标签:tle code rem 缩放 不变性 end ... param 数加
开局一张图,内容全靠编。
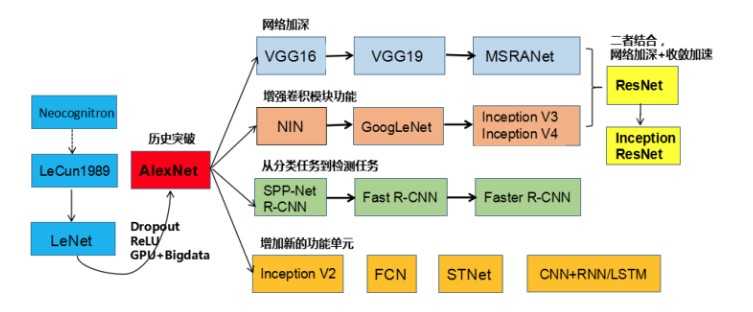
上图引用自 【卷积神经网络-进化史】从LeNet到AlexNet. 目前常用的卷积神经网络
深度学习现在是百花齐放,各种网络结构层出不穷,计划梳理下各个常用的卷积神经网络结构。 目前先梳理下用于图像分类的卷积神经网络
本文是关于卷积神经网络的开山之作LeNet的,之前想着论文较早,一直没有细读,仔细看了一遍收获满满啊。
本文有以下内容:
LeNet-5可谓是第一个卷积神经网络,并且在手写数字识别上取得了很好的效果。
对于图像像素作为神经网络的输入数据面临的一些问题:
其提出了卷积神经网络的概念,并应用
来解决上述问题。
1998年的诞生的LeNet(LeCun et al. Gradient-Based Learning Applied to Document Recognition)可谓是现在各种卷积神经网络的始祖了,其网络结构虽然只有5层,却包含了卷积神经网络的基本组件(卷积层,池化层,全连接层)
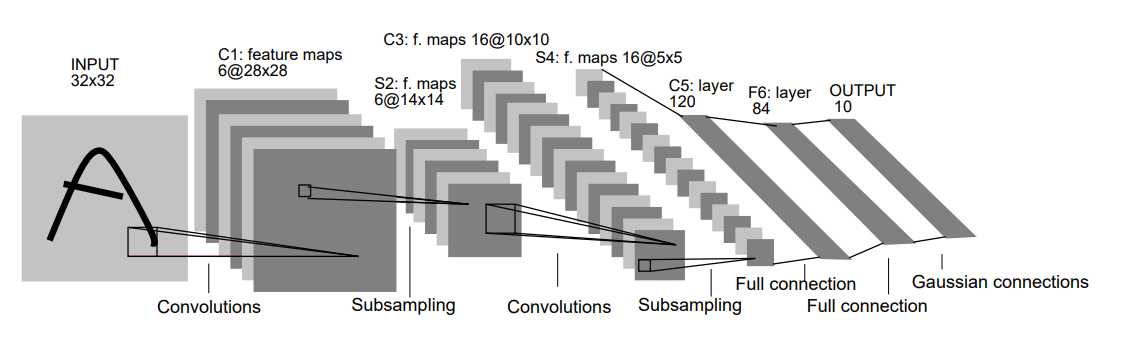
参数个数:按照神经网络的全连接设计,每个像素间都有连接的话,输入层和卷积层之间就要有122304个参数。但是在卷积神经网络中,引入了权值共享,就大大的减少了卷积层的参数的个数。对\(32\times32\)的输入,使用\(5\times5\)的核进行卷积,步长为1,卷积核每移动一步,就得到一个输出,也就需要一个权值参数(有一个连接),这就需要\((5 \times 5 + 1) \times 28 \times 28\)个参数。引入权值共享,也就是一个卷积核在卷积的产生输出的过程中,每移动一步产生输出,都使用相同的权值参数,这时候参数的个数为\((5 \times 5 + 1) \times 1\)。共有6个卷积核,\((5 \times 5 + 1) \times 6 = 156\)个参数。
设输入尺寸为\(W \times W\),卷积核尺寸为\(F \times F\),卷积步长为\(S\),填充宽度为\(P\),则卷积后输出的尺寸为\((W - F + 2P) / S + 1\)
第二个卷积层 CONV2
该层的输入为\(14 \times 14 \times 6\),使用16个核为\(5\times5\),步长为1。则其输出尺寸为\(14 - 5 + 1 = 10\)。整个层的输出为\(10 \times 10 \times 16\)。 这里要注意的本层的输入有6个Feature Map,而输出有16个Feature Map。 输入的FeatureMap和输出的FeatureMap之间并不是全连接的,而是局部连接的,具体规则如下:
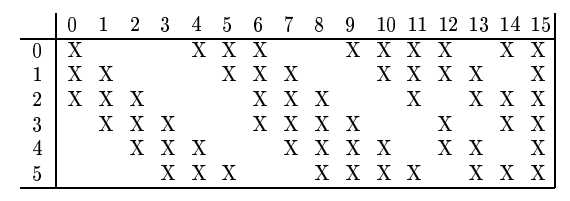
上图所示,输出的6个FeatureMap只和输入的3个FeatureMap相连接;输出的9个FeatureMap和输入的4个FeatureMap相连接;然后1个和6个连接。
- 参数个数: 由于权值共享,每个卷积核产生的输出共享同一个权值。例如,对于和3个Feature Map相连接的输出的FeatureMap,在卷积的时候,使用3个不同的卷积核分别对三个输入的FeatureMap进行卷积,然后将卷积的结果进行求和,所以其权值参数的个数是\(5 \times 5 \times + 1\)。所以,总的参数个数是\(6 \times (5 \times 5 \times 3 + 1) + 9 \times ( 5 \times 5 \times 4 + 1) + 1 \times (5 \times 5 \times 6 + 1) = 1516\)。
- 连接个数:输出的Feature Map的尺寸是\(10 \times 10\),则连接个数是: \(1516 \times 10 \times = 151600\)
第二个池化层 POOL2
