标签:sea etc 日志 buffers time last nginx pool 数据库
前言:最近有些浮躁,大环境变化无常,这种情况下唯有学习才是王道,好吧,开始学习flume!
Flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。
Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于cloudera。重构后的版本统称为 Flume NG (next generation),将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力。
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中,可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个 Source。
flume具有可靠性和可恢复性。
Client:Client生产数据,运行在一个独立的线程。
Event: 一个数据单元,消息头和消息体组成。(Events可以是日志记录、 avro 对象等。)
Flow: Event从源点到达目的点的迁移的抽象。
Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。
Source: 数据收集组件。(source从Client收集数据,传递给Channel)。
Channel: 中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 sources 和 sinks ,这个有点像一个队列)。
Sink: 从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程)。
Flume 运行的核心是 Agent。Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具。Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。通过这些组件,Event 可以从一个地方流向另一个地方,如下图所示。
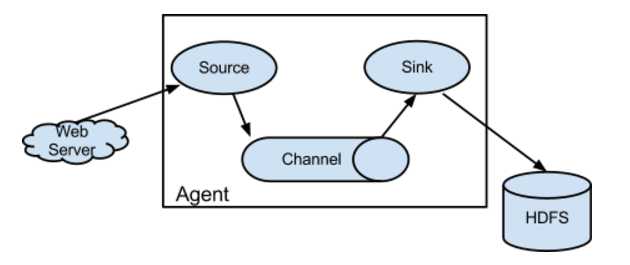
数据收集组件,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。Flume提供了各种source的实现,如:
♦ Avro Source 支持Avro协议(实际上是Avro RPC),内置支持
♦ Thrift Source 支持Thrift协议,内置支持
♦ Exec Source 基于Unix的command在标准输出上生产数据
♦ JMS Source 从JMS系统(消息、主题)中读取数据,ActiveMQ已经测试过。
♦ Spooling Directory Source 监控指定目录内数据变更
♦ NetCat Source 监控某个端口,将流经端口的每一个文本行数据作为Event输入
♦ Syslog Source 读取syslog数据,产生Event,支持UDP和TCP两种协议
♦ HTTP Source 基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示
Spool Source 如何使用?
在实际使用的过程中,可以结合log4j使用,使用log4j的时候,将log4j的文件分割机制设为1分钟一次,将文件拷贝到spool的监控目录。log4j有一个TimeRolling的插件,可以把log4j分割的文件到spool目录。基本实现了实时的监控。Flume在传完文件之后,将会修改文件的后缀,变为.COMPLETED(后缀也可以在配置文件中灵活指定)。
Exec Source 和Spool Source 比较:
(1) ExecSource可以实现对日志的实时收集,但是存在Flume不运行或者指令执行出错时,将无法收集到日志数据,无法何证日志数据的完整性。
(2) SpoolSource虽然无法实现实时的收集数据,但是可以使用以分钟的方式分割文件,趋近于实时。
