标签:html 生成 图表 post wmf 自动 variant href prism
转:
测试模板样式:
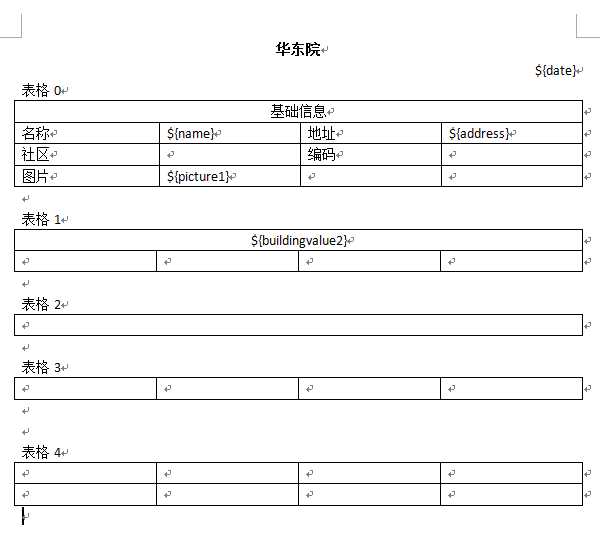
Word生成结果:

图表 2
需要的jar包:(具体jar可自行去maven下载)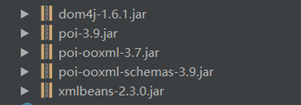
注意:需要严格按照上面版本下载jar包,否则可能出现jar包之间不能匹配的导致代码报错
各种 jar包都可以在这里下载:
Test测试类:
package p1; import java.io.FileInputStream; import java.io.FileOutputStream; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; public class Main { public static void main(String[] args) throws Exception { //需要进行文本替换的信息 Map<String, Object> data = new HashMap<String, Object>(); data.put("${date}", "2018-03-06"); data.put("${name}", "东方明珠"); data.put("${address}", "华东院"); /* data.put("${communityvalue}", ""); data.put("${safetycode}", "华东院"); data.put("${picture2}", ""); data.put("${picture3}", "");*/ data.put("${buildingvalue2}", "华东院"); /* data.put("${patrolPhoto1}", ""); data.put("${patrolPhoto2}", ""); data.put("${buildingvalue3}", "中国");*/ //图片,如果是多个图片,就新建多个map Map<String,Object> picture1 = new HashMap<String, Object>(); picture1.put("width", 100); picture1.put("height", 150); picture1.put("type", "jpg"); picture1.put("content", WorderToNewWordUtils.inputStream2ByteArray(new FileInputStream("D:/docTest/p1.jpg"), true)); data.put("${picture1}",picture1); //需要进行动态生成的信息 List<Object> mapList = new ArrayList<Object>(); //第一个动态生成的数据列表 List<String[]> list01 = new ArrayList<String[]>(); list01.add(new String[]{"A","11111111111","22","22"}); list01.add(new String[]{"A","22222222222","33","22"}); list01.add(new String[]{"B","33333333333","44","22"}); list01.add(new String[]{"C","44444444444","55","22"}); //第二个动态生成的数据列表 List<String[]> list02 = new ArrayList<String[]>(); list02.add(new String[]{"A","11111111111","22","22"}); list02.add(new String[]{"d","22222222222","33","22"}); list02.add(new String[]{"B","33333333333","44","22"}); list02.add(new String[]{"C","44444444444","55","22"}); mapList.add(list01); mapList.add(list02); //需要动态改变表格的位置;第一个表格的位置为0 int[] placeList = {1,4}; CustomXWPFDocument doc = WorderToNewWordUtils.changWord("D:/docTest/t1.docx",data,mapList,placeList); FileOutputStream fopts = new FileOutputStream("D:/呵呵.docx"); doc.write(fopts); fopts.close(); } }
WorderToNewWordUtils类:
package p1; import java.io.ByteArrayInputStream; import java.io.IOException; import java.io.InputStream; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Set; import org.apache.poi.POIXMLDocument; import org.apache.poi.xwpf.usermodel.XWPFParagraph; import org.apache.poi.xwpf.usermodel.XWPFRun; import org.apache.poi.xwpf.usermodel.XWPFTable; import org.apache.poi.xwpf.usermodel.XWPFTableCell; import org.apache.poi.xwpf.usermodel.XWPFTableRow; import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTTcPr; import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTVMerge; import