标签:style blog http io 使用 ar strong sp 文件
OpenTSDB 2.0, the scalable, distributed time series database可扩展、分布式时间序列数据库
一些老的监控系统,它常常会出现这样的问题:
1)中心化数据存储进而导致单点故障。
2)有限的存储空间。
3)数据会因为时间问题而变得不准确。
4)不易于定制图形。
5)不能扩展采集数据点到100亿级别。
6)不能扩展metrics到K级别。
7)不支持秒级别的数据。
OpenTSDB解决上面的问题:
1、它用hbase存储所有的时序(无须采样)来构建一个分布式、可伸缩的时间序列数据库。
2、它支持秒级数据采集所有metrics,支持永久存储,可以做容量规划,并很容易的接入到现有的报警系统里。
3、OpenTSDB可以从大规模的集群(包括集群中的网络设备、操作系统、应用程序)中获取相应的metrics并进行存储、索引以及服务
从而使得这些数据更容易让人理解,如web化,图形化等。
对于运维工程师而言,OpenTSDB可以获取基础设施和服务的实时状态信息,展示集群的各种软硬件错误,性能变化以及性能瓶颈。
对于管理者而言,OpenTSDB可以衡量系统的SLA,理解复杂系统间的相互作用,展示资源消耗情况。集群的整体作业情况,可以用以辅助预算和集群资源协调。
对于开发者而言,OpenTSDB可以展示集群的主要性能瓶颈,经常出现的错误,从而可以着力重点解决重要问题。
openTSDB使用hbase作为存储中心,它无须采样,可以完整的收集和存储上亿的数据点,支持秒级别的数据监控,得益于hbase的分布式列式存储,hbase可以灵活的支持metrics的增加,可以支持上万机器和上亿数据点的采集。
在openTSDB中,TSD是hbase对外通信的daemon程序,没有master/slave之分,也没有共享状态,因此利用这点和hbase集群的特点就可以消除单点。用户可以通过telnet或者http协议直接访问TSD接口,也可以通过rpc访问TSD。每一个需要获取metrics的Servers都需要设置一个Collector用来收集时间序列数据。这个Collector就是你收集数据的脚本。
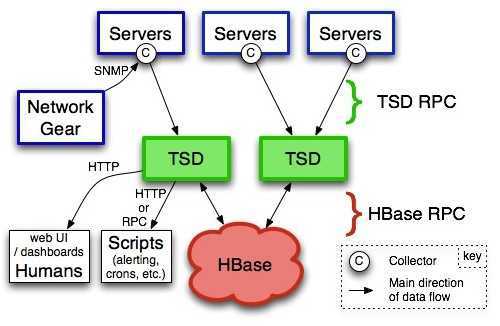 图1、openTSDB的数据流图
图1、openTSDB的数据流图
如果想快速地展示mysql中在一段时间内执行delete子句的数量,慢查询的数量,创建的临时文件数量以及99%的延迟数量等等。OpenTSDB则可以非常容易存储和处理百万级别以上的数据点,并能实时动态的生成对应的图,如图2.
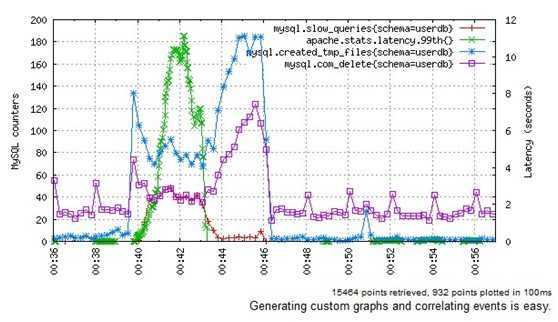
图2、OpenTSDB用例图
OpenTSDB使用async hbase ,这是个完全异步、非阻塞、线程安全、HBase api,使用更少的线程、锁以及内存可以提供更高的吞吐量,特别对于大量的写操作。
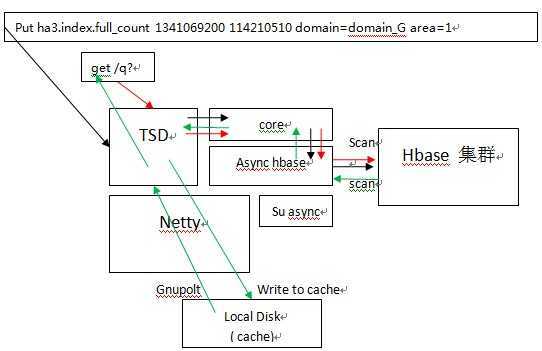
图3为读写流程
黑色的线表示写入,红色的线表示读取,通过get请求,绿色的呢,Gnuplot是画图吗??
