标签:免费 添加 http 自带 img 很多 总结 blog 指定

导语
最近图慌,于是随便写了个表情包批量下载的脚本,没什么技术含量,纯娱乐性质。
让我们愉快地开始吧~
开发工具
Python版本:3.6.4
相关模块:
requests模块;
fake_useragent模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
原理简介
爬的站长之家的表情包,链接:
http://sc.chinaz.com/biaoqing/index.html
非常好爬,思路也很简单:
① 获得表情包所在地址;
② 根据表情包所在地址,获得表情所在地址;
③ 根据表情所在地址下载表情。
具体实现过程详见相关文件中的源代码。
或许很多人都发现了,爬虫相关的文章我都是轻描淡写地说下主要思路然后让大家自己看源码的,一方面是我懒得写,另一方面是爬虫代码的存活时间不长,换句话说就是你花了很多时间写的文章过几个月甚至过几天可能就“没用”了。
不过今天我打算随手总结一下普通的反爬虫机制有哪些内容:
(1)验证码
(2)Header检验
即检查HTTP请求的Headers信息,一般包括:
User-Agent(UA);Referer;Cookies等。
User-Agent:
当前用户使用的客户端种类和版本;
Referer:
请求是从哪里来的;
Cookie:
有时候网站会检测Cookie中session_id的使用次数,显然当次数过多时,当前用户会被认为是爬虫。
(3)IP请求速度检验
当某个IP的请求速度过快时,就会触发该网站的反爬机制。
(4)动态加载
ajax动态加载网页内容。
That‘s all.
运行截图
指定爬取的范围:

在cmd窗口运行"Spider.py"文件即可。
效果截图: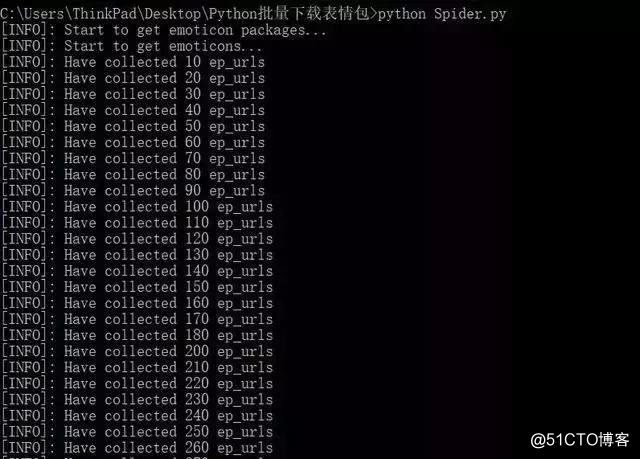
好了,如果你跟我一样都喜欢python,想成为一名优秀的程序员,也在学习python的道路上奔跑,欢迎你加入python学习群:839383765 群内每天都会分享最新业内资料,分享python免费课程,共同交流学习,让学习变(编)成(程)一种习惯!
自从会了Python在群里斗图就没输过,Python批量下载表情包!
标签:免费 添加 http 自带 img 很多 总结 blog 指定
原文地址:http://blog.51cto.com/14186420/2347323