org.openxmlformats.schemas.wordprocessingml.x2006.main.STMerge; /** * Created by 王景伟 on 2018/12/19. */ public class WorderToNewWordUtils { /** * 根据模板生成word文档 * @param inputUrl 模板路径 * @param textMap 需要替换的文本内容 * @param mapList 需要动态生成的内容 * @return */ public static CustomXWPFDocument changWord(String inputUrl, Map<String, Object> textMap, List<Object> mapList,int[] placeList) { CustomXWPFDocument document = null; try { //获取docx解析对象 document = new CustomXWPFDocument(POIXMLDocument.openPackage(inputUrl)); //解析替换文本段落对象 WorderToNewWordUtils.changeText(document, textMap); //解析替换表格对象 WorderToNewWordUtils.changeTable(document, textMap, mapList,placeList); } catch (IOException e) { e.printStackTrace(); } return document; } /** * 替换段落文本 * @param document docx解析对象 * @param textMap 需要替换的信息集合 */ public static void changeText(CustomXWPFDocument document, Map<String, Object> textMap){ //获取段落集合 List<XWPFParagraph> paragraphs = document.getParagraphs(); for (XWPFParagraph paragraph : paragraphs) { //判断此段落时候需要进行替换 String text = paragraph.getText(); if(checkText(text)){ List<XWPFRun> runs = paragraph.getRuns(); for (XWPFRun run : runs) { //替换模板原来位置 Object ob = changeValue(run.toString(), textMap); System.out.println("段落:"+run.toString()); if (ob instanceof String){ run.setText((String)ob,0); } } } } } /** * 替换表格对象方法 * @param document docx解析对象 * @param textMap 需要替换的信息集合 * @param mapList 需要动态生成的内容 */ public static void changeTable(CustomXWPFDocument document, Map<String, Object> textMap, List<Object> mapList,int[] placeList){ //获取表格对象集合 List<XWPFTable> tables = document.getTables(); //循环所有需要进行替换的文本,进行替换 for (int i = 0; i < tables.size(); i++) { XWPFTable table = tables.get(i); if(checkText(table.getText())){ List<XWPFTableRow> rows = table.getRows(); System.out.println("简单表格替换:"+rows); //遍历表格,并替换模板 eachTable(document,rows, textMap); } } int index=0; //操作word中的表格 for (int i = 0; i < tables.size(); i++) { //只处理行数大于等于2的表格,且不循环表头 XWPFTable table = tables.get(i); if(placeList[index]==i){ List<String[]> list = (List<String[]>) mapList.get(index); //第二个表格使用daList,插入数据 if (null != list && 0 < list.size()){ insertTable(table, null,list,2); List<Integer[]> indexList = startEnd(list); for (int c=0;c<indexList.size();c++){ //合并行 mergeCellVertically(table,0,indexList.get(c)[0]+1,indexList.get(c)[1]+1); } } index++; } } } /** * 遍历表格 * @param rows 表格行对象 * @param textMap 需要替换的信息集合 */ public static void eachTable(CustomXWPFDocument document, List<XWPFTableRow> rows , Map<String, Object> textMap){ for (XWPFTableRow row : rows) { List<XWPFTableCell> cells = row.getTableCells(); for (XWPFTableCell cell : cells) { //判断单元格是否需要替换 if(checkText(cell.getText())){ List<XWPFParagraph> paragraphs = cell.getParagraphs(); for (XWPFParagraph paragraph : paragraphs) { List<XWPFRun> runs = paragraph.getRuns(); for (XWPFRun run : runs) { Object ob = changeValue(run.toString(), textMap); if (ob instanceof String){ run.setText((String)ob,0); }else if (ob instanceof Map){ run.setText("",0); Map pic = (Map)ob; int width = Integer.parseInt(pic.get("width").toString()); int height = Integer.parseInt(pic.get("height").toString()); int picType = getPictureType(pic.get("type").toString()); byte[] byteArray = (byte[]) pic.get("content"); ByteArrayInputStream byteInputStream = new ByteArrayInputStream(byteArray); try { int ind = document.addPicture(byteInputStream,picType); document.createPicture(ind, width , height,paragraph); } catch (Exception e) { e.printStackTrace(); } } } } } } } } /** * 为表格插入数据,行数不够添加新行 * @param table 需要插入数据的表格 * @param tableList 第四个表格的插入数据 * @param daList 第二个表格的插入数据 * @param type 表格类型:1-第一个表格 2-第二个表格 3-第三个表格 4-第四个表格 */ public static void insertTable(XWPFTable table, List<String> tableList,List<String[]> daList,Integer type){ if (2 == type){ //创建行和创建需要的列 for(int i = 1; i < daList.size(); i++){ //添加一个新行 XWPFTableRow row = table.insertNewTableRow(1); for(int k=0; k<daList.get(0).length;k++){ row.createCell();//根据String数组第一条数据的长度动态创建列 } } //创建行,根据需要插入的数据添加新行,不处理表头 for(int i = 0; i < daList.size(); i++){ List<XWPFTableCell> cells = table.getRow(i+1).getTableCells(); for(int j = 0; j < cells.size(); j++){ XWPFTableCell cell02 = cells.get(j); cell02.setText(daList.get(i)[j]); } } }else if (4 == type){ //插入表头下面第一行的数据 for(int i = 0; i < tableList.size(); i++){ XWPFTableRow row = table.createRow(); List<XWPFTableCell> cells = row.getTableCells(); cells.get(0).setText(tableList.get(i)); } } } /** * 判断文本中时候包含$ * @param text 文本 * @return 包含返回true,不包含返回false */ public static boolean checkText(String text){ boolean check = false; if(text.indexOf("$")!= -1){ check = true; } return check; } /** * 匹配传入信息集合与模板 * @param value 模板需要替换的区域 * @param textMap 传入信息集合 * @return 模板需要替换区域信息集合对应值 */ public static Object changeValue(String value, Map<String, Object> textMap){ Set<Map.Entry<String, Object>> textSets = textMap.entrySet(); Object valu = ""; for (Map.Entry<String, Object> textSet : textSets) { //匹配模板与替换值 格式${key} String key = textSet.getKey(); if(value.indexOf(key)!