(3) 总结:如果应用无法实现以分钟切割日志文件的话,可以两种 收集方式结合使用。
Channel是连接Source和Sink的组件,可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。两个较为常用的Channel, Memory Channel和File Channel。Channel类型:
♦ Memory Channel Event数据存储在内存中
♦ JDBC Channel Even数据存储在持久化存储中,当前Flume Channel内置支持Derby
♦ File Channel Event数据存储在磁盘文件中
Memory Channel和File Channel比较:
(1)Memory Channel可以实现高速的吞吐,但是无法保证数据完整性
(2)FileChannel保证数据的完整性与一致性。在具体配置不限的FileChannel时,建议FileChannel设置的目录和程序日志文
件保存的目录设成不同的磁盘,以便提高效率。
从Channel中读取并移除Event,进行相应的存储文件系统,数据库,或者提交到下一个Agent。Sink类型:
♦ HDFS Sink 数据写入HDFS
♦ Logger Sink 数据写入日志文件
♦ Avro Sink 数据被转换成Avro Event,然后发送到配置的RPC端口上
♦ Thrift Sink 数据被转换成Thrift Event,然后发送到配置的RPC端口上
♦ File Roll Sink 存储数据到本地文件系统
♦ HBase Sink 数据写入HBase数据库
♦ ElasticSearch Sink 数据发送到ElasticSearch 搜索服务器(集群)
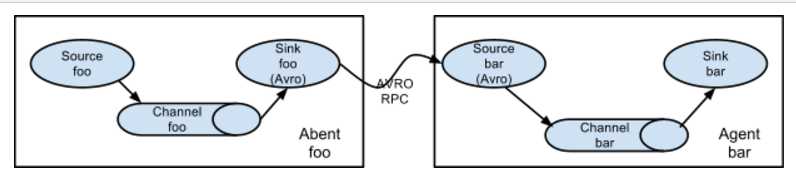
可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接的 Agent 的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。
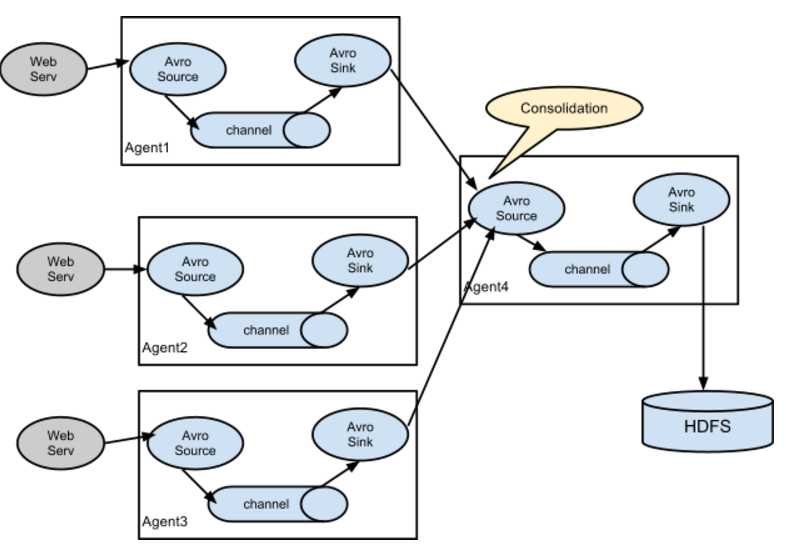
这种情况应用的场景比较多,比如要收集Web网站的用户行为日志, Web网站为了可用性使用的负载集群模式,每个节点都产生用户行为日志,可以为每个节点都配置一个Agent来单独收集日志数据,然后多个Agent将数据最终汇聚到一个用来存储数据存储系统,如HDFS上。
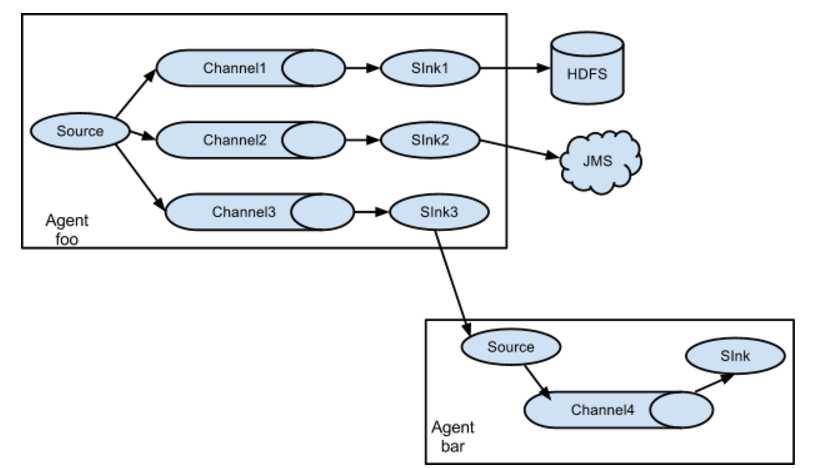
当syslog, java, nginx、 tomcat等混合在一起的日志流开始流入一个agent后,可以agent中将混杂的日志流分开,然后给每种日志建立一个自己的传输通道。
首选确认jdk是否安装,这里jdk版本为1.8。
1 .解压flume
tar zxvf apache-flume-1.8.0-bin.tar.gz -C /opt/
2. 配置
进入conf目录,新建example.conf文件,键入如下内容:
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
3. 启动flume
在flume安装目录下执行:
bin/flume-ng agent -conf conf --conf-file conf/example.conf --name a1 -Dflume.root.logger=INFO,console
 这里说明flume已经启动了,开始监听本地的44444端口的数据。
这里说明flume已经启动了,开始监听本地的44444端口的数据。
4. 测试
这里配置的是netcat需要安装telnet,可以执行yum install telnet安装。
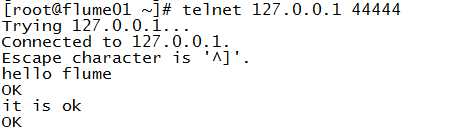
这里通过telnet向本机的44444端口发送数据。

这里成功的收到发送的数据了!
标签:sea etc 日志 buffers time last nginx pool 数据库
原文地址:https://www.cnblogs.com/wonglu/p/10328058.html