标签:记录 表结构 根据 目标 特征 知识 条件 有序 相对
最近朋友问了我一个问题:怎样将2000万数据从一个mysql数据库A1的表B实时累加同步到另外一个mysql库A2表B?
这个问题我没遇到过,因此根据自己查看掌握的sql进行了这方面的性能测试,并且积累记录了sql优化的一些基础知识.
前提条件:以上说的库表A1与A2的表结构都一摸一样,两张表的主键为ID,具有自动递增属性.
同步思路很简单,如下:
第一步:创建源库A1与目标库A2的连接,对应的连接分别为源库连接a1conn与目标库连接a2conn.
第二步:通过目标库a2conn查询获取到A2库中B表的最大ID号sourcemaxid.
第三步:通过目标库a1conn查询获取到A1库中B表的最大ID号targetmaxid.
第四步:根据sourcemaxid与localmaxid的差值recordcount取得每次实时同步多少条(此处已经做了差值非负判断,因为可能存在他人动表,
源的数据被删除或者目标库表数据新增的问题,因此同步的时候后).
第五步:怎样去从recordcount条数据中去查询取数据呢? 我用了以下两个方法,对比发现,差距很大.
第一种方法:sql为select * from 源表B order by 源表id limit localmaxid,250; ----该sql每次取300后同步成功后,localmaxid值加250.
该sql的执行耗时:
第一次: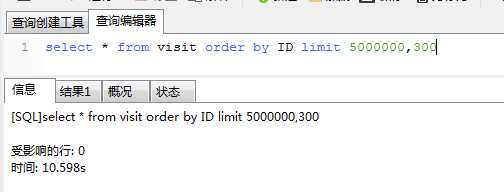
第二次: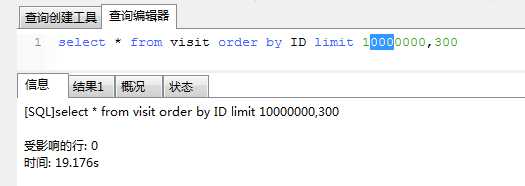
第三次: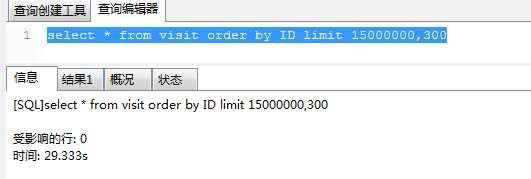
第二种方法: sql为select * from 源表B where ID>localmaxid order by ID limit 250;---------该sql每次取300后同步成功后,localmaxid值加300.
第一次: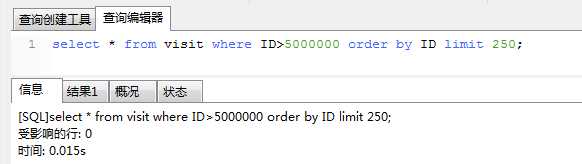
第二次: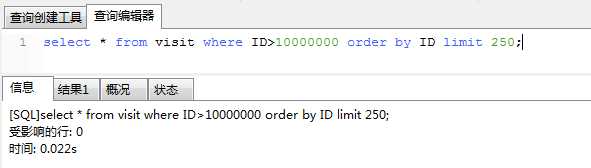
第三次: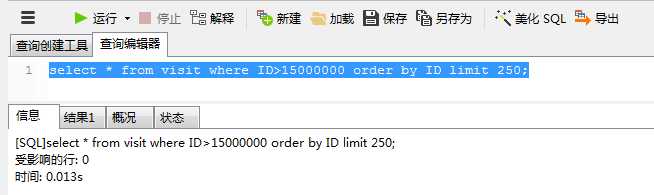
对以上两种不同的同步sql的执行的时间消耗进行对比,发现后者远远耗时远远小于前者,这是什么原因?原因如下,接下来也将开始我的sql优化之旅.
从第一种三次运行效果看localmaxid越大,耗时越长,要想知道原因,必须清楚limit分页操作是如何运行的.
LIMIT 子句用于强制 SELECT 语句返回指定的记录数.LIMIT 接受一个或两个数字参数,参数必须是一个整数常量.如果给定两个参数,第一个参数指定
第一个返回记录行的偏移量(offset),第二个参数指定返回记录行的最大数目(length).初始记录行的偏移量是 0(而不是 1) ,以上的localmaxid就是limit偏移量.
sql执行的逻辑:
1.从数据表中读取第N条数据添加到数据集中(N的取值范围为1到localmaxid+250)
2.重复第一步直到N从1变为localmaxid+250,也就是这样的动作重复了localmaxid+250次.
3.根据localmaxid(offset)抛弃数据集中的前面localmaxid(offset)条数据.
4.返回剩余的250(length)条数据.
从以上三步可以看出,sql的耗时主要在第二步,因为第二步获取多余的localmaxid条数据对本次查询无任何意义,但却占据了大部分的查询时间.
具体原因如下:
首先,数据库的数据存储并不是像我们想象中那样,按表顺序存储数据,按表按顺序存储数据,一方面是因为计算机存储本身就是随机读写,另一方
面是因为数据的操作有很大的随机性,即使一开始数据的存储是有序的,经过一系列的增删查改之后也会变得凌乱不堪. 所以数据库的数据存储
是随机的,使用 B+Tree,Hash 等方式组织索引. 所以当你让数据库读取第5000001 条数据的时候,数据库就只能一条一条的去查去数.
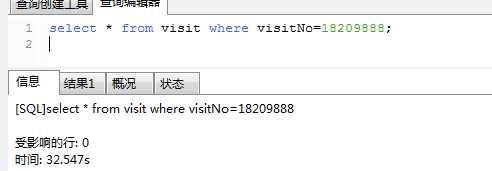
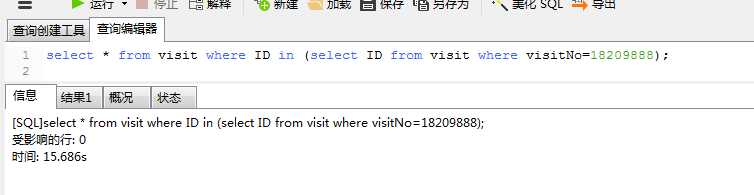

sql2中的子查询只取到了索引列,没有取实际的数据,所以不涉及到磁盘IO,利用子查询的方式,把原来的基于visitNo的搜索转化为
基于主键(id)的搜索,主查询因为已经获得了准确的索引值,所以查询过程也相对较快,将sql2中的in替换为sql3中的内关联inner join,效果更好点.
再补充:对visit表中的visitNo字段创建索引:create index index_visitNo on visit (visitNo),再次执行sql1,执行效果如下:
从执行结果可以看出:当给筛选字段visitNo添加索引之后,查询速率就是微秒级,可见索引的魅力.
标签:记录 表结构 根据 目标 特征 知识 条件 有序 相对
原文地址:https://www.cnblogs.com/renwujie/p/10331423.html