标签:区分 上海 argv you 超出 运算 input 返回值 技巧
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 装饰器 5 # 在不改变函数原本调用方式的基础上添加一些功能 6 # @装饰器名 7 # 如何写一个装饰器 8 # 例子 9 # 计算函数执行时间 10 # 用户认证 11 # 给函数添加日志 12 # def wrapper(func): 13 # def inner(*args,**kwargs): 14 # ‘‘‘在被装饰的函数之前添加功能‘‘‘ 15 # ret = func(*args,**kwargs) 16 # ‘‘‘在被装饰的函数之后添加功能‘‘‘ 17 # return ret 18 # return inner 19 # 20 # @wrapper 21 # def f(): 22 # print(‘in f‘) 23 # f() 24 25 26 # 多个装饰器装饰一个函数 27 # def wrapper1(func): 28 # def inner(*args,**kwargs): 29 # print(‘wrapper1 before‘) 30 # ret = func(*args,**kwargs) 31 # print(‘wrapper1 after‘) 32 # return ret 33 # return inner 34 # 35 # def wrapper2(func): 36 # def inner(*args,**kwargs): 37 # print(‘wrapper2 before‘) 38 # ret = func(*args,**kwargs) 39 # print(‘wrapper2 after‘) 40 # return ret 41 # return inner 42 # 43 # @wrapper2 #wrapeer2 装饰 wrapper1 44 # @wrapper1 #wrapper1 装饰 f 45 # def f(): 46 # print(‘in f‘) 47 # f() 48 49 # 考题 50 # 两个装饰器装饰一个函数,统计func函数的执行时间 51 # 登录 -- 装饰器 auth 52 # 计算函数的执行时间 -- 装饰器 timmer 53 # 54 # @auth 55 # @timmer 56 # def func() 57 58 59 # 带参数的装饰器 60 # flag = False 61 # def outer(flag): 62 # def timmer(func): 63 # def inner(*args,**kwargs): 64 # if flag: 65 # print(‘wrapper1 before‘) 66 # ret = func(*args,**kwargs) 67 # print(‘wrapper1 after‘) 68 # else: 69 # ret = func(*args, **kwargs) 70 # return ret 71 # return inner 72 # return timmer 73 # 74 # @outer(flag) # 把这里拆分成@ 和outer(flag)看。先看outer(flag),他就等于timmer 。然后 @outer(flag) = @timmer 75 # def f1(): 76 # print(‘in f1‘) 77 # 78 # @outer(flag) 79 # def f2(): 80 # print(‘in f2‘) 81 # 82 # @outer(flag) 83 # def f500(): 84 # print(‘in f500‘) 85 # 86 # f1() 87 # f2() 88 # f500() 89 90 91 # 迭代器和生成器 92 93 # 可迭代对象 : list str range 94 # 可以通过 for/iter 方法将一个可迭代对象转换成一个迭代器 , 95 96 # 迭代器 : 文件句柄 97 # 使用迭代器 : 节省内存,迭代器一项一项的取 98 99 # 生成器 100 # 我们自己写的迭代器 101 # 生成器的本质就是迭代器,所有的生成器都是迭代器 102 # 实现生成器的方法 : 103 # 生成器函数 :一定带yield关键字 g = func() 104 # 生成器表达式 : 用小括号表示的推导式 105 # 生成器的特点: 106 # 1.可以用next/send方法从中取值 107 # 2.生成器中的数据只能从头到尾取一次 *** 108 # 3.惰性运算 :不取生成器是不工作的 *** 109 110 # 考题 111 # def demo(): 112 # for i in range(4): 113 # yield i 114 # g = demo() 115 # 116 # g2 = (i for i in g) 117 # g1 = (i for i in g) 118 # 119 # print(list(g1)) # [0,1,2,3] # 这一步才开始从g1中取值 120 # print(list(g2)) # [] 121 122 123 # 列表推导式(排序) 124 # [i**2 for i in lst] 125 # [i**2 for i in lst if i%2 ==0] 126 # 生成器表达式(不能排序) 127 # (i**2 for i in lst) 128 # (i**2 for i in lst if i%2 ==0) 129 130 131 # 匿名函数 132 # lambda 参数1,参数2,参数3 : 返回值/返回值相关的表达式 133 134 # 内置函数 135 # min max map filter sorted 单记,可以和 lambda 连用。考点 用匿名函数实现某些功能的时候 136 # reduce --> functool 2.7中,3.x放到functool中去了 137 # zip sum enumerate 138 139 # min max 140 # l1 = [(‘a‘,3), (‘b‘,2), (‘c‘,1)] 141 # # def func(x): 142 # # return x[1] 143 # # ret = min(l1,key=func) # 注意这里 min 会先把l2列表中的每个元素传递到func函数中去,然后在取最小的 144 # # print(ret) 145 # # 改成lambda 146 # ret = min(l1,key=lambda x : x[1]) 147 # print(ret) 148 149 # filter 函数用于过滤序列。