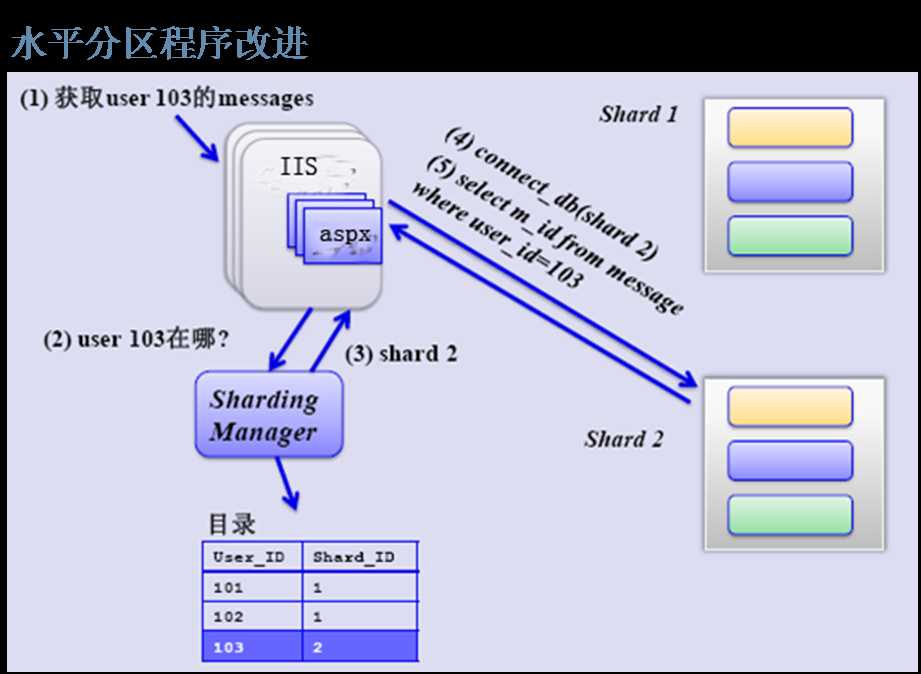
|
水平 |
垂直 |
|
|
存储依赖 |
可跨越DB |
可跨越表空间,不同的物理属性 |
|
存储方式 |
分布式 |
集中式 |
|
扩展性 |
Scale Out(横向扩展,增加便宜设备) |
Scale Up(升级设备) |
|
可用性 |
无单点 |
存在单点(DB数据本身) |
|
价格 |
低廉 |
适中,甚至昂贵 |
|
应用场景 |
web 2.0 |
在做完分库分表这些工作后,数据库上的压力已经降到比较低了,这个时候可能到了下一个瓶颈,查看windows的性能计数器发现有大量的阻塞请求,于是可以做Web园或者添加一些webserver服务器。在这个添加webserver服务器的过程,有可能会出现如下几个问题:
一台Nginx服务器的软负载已经无法承担巨大的web访问量了,可以用硬件负载解决F5或应用从逻辑上做一定的分类,然后分散到不同的软负载集群中
原有的一些状态信息同步、文件共享等方案可能会出现瓶颈,需要进行改进,也许这个时候会根据情况编写符合网站业务需求的分布式文件系统等;
在做完这些工作后,开始进入一个看似完美的无限伸缩的时代,当网站流量增加时,应对的解决方案就是不断的添加webserver。
通过增加web服务器享受了一段快速访问的幸福后,发现系统又开始变慢了,经过查找,发现数据库写入、更新的这些操作的部分数据库连接的 资源竞争非常激烈,导致了系统变慢,这下怎么办呢,读写分离,订阅和发布
NoSQL = Not Only SQL 指的是非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
NoSql数据库大量应用于微博系统等事务性不强的系统
BigTable
MongoDB
http://tech.it168.com/topic/2011/10-1/nosqlapp/index.html
经过上面这个漫长而痛苦的过程,终于再度迎来了完美的时代,不断的增加webserver就可以支撑越来越高的访问量了,但是原来部署在webserver上的那个web应用已经非常庞大 了,当多个团队都开始对其进行改动时,相当的不方便,复用性也相当糟糕,基本上每个团队都做了或多或少重复的事情,而且部署和维护也是相当的麻烦,因为庞大的应用包在N台机器上复制、启动都需要耗费不少的时间,出问题的时候也不是很好查,另外一个更糟糕的状况是很有可能会出现某个应用上的bug就导 致了全站都不可用,还有其他的像调优不好操作(因为机器上部署的应用什么都要做,根本就无法进行针对性的调优)等因素,根据这样的分析,开始痛下决心,将 系统根据职责进行拆分,于是一个大型的分布式应用就诞生了,通常,这个步骤需要耗费相当长的时间,因为会碰到很多的挑战:
1、拆成分布式后需要提供一个高性能、稳定的通信框架,并且需要支持多种不同的通信和远程调用方式;
2、将一个庞大的应用拆分需要耗费很长的时间,需要进行业务的整理和系统依赖关系的控制等;
3、如何运维(依赖管理、运行状况管理、错误追踪、调优、监控和报警等)好这个庞大的分布式应用。
经过这一步,差不多系统的架构进入相对稳定的阶段,同时也能开始采用大量的廉价机器来支撑着巨大的访问量和数据量,结合这套架构以及这么多次演变过程吸取的经验来采用其他各种各样的方法来支撑着越来越高的访问量。
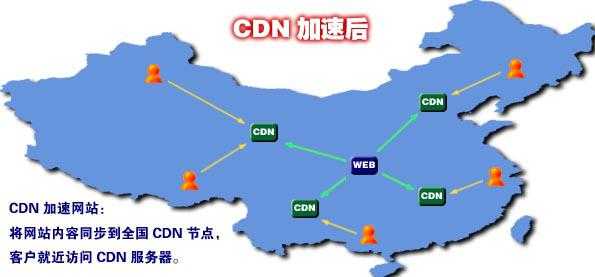
什么是CDN?