在hbase中,表结构的设计对性能具有很大的影响,其中tsdb-uid表和tsdb表见表一和表二
tsdb-uid表
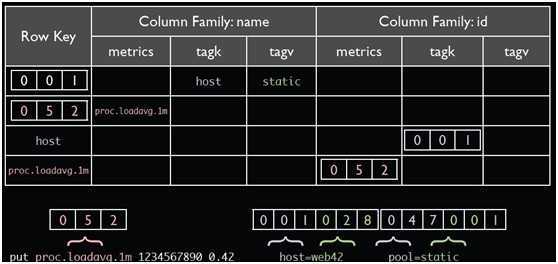
tsdb表
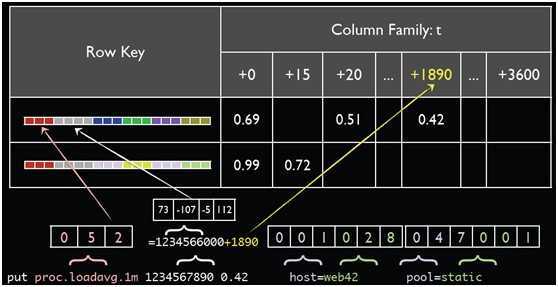
OpenTSDB,一个数据点可以表示为:1)一个指标名称。2)UNIX时间戳。3)一个值(64位整数或双精度浮点值)。4)标识这个数据点的一组标记tags(键-值对)。
如tcollector中的dfstat.py脚本的输出:
df.bytes.total 1413306095 4159016960 mount=/ fstype=ext3
一淘的例子:
下面四个数据点都是采集的metrics为index.full_count,代表引擎索引doc数;标记tags为来自哪个domain(代表机房),area和app代表应用,cluster代表索引表,partition代表列。Metrics和tags加起来就是一个时间序列。
index.full_count 1341069600 156866750 domain=domain_E area=1 app=jqb cluster=epid partition=partition_16384_32767 index.full_count 1341069600 155819640 domain=domain_E area=1 app=jqb cluster=epid partition=partition_32768_49151 index.full_size 1341069000 18561 domain=domain_D area=1 app=jqb cluster=b2c partition=partition_0_16383 index.full_size 1341069000 18554 domain=domain_D area=1 app=jqb cluster=b2c partition=partition_16384_32767 index.full_count 1341069200 11421051 domain=domain_G area=1 app=jqb cluster=b2c partition=partition_16384_32767
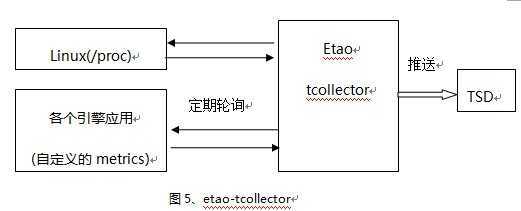
那如何收集这些数据呢,Etao在tcollector开源收集器的基础上,做第二次开发,见图5。
tcollector可以完成:
1)可以任意添加你的收集脚本程序,并收集所有数据。
2)完成发送数据到TSD的所有连接管理。
3)初始化一些状态,执行一些公共的部分,比如定时管理执行1min文件夹下面的脚本。
4)删除重复的数据。
5)支持很多种数据交换协议,提供良好的扩展性。
将etao-tcollector部署在所有机器上(可采用集中运维脚本进行远程部署,并可通过该系统远程控制收集器的启停)。etao-tcollector会将带时间和metrics的时间序列数据发送到tsd,之后的处理见第三节的图3,最后我们在Opentsdb提供的web UI上通过指定查询条件进行查询获取相应的图形用来对应用进行监控。
该etao-tcollector在一淘引擎中用来收集索引相关信息,引擎服务状态如延迟,日志等。
openTSDB采用hbase作为时序数据的存储中心,具有高扩展性,metrics添加相当灵活,且对数据可以无损的存储。可以很灵活的支持数据分析,图形显示以及一系列定制化操作,非常方便运维人员做运维监控。
1、http://www.searchtb.com/2012/07/opentsdb-monitoring-system.html
2、http://opentsdb.net/docs/build/html/index.html
3、https://github.com/stumbleupon/asynchbase
4、https://github.com/stumbleupon/tcollector
标签:style blog http io 使用 ar strong sp 文件
原文地址:http://www.cnblogs.com/gsblog/p/4029894.html