过滤掉不符合条件的元素,返回一个迭代器对象 150 # 该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判 151 # 然后返回 True 或 False,最后将返回 True 的元素放到新列表中 152 # l1 = [1,2,3,4,5,6,7,8,9,10,] 153 # def is_odd(n): 154 # return n % 2 == 1 155 # g = filter(is_odd, l1) 156 # for i in g: 157 # print(i) 158 159 # sorted 排序 160 # l1 = [1,2,8,7,5] 161 # print(sorted(l1)) 162 # l2 = [(‘c‘,2),(‘b‘,3),(‘a‘,1)] 163 # print( sorted(l2, key=lambda x:x[1]) ) # 这个和 min max 有点类似 164 165 # zip 拉链方法,会以最短的那个列表或其他的 去组合。生成一个迭代器 166 # l1 = [1,2,3,4] 167 # tu1 = (‘a‘,‘b‘,‘c‘) 168 # g = zip(l1,tu1) 169 # print(next(g)) 170 # print(next(g)) 171 # print(next(g)) 172 # 双排拉链方法 173 # l1 = [1,2,3,4] 174 # tu1 = (‘a‘,‘b‘,‘c‘) 175 # tu2 = (‘a1‘,‘b1‘,‘c1‘) 176 # g1 = zip(l1,tu1,tu2) # 也可以多个元素组合 177 # for i in g1: 178 # print(i) 179 180 # enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标, 181 # 一般用在 for 循环当中。 182 # l1 = [‘a‘,‘b‘,‘c‘,‘d‘] 183 # for index,i in enumerate(l1): 184 # print(index,i)
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 为什么要有模块?(内置函数不够用) 5 # 和操作系统打交道 6 # 和python解释器打交道 7 # 和时间打交道 8 # 如何利用python发邮件 9 # 如何利用python图像识别 10 11 # 都是完成好的功能 12 # 可以被封装成函数 13 # 可以成为内置的函数 14 # 占用内存空间 15 16 # 整理分类,把相同的功能放在一个文件中 17 # 我们在开发的过程中,用到哪个功能直接导入使用就可以了 18 # 不使用的功能不会进入内存占用不必要的空间 19 # 使用的功能我们可以自由的选择 20 21 # 模块的本质 22 # 就是封装了很多很多函数、功能的一个文件 23 24 # 导入模块 就是 import 25 26 # 模块的分类 27 # 内置模块 不需要我们进行额外的安装、随着解释器的安装直接就可以使用的模块 28 # 扩展模块/第三方模块 我们安装了python解释器之后 如果要使用这些模块还要单独安装 29 # https://pypi.org/ 30 # 豆瓣的 python源 31 # 自定义模块 32 # 自己写的模块
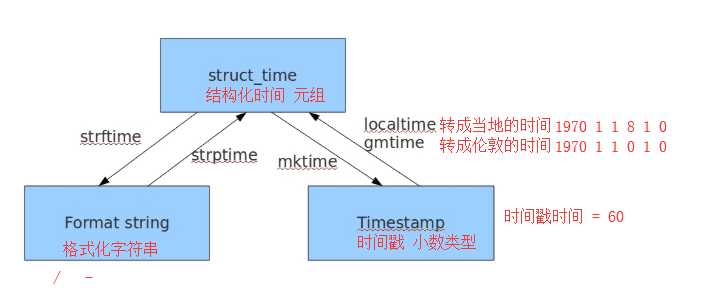
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 和时间打交道的模块 5 import time 6 7 # 1.时间戳时间 time.time() 8 # print(time.time()) 9 # 1548645816.011941 时间戳格式 10 # float 小数 11 # 为什么时间要用这种格式(1548558746.5218766)表示? 12 # 是给计算机看的 13 # ‘2019/1/27 11:13‘ 14 # 1970 1 1 0:0:0 英国伦敦的时间 0时区 15 # 1970 1 1 8:0:0 北京的时间 东8区 16 17 18 # 2.格式化时间 time.strftime(‘%Y-%m-%d %H:%M:%S‘) 19 # t1 = time.strftime(‘%Y-%m-%d %H:%M:%S‘) 20 # t1 = time.strftime(‘%Y+%m+%d %H:%M:%S %a‘) 21 # t1 = time.strftime(‘%Y+%m+%d %H:%M:%S %A %b %B‘) 22 # t1 = time.strftime(‘%y+%m+%d %H:%M:%S %A %b %B‘) 23 # t1 = time.strftime(‘%c‘) 24 # print(t1) 25 26 27 # 3.结构化时间(时间元组) time.localtime() 28 # print(time.localtime()) 29 # tm_year=2019 --- 年 30 # tm_mon=1 ---月 31 # tm_mday=28, ---日 32 # tm_hour=11, ---时 33 # tm_min=33, ---分 34 # tm_sec=1, ---秒 35 # tm_wday=0, --- 一周的第几天,星期一为0 36 # tm_yday=28, --- 一年的第几天 37 # tm_isdst=0 --- 是否是夏令时,默认不是 38 39 40 # 转换只能通过结构化时间进行转换 :时间戳格式 <---> 结构化时间 <---> 格式化时间 41 # 1548558746.5218766 ‘2019/1/27 11:13‘ 42 # 计算机能看懂的 (为了进行数据转换) 人能看懂的 43 # 时间戳时间 结构化时间 格式化时间 44 # time.time() time.localtime() time.strftime(‘%Y-%m-%d %H:%M:%S‘) 45 46 47 # 举例1 48 # 格式化时间 2018-8-8 ---> 时间戳时间 49 # 先把格式化时间 转化成 元组时间 50 # str_time = ‘2018-8-8‘ 51 # struct_time = time.strptime(str_time, ‘%Y-%m-%d‘) 52 # print(struct_time) 53 # # 在转化成时间戳 54 # stamp_time = time.mktime(struct_time) 55 # print(stamp_time) 56 57 # 举例2 58 # 2000000000 转化为格式化时间 59 # stamp_t = 2000000000 60 # # 先把时间戳时间转化为元组时间 61 # struct_t = time.localtime(stamp_t) 62 # print(struct_t) 63 # # 再把元组时间转为格式化时间 64 # strftime_t = time.strftime(‘%Y-%m-%d %H:%M:%S‘, struct_t) 65 # print(strftime_t) 66 67 # 小练习1 68 # 拿到本月时间1号的时间戳时间 69 # strftime_t = time.strftime(‘%Y-%m‘) 70 # print(strftime_t) 71 # struct_t = time.strptime(strftime_t, ‘%Y-%m‘) 72 # print(struct_t) 73 # stamp_t = time.mktime(struct_t) 74 # print(stamp_t) 75 76 # 小练习2 77 # ‘2017-09-11 08:30:00‘ ‘2017-09-12 11:00:00‘ 计算这两个时间段的时间差 78 # 先把格式化时间--->元组时间 79 # t1 = time.mktime(time.strptime(‘2017-09-11 08:30:00‘, ‘%Y-%m-%d %H:%M:%S‘)) 80 # t2 = time.mktime(time.strptime(‘2018-09-13 08:30:10‘, ‘%Y-%m-%d %H:%M:%S‘)) 81 # ret = t2 - t1 82 # struct_t = time.gmtime(ret) 83 # print(struct_t) 84 # print(‘过去了%d年%d月%d天%d小时%d分钟%d秒‘%(struct_t.tm_year-1970,struct_t.tm_mon-1, 85 # struct_t.tm_mday-1,struct_t.tm_hour, 86 # struct_t.tm_min,struct_t.tm_sec))
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 import random 4 # 和随机相关的内容 random模块 5 6 # # 随机小数 7 # print(random.random()) #(0,1) 8 # print(random.uniform(1,2)) #(n,m) 9 10 # 随机整数 11 # print(random.randint(1,2)) # [1,2] 包含了2 12 # print(random.randrange(1,2)) # [1,2) 不包含2 13 # print(random.randrange(1,5,2)) # 不长为2 14 15 # 随机从一个列表中取一个值 16 # ret = random.choice([1, 2, 3, (‘k‘, ‘v‘), {‘name‘:‘alex‘}]) 17 # print(ret) 18 19 # 随机从一个列表中取2个值 20 # ret2 = random.sample([1, 2, 3, (‘k‘, ‘v‘), {‘name‘:‘alex‘}], 2) 21 # print(ret2) 22 23 # 打乱顺序 洗牌 24 # l1 = [1, 2, 3, 4, 5] 25 # random.shuffle(l1) 26 # print(l1) 27 28 # 验证码例子 29 # def my_code(n=6, flag=True): 30 # code = ‘‘ 31 # for i in range(n): 32 # num = random.randint(0, 9) 33 # # 注意这里的小技巧 34 # if flag: 35 # alp = chr(random.randint(65, 90)) 36 # num = random.choice([num, alp]) 37 # code += str(num) 38 # return code 39 # 40 # ret = my_code() 41 # print(ret) 42 43 44 # 红包例子 45 # 思路: 46 # 1.需要确定红包个数,红包总金额 47 # 2.最低金额为0.01元 48 # 3.每抽中一次,需要用红包当前总金额减去抽中的金额,然后在继续在该区间内随机抽取 49 # 4.最小金鹅为 50 # def hb(num, money): 51 # # 定义空列表用来存储抽奖金额 52 # lst = [] 53 # # 金额乘以100,便于计算,后续加入到列表在除以100 54 # money = money * 100 55 # # 判断传递参数的合法性 56 # if type(num) is int and num >=1 and (type(money) is int or type(money) is float): 57 # # for循环应该比num少一次,例如2个红包个数,for循环1次就可以 58 # for i in range(num-1): 59 # # 保证不出现抽中0元的现象 60 # p = random.randint(1, money-1*(num-1)) 61 # lst.append(p/100) 62 # # 需要减去已经抽取的红包金额 63 # money = money - p 64 # # 这里的意思是没抽一次,没抽过的人减少1 65 # num -= 1 66 # else: 67 # # 循环结束了,把剩余的红包总金额放入到一个红包内 68 # lst.append(money/100) 69 # return lst 70 # else: 71 # print(‘参数有误!‘) 72 # 73 # ret = hb(1,1.1) 74 # print(ret)
