标签:ado 支持 高效 creat 功能 备份 doc div 恢复
Redis不支持事务,此事务不是关系型数据库中的事务;
Multi(组队阶段)、Exec、discard
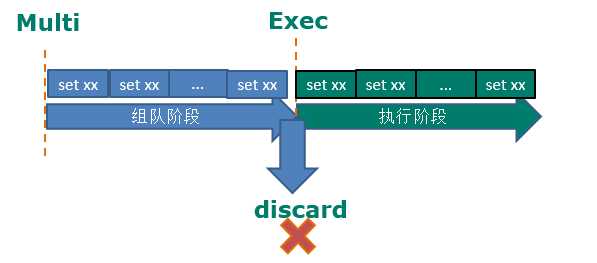
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> set k3
(error) ERR wrong number of arguments for ‘set‘ command ##在组队阶段就错误了!
127.0.0.1:6379> exec #开始执行队列中的命令,会回滚,都不会执行成功!!!
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> keys * ##回滚了,一个都没set成功!!
(empty list or set)
127.0.0.1:6379>
=========================================
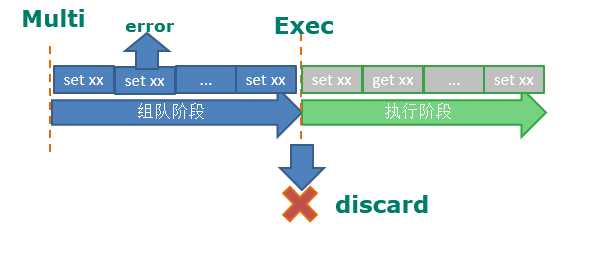
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> incr k2 ##执行的时候才能发现它是错误的,组队的时候不知道的
QUEUED
127.0.0.1:6379> set k3 v3 #组队成功!
QUEUED
127.0.0.1:6379> exec ##执行队列中的命令,发现有一个错误了就跳过!!
1) OK
2) OK
3) (error) ERR value is not an integer or out of range #incr k2失败了
4) OK ##跳过了第三个命令;
127.0.0.1:6379> keys *
1) "k3"
2) "k2"
3) "k1"
事务冲突的问题:
三个请求(账户中一共10000元)
一个请求想给金额减8000
一个请求想给金额减5000
一个请求想给金额减1000
如果没有事务,三个请求一个个执行,最后结果是-4000!!
有了事务:
把并发的串行,第一个请求先抢到就先执行时,会把账户锁住其他请求就不能执行了,执行完之后打开锁账户变成2000了然后再锁上;执行第二个请求....发现5000>2000就不执行了。
没有锁,只是有一个版本号;3个请求都可以看到账户的余额,可以同时执行,而悲观锁只能一个个的执行;第一个请求先抢到就先执行它,执行完之后变成2000,他把账户版本号改变成1.1版本了;虽然第二个请求也可以执行但发现版本号变了,也是执行不了的,版本不一致了;如果第三个请求看到的是1.1版本,他就可以执行了1000 < 2000;
Redis就用的乐观锁;
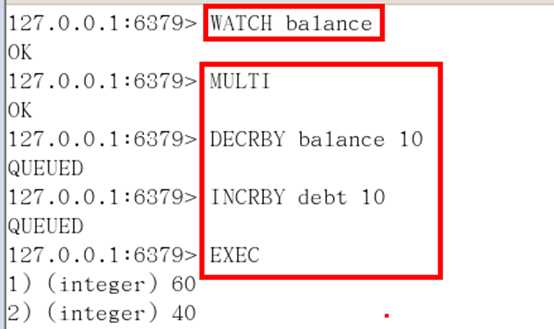
127.0.0.1:6379> get balance
