标签:没有 创建 实例化 str 的区别 不可 字节码 一个 fine
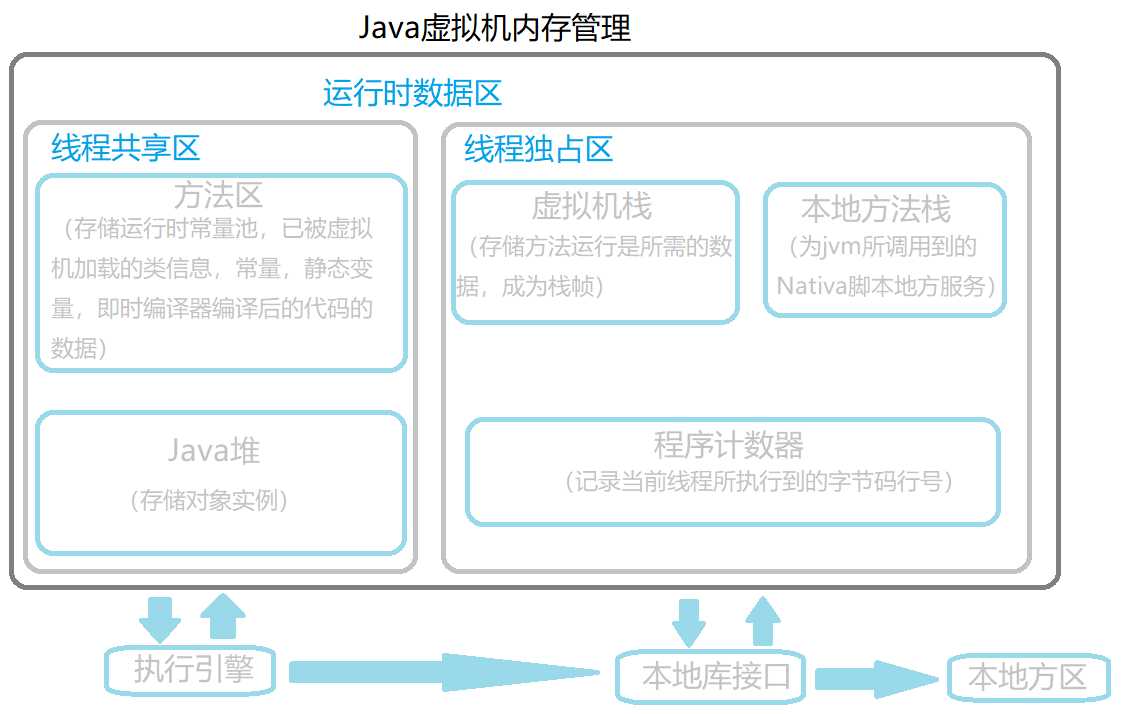
程序计数器:
Java虚拟机栈
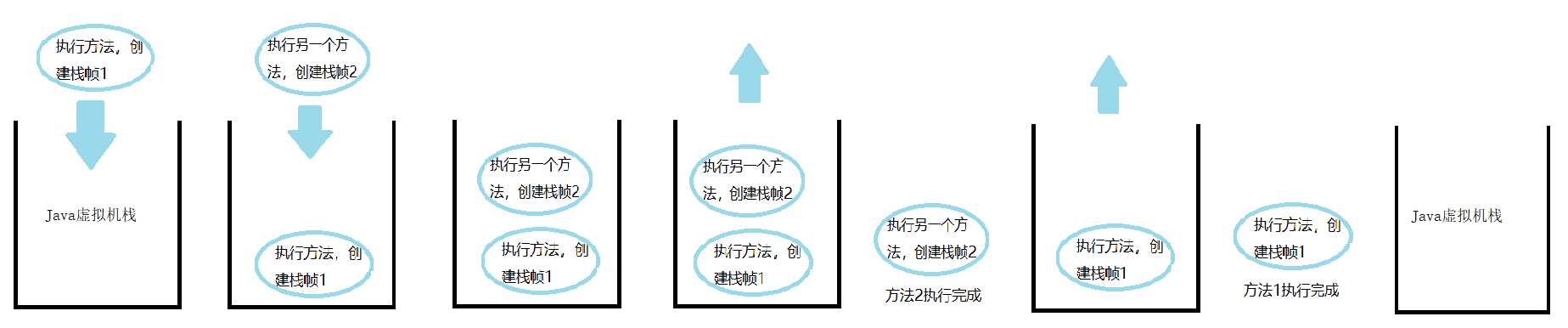
【示例1-1】:
public static void test(){
test();
}
public static void main(String[] args) {
AssetPreservationServer.test();
}
Java虚拟机栈内存溢出:

Java方法执行动态内存模型图:
本地方法栈:与Java虚拟机栈的运行都是一致的,唯一的区别是:Java虚拟机栈为虚拟机执行Java方法服务,而本地方法栈为虚拟机执行native方法服务。
Java堆:是虚拟机中管理内存最大的一块区域。也是垃圾收集器主要的管理区域,主要存放对象实例等等。
方法区:
存储虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据。
类信息包含:类的版本,字段,接口,方法等等。
运行时常量池:
常量池是属于方法区
代码【实例1-2】
public static void main(String[] args) {
String s1 = "abc";
String s2 = "abc";
String s3 = new String("abc");
System.out.println(s1 == s2);//true
System.out.println(s1 == s3);//false
System.out.println(s1 == s3.intern());//true
}
运行是常量池运行模型【示例1-3】