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 # import os 4 # os和操作系统打交道的 5 6 # 和文件、文件夹相关的 7 # os.makedirs(‘dirname1/dirname2‘) # 可生成多层递归目录 8 # os.removedirs(‘dirname1/dirname2‘) # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 9 # os.mkdir(‘dirname‘) # 生成单级目录;相当于shell中mkdir dirname 10 # os.rmdir(‘dirname‘) # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 11 # ret = os.listdir(r‘E:\python3周末班2期笔记\05 day05\03 笔记整理‘) 12 # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 13 # print(ret) 14 # os.remove(‘test.py‘) # 删除一个文件 15 # os.rename("test.py","test2.py") # 重命名文件/目录 16 # ret = os.stat(r‘E:\python3周末班2期笔记\05 day05\03 笔记整理‘) # 获取文件/目录信息 17 # print(ret) 18 19 20 # 和执行系统命令相关 21 # os.system("dir") # 运行shell命令,直接显示 22 # ret = os.popen(‘dir‘).read() # 运行shell命令,获取执行结果 23 # print(ret) 24 # ret = os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径 25 # print(ret) 26 # os.chdir(r"E:\python3周末班2期笔记") # 改变当前脚本工作目录;相当于shell下cd 27 # ret = os.getcwd() 28 # print(ret) 29 # 所谓工作目录 文件在哪个目录下运行 工作目录就是哪里 30 # 和这个文件本身所在的路径没有关系 31 # 1.工作目录与文件所在位置无关 32 # 2.工作目录和所有程序中用到的相对目录都相关 33 34 # 和路径相关的 35 # os.path 36 # ret = os.path.abspath(__file__) # 返回path规范化的绝对路径 37 # print(ret) 38 # ret = os.path.split(__file__) # 将path分割成目录和文件名二元组返回 39 # print(ret) 40 # os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素 41 # os.path.basename(path) # 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 42 # ret = os.path.exists(r‘E:\python‘) # 如果path存在,返回True;如果path不存在,返回False 43 # print(ret) 44 # ret = os.path.isabs(‘E:\python3周末班2期笔记\05 day05\03 笔记整理‘) # 如果path是绝对路径,返回True 45 # print(ret) 46 # ret = os.path.isfile(‘E:\python3周末班2期笔记\05 day05\03 笔记整理‘) # 如果path是一个存在的文件,返回True。否则返回False 47 # print(ret) 48 # ret = os.path.isdir(‘E:\python3周末班2期笔记‘) # 如果path是一个存在的目录,则返回True。否则返回False 49 # print(ret) 50 # ret = os.path.join(‘E:\python3周末班2期笔记‘, ‘abc‘, ‘def‘) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 51 # print(ret) 52 # os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 53 # os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 54 # ret = os.path.getsize(r‘E:\python3周末班2期笔记\05 day05\03 笔记整理\00 今日课程大纲.py‘) 55 # 返回path的大小,文件夹的大小不准确 56 # print(ret) 57 58 59 # 练习题 60 # 使用python代码 计算文件夹的大小 61 # 这个文件夹里可能还有文件夹 62 # import os 63 # total_size=0 64 # def file_size(path): 65 # global total_size 66 # path=os.path.abspath(path) 67 # print(‘path‘,path) 68 # file_list=os.listdir(path) 69 # print(‘list‘,file_list) 70 # for i in file_list: 71 # i_path = os.path.join(path, i) 72 # if os.path.isfile(i_path): 73 # total_size += os.path.getsize(i_path) 74 # else: 75 # try: 76 # file_size(i_path) 77 # except RecursionError: 78 # print(‘递归操作时超出最大界限‘) 79 # return total_size 80 # 81 # print(file_size(r‘E:\02‘))