= -1){ valu = textSet.getValue(); } } return valu; } /** * 将输入流中的数据写入字节数组 * @param in * @return */ public static byte[] inputStream2ByteArray(InputStream in, boolean isClose){ byte[] byteArray = null; try { int total = in.available(); byteArray = new byte[total]; in.read(byteArray); } catch (IOException e) { e.printStackTrace(); }finally{ if(isClose){ try { in.close(); } catch (Exception e2) { System.out.println("关闭流失败"); } } } return byteArray; } /** * 根据图片类型,取得对应的图片类型代码 * @param picType * @return int */ private static int getPictureType(String picType){ int res = CustomXWPFDocument.PICTURE_TYPE_PICT; if(picType != null){ if(picType.equalsIgnoreCase("png")){ res = CustomXWPFDocument.PICTURE_TYPE_PNG; }else if(picType.equalsIgnoreCase("dib")){ res = CustomXWPFDocument.PICTURE_TYPE_DIB; }else if(picType.equalsIgnoreCase("emf")){ res = CustomXWPFDocument.PICTURE_TYPE_EMF; }else if(picType.equalsIgnoreCase("jpg") || picType.equalsIgnoreCase("jpeg")){ res = CustomXWPFDocument.PICTURE_TYPE_JPEG; }else if(picType.equalsIgnoreCase("wmf")){ res = CustomXWPFDocument.PICTURE_TYPE_WMF; } } return res; } /** * 合并行 * @param table * @param col 需要合并的列 * @param fromRow 开始行 * @param toRow 结束行 */ public static void mergeCellVertically(XWPFTable table, int col, int fromRow, int toRow) { for(int rowIndex = fromRow; rowIndex <= toRow; rowIndex++){ CTVMerge vmerge = CTVMerge.Factory.newInstance(); if(rowIndex == fromRow){ vmerge.setVal(STMerge.RESTART); } else { vmerge.setVal(STMerge.CONTINUE); } XWPFTableCell cell = table.getRow(rowIndex).getCell(col); CTTcPr tcPr = cell.getCTTc().getTcPr(); if (tcPr != null) { tcPr.setVMerge(vmerge); } else { tcPr = CTTcPr.Factory.newInstance(); tcPr.setVMerge(vmerge); cell.getCTTc().setTcPr(tcPr); } } } /** * 获取需要合并单元格的下标 * @return */ public static List<Integer[]> startEnd(List<String[]> daList){ List<Integer[]> indexList = new ArrayList<Integer[]>(); List<String> list = new ArrayList<String>(); for (int i=0;i<daList.size();i++){ list.add(daList.get(i)[0]); } Map<Object, Integer> tm = new HashMap<Object, Integer>(); for (int i=0;i<daList.size();i++){ if (!tm.containsKey(daList.get(i)[0])) { tm.put(daList.get(i)[0], 1); } else { int count = tm.get(daList.get(i)[0]) + 1; tm.put(daList.get(i)[0], count); } } for (Map.Entry<Object, Integer> entry : tm.entrySet()) { String key = entry.getKey().toString(); String value = entry.getValue().toString(); if (list.indexOf(key) != (-1)){ Integer[] index = new Integer[2]; index[0] = list.indexOf(key); index[1] = list.lastIndexOf(key); indexList.add(index); } } return indexList; } }
CustomXWPFDocument类:
package p1; import java.io.IOException; import java.io.InputStream; import org.apache.poi.openxml4j.opc.OPCPackage; import org.apache.poi.xwpf.usermodel.XWPFDocument; import org.apache.poi.xwpf.usermodel.XWPFParagraph; import org.apache.xmlbeans.XmlException; import org.apache.xmlbeans.XmlToken; import org.openxmlformats.schemas.drawingml.x2006.main.CTNonVisualDrawingProps; import org.openxmlformats.schemas.drawingml.x2006.main.CTPositiveSize2D; import org.openxmlformats.schemas.drawingml.x2006.wordprocessingDrawing.CTInline; /** * Created