"10000"
127.0.0.1:6379> watch balance
OK
127.0.0.1:6379> incrby balance 1000 ##事务执行之前balance被改动了,则事务被打断,执行不了事务了就;
(integer) 11000
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incrby balance 222
QUEUED
127.0.0.1:6379> exec
(nil)
127.0.0.1:6379> get balance
"11000"
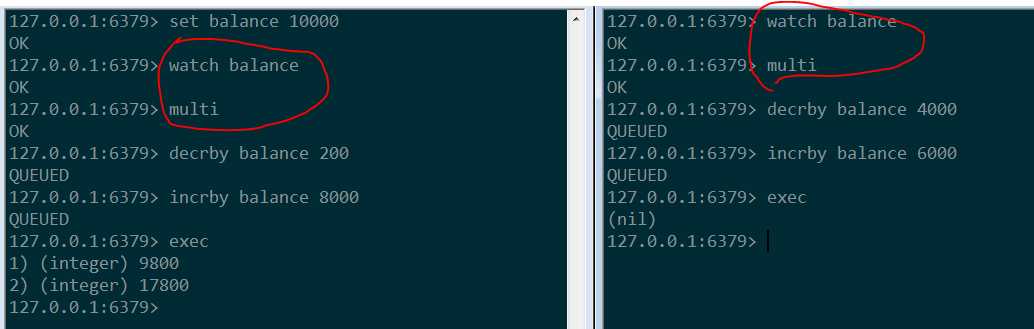
两个同时watch balance这个账户;第一个执行完了把版本号改变了,第二个看到的版本号跟之前不一样,就不能执行了。
备份的进行:
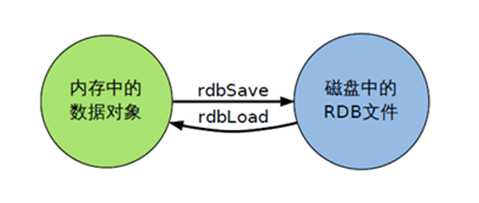
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
RDB的缺点是最后一次持久化后的数据可能丢失。(还没到那个持久化时间点,万一停电了,它就丢失了。)
在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,Linux中引入了“写时复制技术”,一般情况父进程和子进程会共用同一段物理内存(在持久化之前),只有进程空间的各段的内容要发生变化时(当子进程开始写,开始持久化时,会单独给子进程分配一块内存;),才会将父进程的内容复制一份给子进程。
rdb的备份
先通过config get dir 查询rdb文件的目录
将*.rdb的文件拷贝到别的地方
[root@hadoop myredis]# cp dump.rdb dump.rdb.bank 备份dump.rdb文件;
-rw-r--r--. 1 root root 100 1月 30 18:30 dump.rdb
-rw-r--r--. 1 root root 76 1月 10 14:31 dump.rdb.bank ##备份的文件
rdb的恢复
关闭Redis :shutdown
先把备份的文件拷贝到工作目录下
[root@hadoop myredis]# cp dump.rdb.bank dump.rdb
cp:是否覆盖"dump.rdb"? y 将备份文件把目标文件dump.rdb给覆盖掉级rdb的恢复;
启动Redis, 备份数据会直接加载
rdb的保存的文件
#把dump.rdb文件保存路径修改为:
dir /root/myredis
rdb在什么时候持久化:(自动保存策略--配置文件 | 手动保存策略shutdown、bgsave)
配置文件(vim redis.conf )中的自动保存策略
每分钟如果又10000个变化就保存一次;每5min如果有10个变化了就保存一次;每15min如果有1个变化了就保存一次;