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 import sys 5 # sys模块是和 python解释器打交道的 6 7 # sys.exit() # 退出 8 # print(123) 9 # print(sys.version) # 版本 10 # print(sys.platform) # 平台 操作系统 11 12 # print(sys.path) # 模块搜索路径 13 # 包含的内容 14 # 1.内置的python安装的时候就规定好的一些内置模块所在的路径 15 # 内置模块 16 # 扩展模块 17 # 2.当前被执行的文件所在的路径 18 # 自定义的模块 19 20 # 需要在CMD执行 21 # python py文件的目录 参数1 参数2 22 # print(sys.argv) # [] 23 # if sys.argv[1] == ‘alex‘ and sys.argv[2] == ‘alexsb‘: 24 # print(‘登陆成功‘) 25 # else: 26 # print(‘登陆失败‘) 27 # sys.exit() 28 # print(‘登陆成功后的所有代码‘)
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 序列化模块 5 # 序列化 6 # 序列 : list str tuple bytes 7 # 可迭代的都是序列? 字典?集合?无序的,散列。不是序列 8 # 狭义的序列 :str / bytes 9 # 序列化?把。。。变得有序,把。。。变成str或者是bytes 10 # 反序列化?把str/bytes 还原回原来的 。。。 11 12 # 为什么要有序列化? 13 # 1.存储在文件中 长久保存到硬盘 14 # 2.在网络上传递,只能用字节 15 16 # 序列化模块 17 import json 18 # 能够支持所有的计算机高级语言 19 # 对数据类型的要求非常严格 20 # dic = {"key":"value"} 21 # ret = json.dumps(dic) # 序列化方法 22 # print(dic,type(dic)) 23 # print(ret,type(ret)) 24 # with open(‘json_file‘,‘w‘) as f: 25 # f.write(ret) 26 27 # with open(‘json_file‘) as f: 28 # content = f.read() 29 # d = json.loads(content) # 反序列化方法 30 # print(d) 31 # print(d[‘key‘]) 32 33 # 坑1:json格式规定所有的key必须是字符串数据类型 34 # dic = {1:2} 35 # ret = json.dumps(dic) 36 # print(dic[1]) 37 # print(ret) 38 # new_dic = json.loads(ret) 39 # print(new_dic) 40 41 # 坑2 : json中的所有tuple都会被当作list处理 42 # dic = {1:(1,2,3)} 43 # ret = json.dumps(dic) 44 # print(ret) 45 # new_dic = json.loads(ret) 46 # print(new_dic) 47 48 # dic = {(1,2):(1,2,3)} 49 # ret = json.dumps(dic) 50 # print(ret) 51 # new_dic = json.loads(ret) 52 # print(new_dic) 53 54 # 特性3: json能支持的数据类型非常有限,字符串 数字 列表 字典 55 56 57 # dumps loads 字符串 和 其他基础数据类型之间转换 58 # dump load 文件 和 其他基础数据类型之间转换 59 # 60 # dump load 61 # dic = {"key":"value"} 62 # with open(‘json_file2‘,‘w‘) as f: 63 # json.dump(dic,f) 64 # 65 # with open(‘json_file2‘) as f: 66 # ret = json.load(f) 67 # print(ret[‘key‘]) 68 69 70 # json不可以dump多次 71 # dic = {"key":"value"} 72 # with open(‘json_file2‘,‘w‘) as f: 73 # json.dump(dic,f) 74 # json.dump(dic,f) 75 # 76 # with open(‘json_file2‘, ‘r‘) as f: 77 # ret = json.load(f) 78 79 80 # 如果需要dump多次,按照下面的方法 81 # str_dic = {"name": "alex","sex":None} 82 # ret = json.dumps(str_dic) 83 # with open(‘json_file2‘,‘w‘) as f: 84 # f.write(ret+‘\n‘) 85 # f.write(ret+‘\n‘) 86 # 87 # with open(‘json_file2‘, ‘r‘) as f: 88 # for line in f: 89 # print(json.loads(line), type(json.loads(line)))