by 王景伟 on 2018/12/19. * 自定义 XWPFDocument,并重写 createPicture()方法 */ public class CustomXWPFDocument extends XWPFDocument{ public CustomXWPFDocument(InputStream in) throws IOException { super(in); } public CustomXWPFDocument() { super(); } public CustomXWPFDocument(OPCPackage pkg) throws IOException { super(pkg); } /** * @param id * @param width 宽 * @param height 高 * @param paragraph 段落 */ public void createPicture(int id, int width, int height,XWPFParagraph paragraph) { final int EMU = 9525; width *= EMU; height *= EMU; String blipId = getAllPictures().get(id).getPackageRelationship().getId(); CTInline inline = paragraph.createRun().getCTR().addNewDrawing().addNewInline(); System.out.println(blipId+":"+inline); String picXml = "" + "<a:graphic xmlns:a=\"http://schemas.openxmlformats.org/drawingml/2006/main\">" + " <a:graphicData uri=\"http://schemas.openxmlformats.org/drawingml/2006/picture\">" + " <pic:pic xmlns:pic=\"http://schemas.openxmlformats.org/drawingml/2006/picture\">" + " <pic:nvPicPr>" + " <pic:cNvPr id=\"" + id + "\" name=\"Generated\"/>" + " <pic:cNvPicPr/>" + " </pic:nvPicPr>" + " <pic:blipFill>" + " <a:blip r:embed=\"" + blipId + "\" xmlns:r=\"http://schemas.openxmlformats.org/officeDocument/2006/relationships\"/>" + " <a:stretch>" + " <a:fillRect/>" + " </a:stretch>" + " </pic:blipFill>" + " <pic:spPr>" + " <a:xfrm>" + " <a:off x=\"0\" y=\"0\"/>" + " <a:ext cx=\"" + width + "\" cy=\"" + height + "\"/>" + " </a:xfrm>" + " <a:prstGeom prst=\"rect\">" + " <a:avLst/>" + " </a:prstGeom>" + " </pic:spPr>" + " </pic:pic>" + " </a:graphicData>" + "</a:graphic>"; inline.addNewGraphic().addNewGraphicData(); XmlToken xmlToken = null; try { xmlToken = XmlToken.Factory.parse(picXml); } catch (XmlException xe) { xe.printStackTrace(); } inline.set(xmlToken); inline.setDistT(0); inline.setDistB(0); inline.setDistL(0); inline.setDistR(0); CTPositiveSize2D extent = inline.addNewExtent(); extent.setCx(width); extent.setCy(height); CTNonVisualDrawingProps docPr = inline.addNewDocPr(); docPr.setId(id); docPr.setName("图片" + id); docPr.setDescr("测试"); } }
方法调用:
导入jar包
复制以上CustomXWPFDocument类和WorderToNewWordUtils类到项目合适路径(根据自己项目情况判断)
主类调用方法说明(既以上Test测试类)
对于一般的字段替换,只需要保持(key,value)的键值对方式赋值替换即可,key和模板占位字符保持一致,例:
Map<String, Object> data = new HashMap<String, Object>();
data.put("date","2018?03?06");data.put("{date}", "2018-03-06");data.put("date","2018?03?06");data.put("{name}", “东方明珠”);
data.put("address","华东院");data.put("{address}", "华东院");data.put("address","华东院");data.put("{communityvalue}", “”);
data.put("safetycode","华东院");data.put("{safetycode}", "华东院");data.put("safetycode","华东院");data.put("{picture2}", “”);
