反向传播算法是用来求那个复杂到爆的梯度的。
上一集中提到一点,13000维的梯度向量是难以想象的。换个思路,梯度向量每一项的大小,是在说代价函数对每个参数有多敏感。
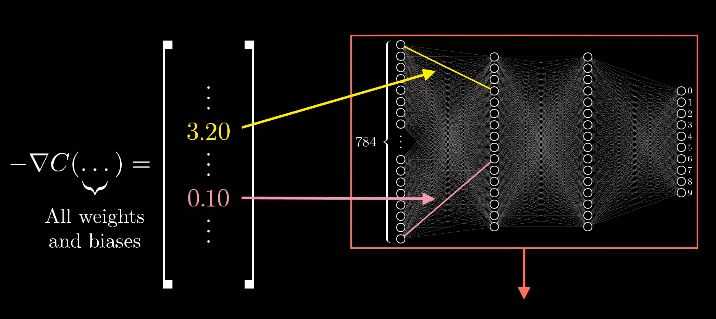
如上图,我们可以这样里理解,第一个权重对代价函数的影响是是第二个的32倍。
我们来考虑一个还没有被训练好的网络。我们并不能直接改动这些激活值,只能改变权重和偏置值。但记住,我们想要输出层出现怎样的变动,还是有用的。

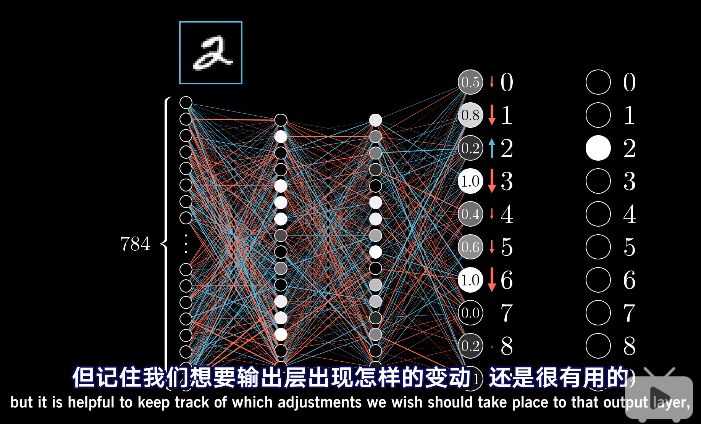
我们希望图像的最后分类结果是2,我们期望第3个输出值变大,其余输出值变小,并且变动的大小应该与现在值和目标值之间的差成正比。举个例子,增大数字2神经元的激活值,就应该‘比减少数字8神经元的激活值来得重要,因为后者已经很接近它的目标了。
进一步,就来关注数字2这个神经元,想让它的激活值变大,而这个激活值是把前一层所有激活值的加权和加上偏置值。

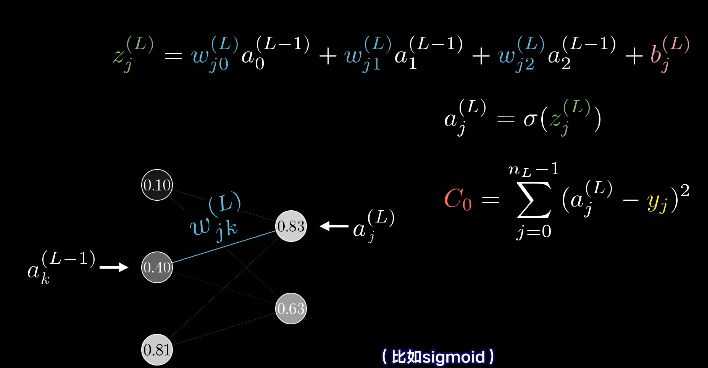
所以要增加激活值,我们有3条路可以走,一增加偏置,二增加权重,或者三改变上一层的激活值。
先来看如何调整权重,各个权重它们的影响力各不相同,连接前一层最亮的神经元的权重,影响力也最大,因为这些权重与大的激活值相乘。增大这几个权重,对最终代价函数造成的影响,就比增大连接黯淡神经元的权重所造成的影响,要大上好多倍。
请记住,说到梯度下降的时候,我们并不只看每个参数是增大还是变小,我们还看改变哪个参数的性价比最大。
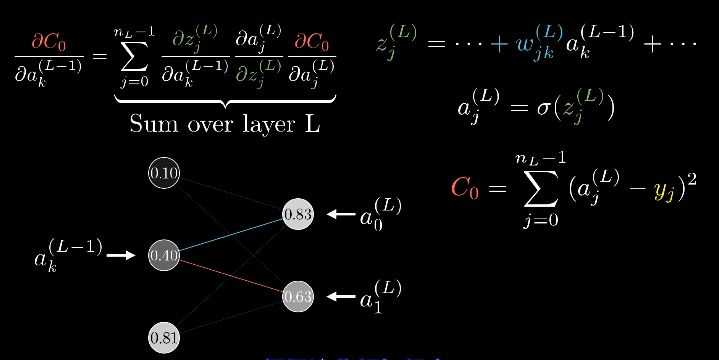
不过别忘了,从全局上看,只只不过是数字2的神经元所期待的变化,我们还需要最后一层其余的每个输出神经元,对于如何改变倒数第二层都有各自的想法。
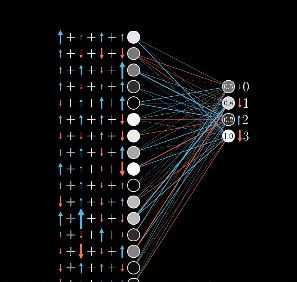
我们会把数字2神经元的期待,和别的输出神经元的期待全部加起来,作为如何改变倒数第二层的指示。这些期待变化不仅是对应的权重的倍数,也是每个神经元激活值改变量的倍数。