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 import pickle 5 6 # 1.支持几乎所有python中的数据类型 7 # 2.只在python语言中通用 8 # 3.pickle适合bytes类型打交道的 9 # s = {1,2,3,4} 10 # ret = pickle.dumps(s) 11 # print(ret) 12 # 13 # ret2 = pickle.loads(ret) 14 # print(ret2) 15 16 17 # pickle:序列化时候数据是什么类型,反序列化以后数据还是原来的类型,这点和 json 有点不一样 18 # d = {1:2,3:4} 19 # ret = pickle.dumps(d) 20 # print(ret) 21 # new_d = pickle.loads(ret) 22 # print(new_d) 23 # 24 # s = {(1,2,3):2,3:4} 25 # result = pickle.dumps(s) 26 # print(result) 27 # with open(‘pickle_file‘,‘wb‘) as f: 28 # f.write(result) 29 # 30 # with open(‘pickle_file‘,‘rb‘) as f: 31 # content = f.read() 32 # ret = pickle.loads(content) 33 # print(ret,type(ret)) 34 35 36 # pickle 可以支持多个对象放入文件 37 # pickle 可以dump多次,也可以load多次 38 # s1 = {1,2,3} 39 # s2 = {1:2,3:4} 40 # s3 = [‘k‘,‘v‘,(1,2,3),4] 41 # with open(‘pickle_file2‘,‘wb‘) as f: 42 # pickle.dump(s1,f) 43 # pickle.dump(s2,f) 44 # pickle.dump(s3,f) 45 # 46 # with open(‘pickle_file2‘,‘rb‘) as f: 47 # count = 1 48 # while count <= 3: 49 # try: 50 # content = pickle.load(f) 51 # print(content) 52 # count += 1 53 # except EOFError: 54 # break 55 56 57 # json ---实际上使用json更多。优先选择 58 # 如果你是要跨平台沟通,那么推荐使用json 59 # key只能是字符串 60 # 不能多次load和dump 61 # 支持的数据类型有限 62 63 # pickle 64 # 如果你是只在python程序之间传递消息,并且要传递的消息是比较特殊的数据类型 65 # 处理文件的时候 rb/wb 66 # 支持多次dump/load
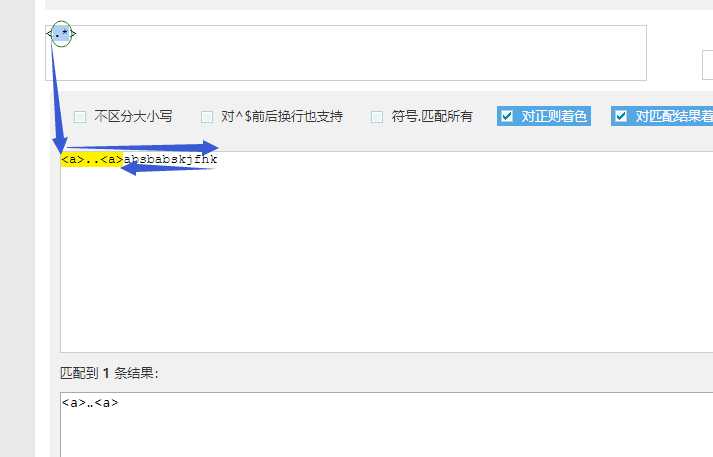
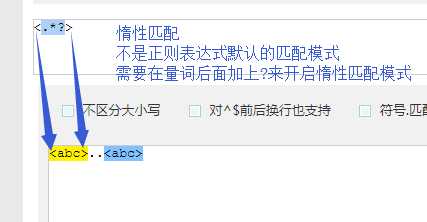
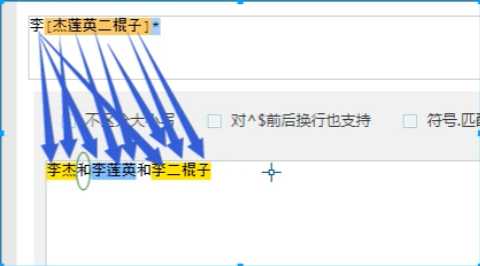
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 我们使用的模块和这个模块要完成的功能是分不开的 5 # re模块 :是用来在python中操作 正则表达式 的 6 # 要先知道正则表达式是什么?做什么用的?怎么用 7 8 # 正则表达式检测网站 9 # http://tool.chinaz.com/regex/ 10 11 # 邮箱地址 12 # 用户名 密码 13 # 要检测一个用户输入的内容是否符合我的规则 14 15 # 用户输入的内容对于程序员来说都是字符串 16 # 一个文件是一堆字符串,有很多内容 17 18 # 检测某一个字符串是否符合规则 -- 本质 -- 需求一 19 # 从一大段文字中找到符合规则的字符串 -- 需求二 20 21 # 正则表达式 --> 字符串规则匹配的 22 # 1.判断某一个字符串是否符合规则 23 # 2.从一段文字中提取出符合规则的内容 24 25 26 # 初识正则表达式 27 # 28 # 字符组的概念。 29 # [ ]表示字符组,一个[ ]表示一个字符组 30 # [1-9] 31 # [0-9] 32 # [1-5] 33 # [a-z] 34 # [a-f] 35 # 1.对字母来说 区分大小写 36 # 2.a-f可以 f-a不行 37 # 一个字符位置上可以出现的内容是匹配数字或字母:[0-9a-zA-Z] 38 # 匹配一个两位数:# [1-9][0-9] 39 40 41 # 元字符 42 # \d 数字 43 # \w 数字 字母 下划线 44 # \s 空格 回车 制表符 45 # \t 制表符 46 # \n 回车 47 # \b 匹配一个单词的边界。例如 hello world o\b会匹配hello的o 48 # 49 # \D 非数字 50 # \W 非数字字母下划线 51 # \S 非空白 52 53 54 # ^ 一个字符串的开始 55 # $ 一个字符串的结尾 56 # ^xxxx$ 约束的了整个字符串中的内容必须一一与表达式对应上 57 # 例如: hello hello hello 58 # ^hello 只能匹配第一个hello 59 # hello$ 只能匹配最后一个hello 60 # hello^ 不能匹配任何字符串。因为 ^ 是开头,没有可能在开头在出现字符。 61 62 # | 表示或 63 # 例子:匹配ab或abc 要这样写 abc|ab 把长的表达式写在前面 64 65 # () 分组 66 # # a(b|c)d 67 #例子:www.baidu.com www.baide.com 表达式 www.baid(u|e).com 68 69 # . 表示除了换行符以外的任意字符 70 71 # 非 字符组 72 # [^ABC] 只要不是ABC都能匹配 73 74 75 # 量词 76 # {n} 在这个量词前面的一个元字符出现n次 77 # {n,} 在这个量词前面的一个元字符出现n次或n次以上 78 # {n,m} 在这个量词前面的一个元字符出现n次到m次以上 79 # 80 # ? 在这个量词前面的一个元字符出现0次或者1次 81 # + 在这个量词前面的一个元字符出现1次或者多次 82 # * 在这个量词前面的一个元字符出现0次或者多次 83 # 84 # 例子: 85 # 1.匹配一个整数:\d+ 86 # 2.匹配一个小数:\d+\.\d+ 87 # 3.匹配整数或者小数: 表达式 \d+(\.\d+)? 括号里面的被量词?问号约束,约束了一组字符的出现次数 88 89 # 小练习 90 # 正则表达式默认都是贪婪匹配 91 # 贪婪匹配:会尽量多的帮我们匹配内容 92 # 例子 待匹配字符:李杰和李莲英和李二棍子 正则表达式:李.? 