data.put("picture3","");data.put("{picture3}", "");data.put("picture3","");data.put("{buildingvalue2}", “华东院”);
data.put("patrolPhoto1","");data.put("{patrolPhoto1}", "");data.put("patrolPhoto1","");data.put("{patrolPhoto2}", “”);data.put("${buildingvalue3}", “中国”);
如果需要插入图片,则需要重新创建一个Map集合存储图片数据:例
Map<String,Object> picture1 = new HashMap<String, Object>();
picture1.put(“width”, 100);
picture1.put(“height”, 150);
picture1.put(“type”, “jpg”);
picture1.put(“content”, WorderToNewWordUtils.inputStream2ByteArray(new FileInputStream(“D:/timg.jpg”), true));
data.put("${picture1}",picture1);
如果有多张图片,则需要创建多个Map保存图片,其中它的属性值应保持不变(如上:width,height,type,content),需要注意的是对于一般字段或者是图片最终都存储在data集合中,如下:
Map<String, Object> data = new HashMap<String, Object>();
对于需要根据具体数据动态生成的表格,我们将数据存储在一个List集合中,如:
//第一个动态生成的数据列表
List<String[]> list01 = new ArrayList<String[]>();
list01.add(new String[]{“A”,“11111111111”,“22”,“22”});
list01.add(new String[]{“A”,“22222222222”,“33”,“22”});
list01.add(new String[]{“B”,“33333333333”,“44”,“22”});
list01.add(new String[]{“C”,“44444444444”,“55”,“22”});
//第二个动态生成的数据列表
List<String[]> list02 = new ArrayList<String[]>();
list02.add(new String[]{“A”,“11111111111”,“22”,“22”});
list02.add(new String[]{“d”,“22222222222”,“33”,“22”});
list02.add(new String[]{“B”,“33333333333”,“44”,“22”});
list02.add(new String[]{“C”,“44444444444”,“55”,“22”});
如上是两个我们需要根据具体数据动态生成的表格,如list01中数据,当list中String数组的第一个字段相同时,则在创建动态表格时会将这两个单元格合并,其他列数值相同不影响合并。注意:这里的创建的String数组的列数应该和模板的表格列数保持一致。数据保存好之后将list数组统一保存在mapList中,如下:
List mapList = new ArrayList();
注意:
由于无法动态获取需要动态填充的表格,所以我们定义了一个静态数组保存需要动态生成的表格的位置,如下:
//需要动态改变表格的位置;第一个表格的位置为0
int[] placeList = {1,4};
如图1所示,从上至下表格所在位置分别是0-4;而我们需要动态生成的是第二个和第五个,故此处传参{1,4}
最后调用方法导出word即可;如下:
CustomXWPFDocument doc = WorderToNewWordUtils.changWord("C:/Users/user/Desktop/test1.docx",data,mapList,placeList);
FileOutputStream fopts = new FileOutputStream("D:/呵呵.docx");
doc.write(fopts);
fopts.close();
在changeWord方法中,第一个参数是模板路径,第二个参数是填充数据,第三个参数是动态表格填充数据,第四个参数是动态表格位置;
友情提醒:(以下内容若需要可采纳,不需要可跳过)
使用poi生成Word会发生分段混乱的问题,例如:在操作POI替换word时发现getRuns将我们预设的${product}自动切换成了成了两个部分
${product } 或者 product既会出现空格分离字段的情况;建议使用从左往右的顺序进行模板字段填充(既:{ product } 既会出现空格分离字段的情况;建议使用从左往右的顺序进行模板字段填充(既:product既会出现空格分离字段的情况;建议使用从左往右的顺序进行模板字段填充(既:→{→product→} 而不是 $→{→}→product的方式);
亲测有效:使用notepad++的xml插件修改模板(保证解析完美)
(一) 安装notepad++并为其添加插件XML Tools插件(具体步骤自行百度)
(二) 将修改好的word模板另存为xml格式的文档;如下图所示
(三) 使用notepad++打开xml模板,刚开始打开是一个毫无逻辑可寻的文件,这时我们使用xml tools工具格式化xml文件:如下:
(四) 如上图可看出模板被解析成了多部分,此时我们修改文件,让其保持为一个字段:如下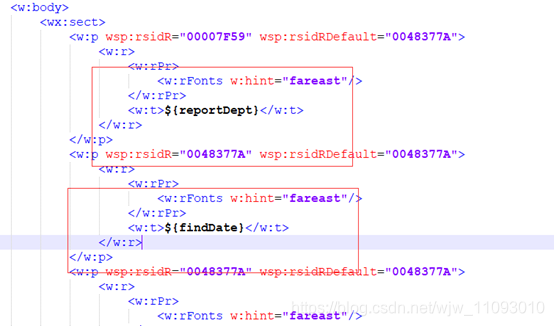
(五) 保存文档之后用word打开xml文档,然后另存为所需要的docx格式word即可
create by 王景伟
2018-12-19
Java利用poi生成word(包含插入图片,动态表格,行合并)
标签:html 生成 图表 post wmf 自动 variant href prism
原文地址:https://www.cnblogs.com/libin6505/p/10330868.html