我们对其他的训练样本,同样的过一遍反向传播,记录下每个样本想怎样修改权重和偏置,最后再去一个平均值。
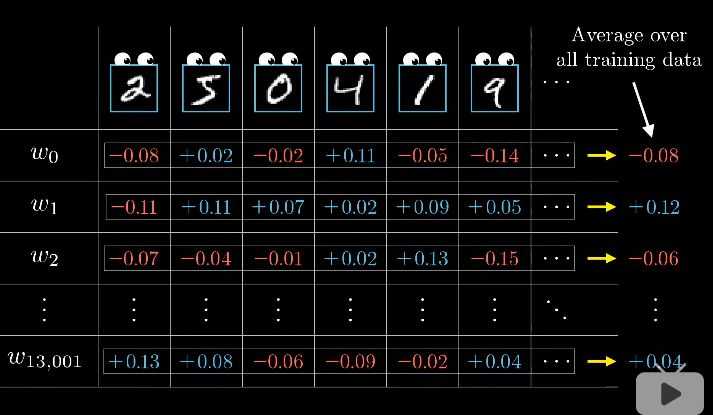
这里一系列的权重偏置的平均微调大小,不严格地说,就是代价函数的负梯度,至少是其标量的倍数。

实际操作中,我们经常使用随机梯度下降法。
首先把训练样本打乱,然后分成很多组minibatch,每个minibatch就当包含了100个训练样本好了。然后你算出这个minibatch下降的一步,这不是代价函数真正的梯度,然而每个minibatch会给一个不错的近似,计算量会减轻不少。
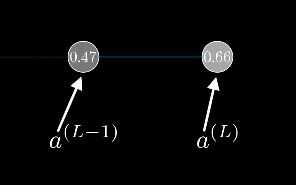
我们从一个最简单的网络讲起,每层只有一个神经元,图上这个网络就是由三个权重和三个偏置决定的,我们的目标是理解代价函数对这些变量有多敏感。这样我们就知道怎么调整这些变量,才能使代价函数下降的最快。
我们先来关注最后两个神经元,我们给最后一个神经元一个上标L,表示它处在第L层。
给定一个训练样本,我们把这个最终层激活值要接近的目标叫做y,y的值为0/1。那么这个简易网络对于单个训练样本的代价就等于$(a^{(L)}-y)^2$。对于这个样本,我们把这个代价值标记为$C_0$。
之前讲过,最终层的激活值公式:$a^{(L)} = \sigma (w^{(L)}a^{(L-1)}+b^{(L)})$
换个标记方法:
$$z^{(L)} = (w^{(L)}a^{(L-1)}+b^{(L)})$$
$$a^{(L)} = \sigma (z^{(L)})$$
整个流程就是这样的:
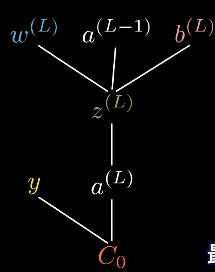
当然了,$a^{(L-1)}$还可以再向上推一层,不过这不重要。
这些东西都是数字,我们可以想象,每个数字都对应数轴上的一个位置。我们第一个目标是来理解代价函数对权重$w^{(L)}$的微小变化有多敏感。换句话说,求$C_0$对$w^{(L)}$的导数。
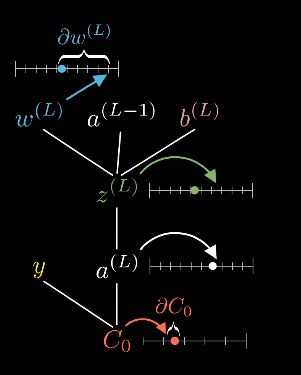
根据链式法则:
$$\frac{\partial C_0}{\partial w^{(L)}} = \frac{\partial z^{(L)}}{\partial w^{(L)}}\frac{\partial a^{(L)}}{\partial z^{(L)}}\frac{\partial C_0}{\partial a^{(L)}}\\\frac{\partial C_0}{\partial a^{(L)}}=2(a^{(L)}-y)\\\frac{\partial a^{(L)}}{\partial z^{(L)}}={\sigma }‘ (z^{(L)})\\\frac{\partial z^{(L)}}{\partial w^{(L)}}=a^{(L-1)}\\$$
所以
$$\frac{\partial z^{(L)}}{\partial w^{(L)}}\frac{\partial a^{(L)}}{\partial z^{(L)}}\frac{\partial C_0}{\partial a^{(L)}}=a^{(L-1)}{\sigma }‘ (z^{(L)})2(a^{(L)}-y)\\$$
$$\frac{\partial C}{\partial w^{(L)}} = \frac{1}{n}\sum _{k=0}^{n-1}\frac{\partial C_k}{\partial w^{(L)}}$$
当然了,对偏置求导数也是同样的步骤。
$$\frac{\partial C_0}{\partial b^{(L)}} = \frac{\partial z^{(L)}}{\partial b^{(L)}}\frac{\partial a^{(L)}}{\partial z^{(L)}}\frac{\partial C_0}{\partial a^{(L)}}=1{\sigma }‘ (z^{(L)})2(a^{(L)}-y)\\$$
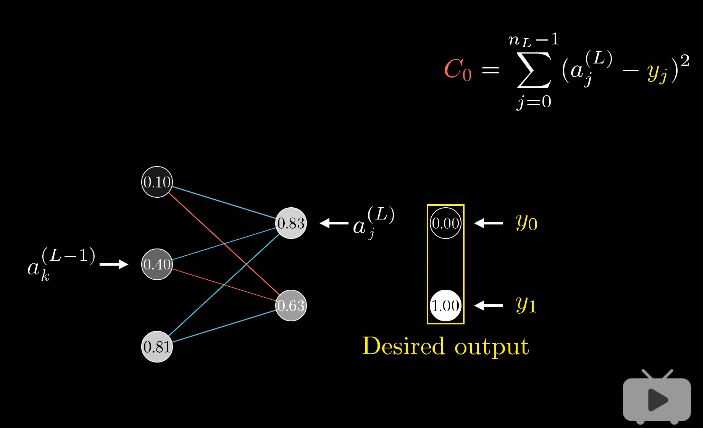
到这里,我们可以看每层不止一个神经元的情况了。
参考链接:
原文地址:https://www.cnblogs.com/lfri/p/10336199.html