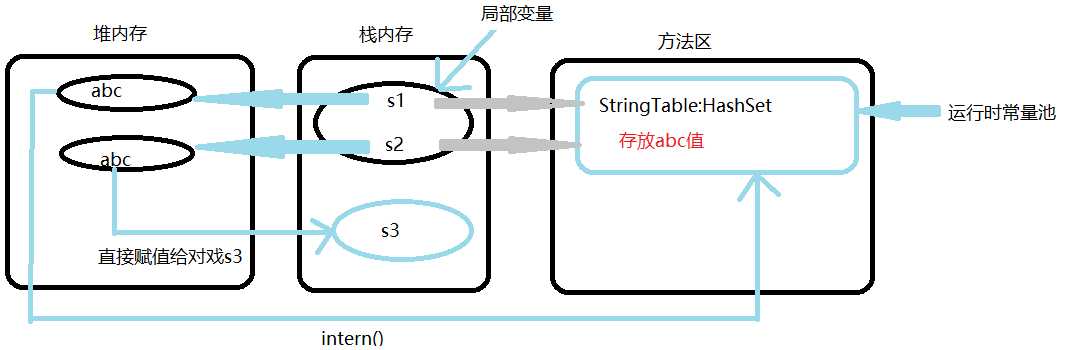
解读:
1.Java中创建两个变量s1,s2
String s1 = "abc";
String s2 = "abc";
2.程序执行到s1,s2时,Java虚拟机中栈内存开辟一块局部变量,而这块局部变量中存放了s1和s2两个变量
3.堆内存中就创建“abc”,“abc”两个实例,s1指向一个abc实例,s2指向另外一个“abc”实例
4.我们创建的每一个字符串的都会放到常量池里,所以方法区中就创建了一块常量池,在常量池中,我们可以想象有一张StringTable表,而它数据类型为一个HashSet集合,用来存放我们所实例化的对象,s1创建一个“abc”,就会放到HashSet中,创建一个就存放一个,而HashSet的特性是无序不可重复的,所以s1和s2创建的“abc”最后只存放了一个“abc”,所以s1和s2的对应地址显然是相同的(s1==s2的值是相等的)
5.再创建一个实例s3
String s3 = new String("abc");
6.第5步创建的实例是我们手动直接创建,我们通过new创建出来的对象是直接放在堆内存里,所以就不用去考虑常量池的问题了。就直接在堆内存中开辟一块空间,将值直接赋给了s3,所以s3==s1或s2时,值是false的
7.当我们在s3加intern()方法时,s1==s3.intern()的值为true,因为intern()这个方法会把我们创建的“abc”区域,搬到运行时常量池里面去,产生一个运行时常量,所以s1==s3.intern()的值是true。
标签:没有 创建 实例化 str 的区别 不可 字节码 一个 fine
原文地址:https://www.cnblogs.com/wangjiachun2017/p/10328416.html