输入是\(10 \times 10 \times 16\),池化参数和第一个池化层一样采用尺寸\(2 \times 2\)的池化单元,池化时的沿长和宽的步长均为2,其输出为\(5 \times 5 \times 16\),参数个数是\((1 + 1) \times 16 = 32\),连接数\((2 \times 2 + 1) \times 5 \times 5 \times 16 = 2000\)
第三个卷积层 CONV3
120个\(5\times5\)的卷积核,输入的是\(5 \times 5 \times 16\),输入的Feature Map和输出的Feature Map是全连接,输出的尺寸为\(1\times1 \times 120\)(卷积核和输入尺寸相同,且没有边缘填充)。其卷积核的参数是\(5\times5 \times 16 + 1\)。 而输出的120个神经元每个都和上一层的相连,则连接和参数的个数相同为\((5\times5 \times 16 + 1) \times 120 = 48120\)
全连接层
输入是120维的向量,本层有84个神经元,参数个数是\((120 + 1) \times 84 = 10164\)
输出层
全连接层,10个神经元,代表10个不同的数字。参数/连接个数为\(84 \times 10 = 840\)
LeNet是在1998年提出的,用于手写体数字的识别, 首次提出了卷积神经网络的基本组成:卷积层,池化层和全连接层以及权值共享,感受野等概念。 虽然时间比较久i,但是作为卷积神经网络的开山之作,还是值得入门者研读一番的。
论文提出了:
但是将像素独自的输入到神经元中则有以下问题:
有了以上的问题,LeCun就提出了大名鼎鼎的卷积神经网络(CNN)
局部感受野
在卷积神经网络的卷积层中,神经元的输入是上一层中一个像素邻域(也就是一个卷积核卷积后的结果,称为局部感受野)。 使用局部感受野,在浅层网络中神经元可以提取到图像的边缘,角点等视觉特征,这些特征在后面的网络中进行结合,组成更高层的特征。(在人工设计的特征提取器中,则很难提取图像的高层特征)。
感受野的定义: 感受野是卷积神经网络(CNN)每一层输出的特征图(feature map)上的像素点在原始输入图像上映射的区域大小。
一个局部感受野可以看作是一个卷积核进行一次卷积的结果,一个\(5\times5\)的卷积核对输入图像的\(5\times5\)邻域进行卷积得到一个输出\(P\),输入到神经元中。 在当前的卷积层中,这个\(P\)就可以代表上一层的\(5\times5\)邻域。 个人理解。
权值共享
引入权值共享的一个原因是为了解决图像的形变和平移导致的图像显著特征位置的变化。将同一个卷积核得到的结果设为相同的权值,可以有效的降低其位置不同带来的影响。权值共享的另一个依据是,在一个位置能够提取到有效的特征,在另外的位置也能提取到(特别是基础的点线特征)。另外,使用权值共享也大大的降低的网络的参数。
一个卷积核就相当于一个特征提取器,每个卷积和和输入图像进行卷积得到输出称为Feature Map,一个FeatureMap中所有的像素点和上一层的连接,使用相同的权值参数,即为权值共享。
每一层中所有的神经元形成一个平面,这个平面中所有神经元共享权值。神经元(unit)的所有输出构成特征图,特征图中所有单元在图像的不同位置执行相同的操作(同一个特征图是使用同意给卷积核得到),这样他们可以在输入图像的不同位置检测到同样的特征,一个完整的卷积层由多个特征图组成(使用不同的权值向量),这样每个位置可以提取多种特征。
一个具体的示例就是图2 LeNet-5中的第一层,第一层隐藏层中的所有单元形成6个平面,每个是一个特征图。一个特征图中的一个单元对应有25个输入,这25个输入连接到输入层的5x5区域,这个区域就是局部感受野。每个单元有25个输入,因此有25个可训练的参数加上一个偏置。由于特征图中相邻单元以前一层中连续的单元为中心,所以相邻单元的局部感受野是重叠的。比如,LeNet-5中,水平方向连续的单元的感受野存在5行4列的重叠,之前提到过,一个特征图中所有单元共享25个权值和一个偏置,所以他们在输入图像的不同位置检测相同的特征,每一层的其他特征图使用不同的一组权值和偏置,提取不同类型的局部特征。LeNet中,每个输入位置会提取6个不同的特征。特征图的一种实现方式就是使用一个带有感受野的单元,扫面整个图像,并且将每个对应的位置的状态保持在特征图中,这种操作等价于卷积,后面加入一个偏置和一个函数,因此,取名为卷积网络,卷积核就是连接的权重。卷积层的核就是特征图中所有单元使用的一组连接权重。卷积层的一个重要特性是如果输入图像发生了位移,特征图会发生相应的位移,否则特征图保持不变。这个特性是CNN对位移和形变保持鲁棒的基础。
