标签:必须 ase 表结构 形式 配置 结构 语句 不能 方式
Sharding-Jdbc分表分库
LogicTable
数据分片的逻辑表,对于水平拆分的数据库(表),同一类表的总称。
订单信息表拆分为2张表,分别是t_order_0、t_order_1,他们的逻辑表名为t_order。
ActualTable
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0、t_order_1。
DataNode
数据分片的最小单元。由数据源名称和数据表组成,例:test_msg0.t_order_0。配置时默认各个分片数据库的表结构均相同,直接配置逻辑表和真实表对应关系即可。
ShardingColumn
分片字段。用于将数据库(表)水平拆分的关键字段。SQL中如果无分片字段,将执行全路由,性能较差。Sharding-JDBC支持多分片字段。
ShardingAlgorithm
分片算法。Sharding-JDBC通过分片算法将数据分片,支持通过等号、BETWEEN和IN分片。分片算法目前需要业务方开发者自行实现,可实现的灵活度非常高。未来Sharding-JDBC也将会实现常用分片算法,如range,hash和tag等。
在单个库里,有一张表拆分成n多个小表
比如 t_order拆分成 t_order0 t_order_1
insert操作时候,会根据id取模分表的总数 获取具体存放的位置 分表后 表名成t_order_0 和 t_order_1
与表的总数进行取模
跟前缀拼接起来 t_order-+(id%分表总数)
查询时候如何查询? 一样算法获取
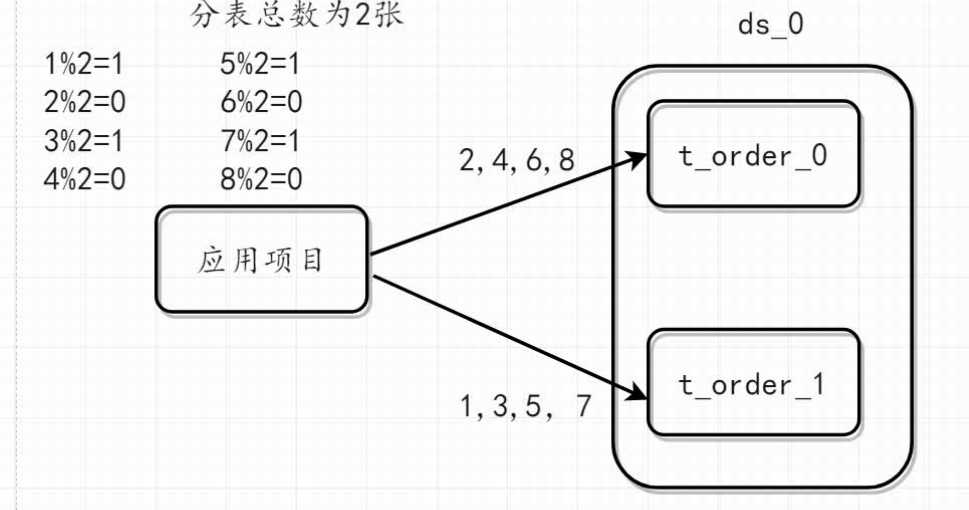
注意 分表之前,分表的数量定义好了之后,不能改了!!!!
SpringBoot整合Sharding-Jdbc分为两种方式
一种为原生配置方式,自己需要实现接口。
1.分库算法类需要实现SingleKeyDatabaseShardingAlgorithm<T>接口
2.分表算法类需要实现SingleKeyTableShardingAlgorithm<T>接口
第二种通过配置文件形式配置。
案例比如:t_order 拆分程t_order_0 t_order _1
maven:
注意本项目用的jpa:jpa的相关配置 jpa的底层是hibernate 可以自动通过对象得到sql语句
yml:
做分表必须实现接口:
分表算法类需要实现SingleKeyTableShardingAlgorithm<T>接口
有三个方法 核心是doEqualsSharding方法: 判断sql 如果有=条件判断 (需要配置分片算法)
需要写for循环
查询所有时候 会发送sql 查询所有表 然后汇总起来 返回给客户端
经验单个库 拆分成小表
分库分表,单张表进行拆分
比如t_order 拆分成多个不同的库进行存放
分库总数为2 根据id进行分库策略
一般分片都是单个库里面的 如果多个库 垮库查询效率很慢的哦
标签:必须 ase 表结构 形式 配置 结构 语句 不能 方式
原文地址:https://www.cnblogs.com/toov5/p/10336413.html