匹配结果:李杰 李莲 李二 匹配到这3条 93 94 # 回溯算法下的贪婪匹配 95 # 例子:待匹配字符:<a>bbbb<a> 正则表达式:<.*> 匹配结果:<a>bbbb<a> 96 97 # 非贪婪模式, 98 # 在量词后面加一个问号,开启非贪婪模式 99 # 惰性匹配:尽量少的匹配 100 # 例子:待匹配字符:<a>bbbb<a> 正则表达式:<.*?> 匹配结果:<a> <a> 这两条 101 102 # 例子 待匹配字符:李杰和李莲英和李二棍子 正则:李[杰莲英二棍子]* 匹配结果:李杰 李莲英 李二棍子 103 # 例子 待匹配字符:李杰和李莲英和李二棍子 正则:李[^和]* 匹配结果:李杰 李莲英 李二棍子 104 105 # 例子 106 # 身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部???数字组成,首位不能为0; 107 # 如果是18位,则前17位全部是数字,末位可能是数字或x 108 # ^[1-9]\d{14}(\d{2}[x\d])?$ 109 # ^([1-9]\d{16}[\dx]|[1-9]\d{14})$ 110 111 # 转义符例子 112 # r‘\\n‘ 匹配 ‘\n‘ 113 114 # .*?x :爬虫常用 ,表示匹配任意字符,直到遇见x停止 115 116 117 # 练习题 118 # 1、 匹配一段文本中的每行的邮箱 119 # http://blog.csdn.net/make164492212/article/details/51656638 120 # 121 # 2、 匹配一段文本中的每行的时间字符串,比如:‘1990-07-12’; 122 # 123 # 分别取出1年的12个月(^(0?[1-9]|1[0-2])$)、 124 # 一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$ 125 # 126 # 3、 匹配qq号。(腾讯QQ号从10000开始) [1,9][0,9]{4,} 127 # 128 # 4、 匹配一个浮点数。 ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d* 129 # 130 # 5、 匹配汉字。 ^[\u4e00-\u9fa5]{0,}$ 131 # 132 # 6、 匹配出所有整数
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 import re 4 5 # findall() 6 # ret = re.findall(‘\d+‘,‘h2b3123‘) # 匹配所有 7 # print(ret) 8 9 # search() 10 # ret = re.search(‘\d+‘,‘h2b3123‘) # 只匹配从左到右的第一个 11 # print(ret) # 变量 12 # print(ret.group()) 13 # 14 # ret = re.search(‘\d+‘,‘aaaab123‘) # 只匹配从左到右的第一个 15 # if ret: 16 # print(ret.group()) 17 18 # compile() # 节省时间 19 # ‘\d+‘ --> 正则规则 --> python代码 --> 将字符串按照代码执行匹配 20 # re.findall(‘\d+‘,‘ahkfgilWIVKJBDKvjgheo‘) 21 # re.findall(‘\d+‘,‘ahkfgilsk0194750dfjWIVKJBDKvjgheo‘) 22 # re.findall(‘\d+‘,‘ahkfgilsk0vv194750dfjWIVKJBDKvjgheo‘) 23 # 24 # ret = re.compile(‘\d+‘) 25 # ret.findall(‘ahkfgilWIVKJBDKvjgheo‘) 26 # ret.search(‘ahkfgilsk0194750dfjWIVKJBDKvjgheo‘) 27 # 28 # ret = re.finditer(‘\d+‘,‘dskh1040dsvk034fj048d3g5h4j‘) 29 # for r in ret: 30 # print(r.group()) 31 32 # search 33 # findall 34 # compile 节省时间 一条正则表达式用多次 35 # finditer 节省空间 结果的条数很多的时候 36 37 38 # ret = re.findall(‘www.(?:baidu|oldboy).com‘, ‘www.oldboy.com‘) 39 # print(ret) 40 # 分组遇到findall,优先显示分组中匹配到的内容 41 # 如何取消分组优先? ?: 42 43 44 # 练习题 45 # 匹配标签 46 # 47 # s = ‘<h1>abc</h1>‘ 48 # ret = re.search(‘<(\w+)>‘, s) 49 # print(ret.group()) 50 # 分组 51 # ret = re.search(‘<(\w+)>(.*?)<(/\w+)>‘,s) 52 # print(ret.group(1)) 53 # print(ret.group(2)) 54 # print(ret.group(3)) 55 56 57 # s = ‘<h1>abc</h1>‘ 58 # ret = re.search(‘<(?P<tag>\w+)>(.*?)<(/\w+)>‘,s) 59 # print(ret.group(‘tag‘)) 60 # s = ‘<h1>abc</h1>‘ 61 # ret = re.search(‘<(?P<tag>\w+)>(.*?)</(?P=tag)>‘,s) 62 # print(ret) 63 64 65 66 # 匹配标签 67 # ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") 68 # #还可以在分组中利用?<name>的形式给分组起名字 69 # #获取的匹配结果可以直接用group(‘名字‘)拿到对应的值 70 # print(ret.group(‘tag_name‘)) #结果 :h1 71 # print(ret.group()) #结果 :<h1>hello</h1> 72 # 73 # ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>") 74 # #如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致 75 # #获取的匹配结果可以直接用group(序号)拿到对应的值 76 # print(ret.group(1)) 77 # print(ret.group()) #结果 :<h1>hello</h1>