一个卷积核提取输入数据的某种特征输出一个Feature Map。 既然提取的是同一种特征,那么使用同一个权值也是应该的。
下采样,池化
在图像分类中,起主导作用的是图像特征的相对位置,如图像中的数字7从左上角移到右下角,仍然是数字7,重要的是直线-点-直线之间的相对位置。因为图像的平移,形变是很常见的,所以图像特征的精确的位置信息,在分类识别中甚至是有害的。 通过降低图像分辨率的方式来降低图像特征位置的精度,使用池化函数(均值或者最大)对图像进行下采样,降低网络的输出对图像形变和平移的敏感程度。如果对图像做平移,那么对应于高层特征的平移(因为权值共享);如果对图像做局部旋转,小范围旋转/扭曲会被局部感受野消除,大范围扭曲会因为降采样而模糊掉其影响。
并没有,精确的实现论文中描述的LeNet-5的网络结构,只是照着实现了一个简单的卷积神经网络,网络结构如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 32, 32, 20) 1520
_________________________________________________________________
activation_1 (Activation) (None, 32, 32, 20) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 16, 20) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 16, 16, 50) 25050
_________________________________________________________________
activation_2 (Activation) (None, 16, 16, 50) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 8, 8, 50) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 3200) 0
_________________________________________________________________
dense_1 (Dense) (None, 500) 1600500
_________________________________________________________________
activation_3 (Activation) (None, 500) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 5010
_________________________________________________________________
activation_4 (Activation) (None, 10) 0
=================================================================
Total params: 1,632,080
Trainable params: 1,632,080
Non-trainable params: 0
_________________________________________________________________调用Keras API可以很容易的实现上述的结构
# -*- coding:utf-8 -*-
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras import backend as K
class LeNet:
@staticmethod
