标签:流程 一个 mode 中文 分享 orm alt 自然语言处理 port
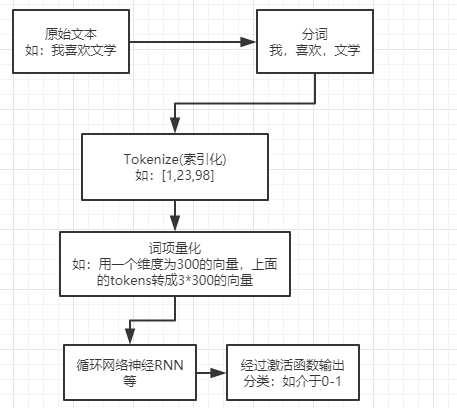
分析流程:
加载预训练词向量模型:https://github.com/Embedding/Chinese-Word-Vectors/
from gensim.models import KeyedVectors cn_model = KeyedVectors.load_word2vec_format(‘H:/词向量/word+Ngram/sgns.zhihu.bigram‘, binary=False)
查看词语的向量模型表示: 维度为300

词语相似度:向量余弦值
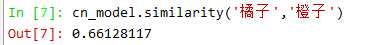
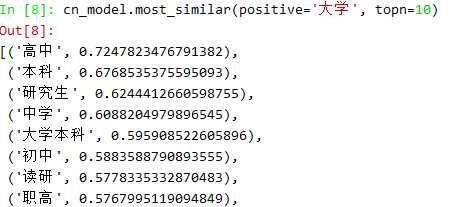
最相似的词:
准备一个训练集,4000个酒店评论,其中2000条为pos积极的,2000条为消极的,每条评论放在一个文件中。
end
标签:流程 一个 mode 中文 分享 orm alt 自然语言处理 port
原文地址:https://www.cnblogs.com/zhuxiang1633/p/10331618.html