1 #!/usr/bin/env python3 2 #author:Alnk(李成果) 3 4 # 在讲今天的内容之前,我们先来讲一个故事,讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚讲故事, 5 # 讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么呢? 6 # 从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么呢? 7 # 从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么呢...... 8 # 这个故事你们不喊停我能讲一天! 9 # 我们说,生活中的例子也能被写成程序,刚刚这个故事,让你们写,你们怎么写呀? 10 # 11 # def story(): 12 # s = """ 13 # 从前有个山,山里有座庙,庙里老和尚讲故事, 14 # 讲的什么呢? 15 # """ 16 # print(s) 17 # story() 18 # story() 19 20 21 # 递归的定义——在一个函数里再调用这个函数本身 22 # 现在我们已经大概知道刚刚讲的story函数做了什么,就是在一个函数里再调用这个函数本身,这种魔性的使用函数的方式就叫做递归。 23 # 24 # 递归的最大深度——997 25 # def foo(n): 26 # print(n) 27 # n += 1 28 # foo(n) 29 # foo(1) 30 # 由此我们可以看出,未报错之前能看到的最大数字就是997.当然了 31 # 32 # 我们当然还可以通过一些手段去修改它 33 # import sys 34 # print(sys.setrecursionlimit(100000)) 35 # 我们可以通过这种方式来修改递归的最大深度,刚刚我们将python允许的递归深度设置为了10w 36 # 至于实际可以达到的深度就取决于计算机的性能了 37 # 不过我们还是不推荐修改这个默认的递归深度, 38 # 因为如果用997层递归都没有解决的问题要么是不适合使用递归来解决要么是你代码写的太烂 39 40 41 # 例一 42 # 现在你们问我,alex老师多大了?我说我不告诉你,但alex比 egon 大两岁。 43 # 你想知道alex多大,你是不是还得去问egon?egon说,我也不告诉你,但我比武sir大两岁。 44 # 你又问武sir,武sir也不告诉你,他说他比金鑫大两岁。 45 # 那你问金鑫,金鑫告诉你,他40了。。。 46 # 这个时候你是不是就知道了?alex多大? 47 # 48 # 1 金鑫 40 49 # 2 武sir 42 50 # 3 egon 44 51 # 4 alex 46 52 # 你为什么能知道的? 53 # 首先,你是不是问alex的年龄,结果又找到egon、武sir、金鑫,你挨个儿问过去, 54 # 一直到拿到一个确切的答案,然后顺着这条线再找回来, 55 # 才得到最终alex的年龄。这个过程已经非常接近递归的思想。我们就来具体的我分析一下,这几个人之间的规律 56 # 57 # age(4) = age(3) + 2 58 # age(3) = age(2) + 2 59 # age(2) = age(1) + 2 60 # age(1) = 40 61 # 函数应该怎么写呢 62 # def age(n): 63 # if n == 1: 64 # return 40 65 # else: 66 # return age(n-1)+2 67 # 68 # print(age(4)) 69 70 71 # 例二 72 # 递归函数与三级菜单 73 ‘‘‘ 74 menu = { 75 ‘北京‘: { 76 ‘海淀‘: { 77 ‘五道口‘: { 78 ‘soho‘: {}, 79 ‘网易‘: {}, 80 ‘google‘: {} 81 }, 82 ‘中关村‘: { 83 ‘爱奇艺‘: {}, 84 ‘汽车之家‘: {}, 85 ‘youku‘: {}, 86 }, 87 ‘上地‘: { 88 ‘百度‘: {}, 89 }, 90 }, 91 ‘昌平‘: { 92 ‘沙河‘: { 93 ‘老男孩‘: {}, 94 ‘北航‘: {}, 95 }, 96 ‘天通苑‘: {}, 97 ‘回龙观‘: {}, 98 }, 99 ‘朝阳‘: {}, 100 ‘东城‘: {}, 101 }, 102 ‘上海‘: { 103 ‘闵行‘: { 104 "人民广场": { 105 ‘炸鸡店‘: {} 106 } 107 }, 108 ‘闸北‘: { 109 ‘火车战‘: { 110 ‘携程‘: {} 111 } 112 }, 113 ‘浦东‘: {}, 114 }, 115 ‘山东‘: {}, 116 } 117 ‘‘‘ 118 119 # def digui(dic): 120 # while 1: 121 # for k in dic: 122 # print(k) 123 # choice = input(‘>>>:‘).strip() 124 # 125 # if choice == ‘b‘ or choice ==‘q‘: 126 # return choice 127 # 128 # elif dic.get(choice): 129 # ret = digui(dic[choice]) 130 # if ret == ‘q‘: 131 # return 132 # 133 # digui(menu)
标签:区分 上海 argv you 超出 运算 input 返回值 技巧
原文地址:https://www.cnblogs.com/lichengguo/p/10335100.html