def build(width,height,depth,classes):
model = Sequential()
inputShape = (height,width,depth)
if K.image_data_format() == "channels_first":
inputShape = (depth,height,width)
# first set of CONV => RELU => POOL
model.add(Conv2D(20,(5,5),padding="same",input_shape=inputShape))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))
# second set of CONV => RELU => POOL_layers
model.add(Conv2D(50,(5,5),padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))
# set of FC => RELU layers
model.add(Flatten())
model.add(Dense(500))
model.add(Activation("relu"))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
return model将上述网络应用于CIFAR10数据集进行分类
测试代码,首先使用scikit-learn加载CIFAR10数据,并进行归一化
print("[INFO] loading CIFAR-10 data...")
((trainX,trainY),(testX,testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0对CIFAR10的类别进行编码
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.fit_transform(testY)处理完数据后,调用上面的LeNet建立LeNet网络结构并使用trainX数据集进行训练
print("[INFO] compiling model...")
opt = SGD(lr=0.05)
model = lenet.LeNet.build(width=width,height=height,depth=depth,classes=classes)
model.compile(loss="categorical_crossentropy",optimizer=opt,metrics=["accuracy"])
# train
print("[INFO] training network...")
H = model.fit(trainX,trainY,validation_data=(testX,testY),batch_size=32,epochs=epochs,verbose=1)最后使用testX数据集进行评估
# evaluate the network
print("[INFO] evaluating networking...")
predictions = model.predict(testX,batch_size=32)
print(classification_report(testY.argmax(axis=1),predictions.argmax(axis=1),
target_names=labelNames))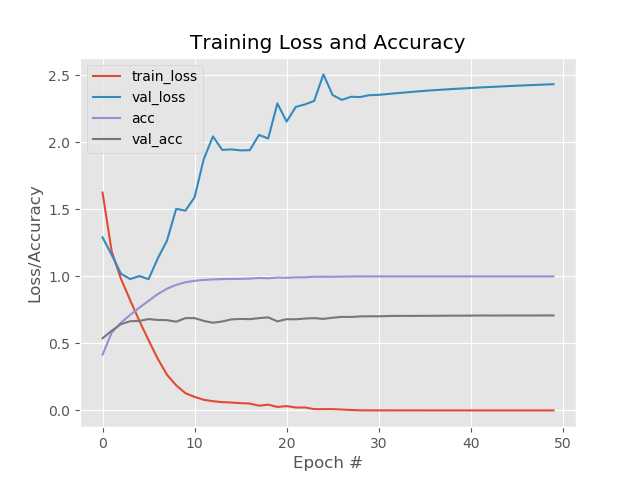
很明显的过拟合了,这里就不关注这个精度了,只是简单的测试下。
更详细的测试代码,可以Start/Fork GitHub上https://github.com/brookicv/machineLearningSample 以及 https://github.com/brookicv/imageClassification
标签:tle code rem 缩放 不变性 end ... param 数加
原文地址:https://www.cnblogs.com/wangguchangqing/p/10329402.html