CDN的全称是Content Delivery Network,即内容分发网络。其目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络”边缘”,使用户可 以就近取得所需的内容,解决Internet网络拥塞状况,提高用户访问网站的响应速度。从技术上全面解决由于网络带宽小、用户访问量大、网点分布不均等 原因,解决用户访问网站的响应速度慢的根本原因。
狭义地讲,内容分发布网络(CDN)是一种新型的网络构建方式,它是为能在传统的IP网发布宽带丰富媒体而特别优化的网络覆盖层;而从广义的角 度,CDN代表了一种基于质量与秩序的网络服务模式。简单地说,内容发布网络(CDN)是一个经策略性部署的整体系统,包括分布式存储、负载均衡、网络请 求的重定向和内容管理4个要件,而内容管理和全局的网络流量管理(Traffic Management)是CDN的核心所在。通过用户就近性和服务器负载的判断,CDN确保内容以一种极为高效的方式为用户的请求提供服务。总的来说,内 容服务基于缓存服务器,也称作代理缓存(Surrogate),它位于网络的边缘,距用户仅有”一跳”(Single Hop)之遥。同时,代理缓存是内容提供商源服务器(通常位于CDN服务提供商的数据中心)的一个透明镜像。这样的架构使得CDN服务提供商能够代表他们 客户,即内容供应商,向最终用户提供尽可能好的体验,而这些用户是不能容忍请求响应时间有任何延迟的。据统计,采用CDN技术,能处理整个网站页面的 70%~95%的内容访问量,减轻服务器的压力,提升了网站的性能和可扩展性。
CDN 的工作原理
在描述CDN的实现原理,让我们先看传统的未加缓存服务的访问过程,以便了解CDN缓存访问方式与未加缓存访问方式的差别:
技术原理")
由上图可见,用户访问未使用CDN缓存网站的过程为:
1)、用户向浏览器提供要访问的域名;
2)、浏览器调用域名解析函数库对域名进行解析,以得到此域名对应的IP地址;
3)、浏览器使用所得到的IP地址,域名的服务主机发出数据访问请求;
4)、浏览器根据域名主机返回的数据显示网页的内容。
CDN的通俗理解就是网站加速,可以解决跨运营商,跨地区,服务器负载能力过低,带宽过少等带来的网站打开速度慢等问题。网宿,睿江,蓝讯
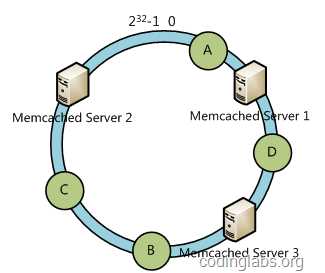
分布式架构中,节点的故障是不可避免的,当添加和删除某一节点时,会导致大量散列数据失效,需要重新散列。这意味着这些丢失的数据要去数据库中请求一次以后才能按照hash(key) /服务器数 =服务器编号 重新散列缓存到对应的服务器上。这对于高访问量的系统来讲影响是非常大的。
人们采用一致性Hash来解决此类问题
参考:
http://www.cnblogs.com/genson/archive/2009/10/22/1587836.html
标签:文件 缓存 mini 延迟 work 水平 计算 element 高峰
原文地址:https://www.cnblogs.com/lonelyxmas/p/10325301.html