手动保存快照(用bgsave)
shutdown & bgsave 自己的保存策略,都会持久化;;; 还有一种是配置文件中见上;
cp dump.rdb dump.rdb.bak 把dump.rdb文件复制一份为为dump.rdb.bak
flushdb shutdown
stop-writes-on-bgsave-error yes
当Redis无法写入磁盘的话(如文件太大硬盘中内存满了,就通知你),直接关掉Redis的写操作
rdbcompression yes 默认的
进行rdb保存时,将文件压缩
rdbchecksum yes
在存储快照后,还可以让Redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
rdb的优点 ms
节省磁盘空间
恢复速度快
缺点
虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。

-rw-r--r--. 1 root root 141 1月 30 20:19 appendonly.aof #有3个key,如果执行flushdb了,要先把它给删除了不然恢复的时候会把库给删了; -rw-r--r--. 1 root root 76 1月 30 20:18 dump.rdb -rw-r--r--. 1 root root 153 1月 30 19:34 dump.rdb.bank #有10个key [root@hadoop myredis]# cp dump.rdb.bank dump.rdb cp:是否覆盖"dump.rdb"? y [root@hadoop myredis]# redis-server redis.conf [root@hadoop myredis]# redis-cli 127.0.0.1:6379> keys * 1) "k3" 2) "k2" 3) "k1" 听AOF的;RDB有可能缺失,但AOF不会有缺失;AOF默认是关闭,如果同时开启默认是听AOF的;
AOF文件故障备份
AOF文件故障恢复
[root@hadoop myredis]# redis-check-aof --fix appendonly.aof 0x 6e: Expected prefix ‘a‘, got: ‘*‘ AOF analyzed: size=172, ok_up_to=110, diff=62 This will shrink the AOF from 172 bytes, with 62 bytes, to 110 bytes Continue? [y/N]: y Successfully truncated AOF
AOF同步频率设置(redis.conf配置文件)

Rewrite
Redis如何实现重写?
何时重写:

AOF的优点
AOF的缺点

用哪个好
用处
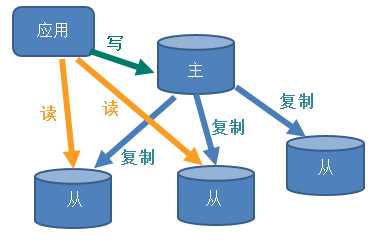 一山不容二虎,不能有两个主机;
一山不容二虎,不能有两个主机;
配从(服务器)不配主(服务器)
:%S/6379/6381 进行快速替换
[root@kris myredis]# cat redis6379.conf --->
include /root/myredis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
[root@kris myredis]# cat redis6381.conf
include /root/myredis/redis.conf
pidfile "/var/run/redis_6381.pid"
port 6381
dbfilename "dump6381.rdb"
slave-priority 1
一主二仆模式演示
1 切入点问题?slave1、slave2是从头开始复制还是从切入点开始复制?比如从k4进来,那之前的123是否也可以复制
2 从机是否可以写?set可否?
3 主机shutdown后情况如何?从机是上位还是原地待命
4 主机又回来了后,主机新增记录,从机还能否顺利复制?可以,但之前的记录没有了
5 其中一台从机down后情况如何?依照原有它能跟上大部队吗?
可以,重新slaveof “127.0.0.1” “6380“ ,都可以获得master的信息
复制原理
薪火相传
反客为主
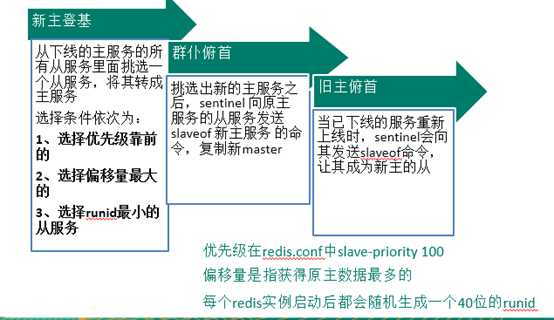
哨兵模式(sentinel)
配置哨兵
sentinel monitor mymaster 127.0.0.1 6379 1
故障恢复
1、安装ruby环境
rm -rf *.rdb安装之前先把它们删除掉
执行yum install ruby
执行yum install rubygems
2、拷贝redis-3.2.0.gem到/opt目录下
alt+p
3、执行在opt目录下执行 gem install --local redis-3.2.0.gem
vim redis6379.conf: include /root/myredis/redis.conf pidfile /var/run/redis_6379.pid port 6379 dbfilename dump6379.rdb cluster-enabled yes cluster-config-file nodes-6379.conf cluster-node-timeout 15000 cp redis6379.conf redis6380.conf
制作6个实例,6379,6380,6381,6389,6390,6391
安装redis cluster配置修改
将六个节点合成一个集群
合体:

redis cluster 如何分配这六个节点?
什么是slots
节点 A 负责处理 0 号至 5500 号插槽。
节点 B 负责处理 5501 号至 11000 号插槽。
节点 C 负责处理 11001 号至 16383 号插槽。
在集群中录入值
如 redis-cli -c –p 6379 登入后,再录入、查询键值对可以自动重定向。
查询集群中的值
故障恢复
public class JedisClusterTest { public static void main(String[] args) { Set<HostAndPort> set =new HashSet<HostAndPort>(); set.add(new HostAndPort("192.168.1.100",6379)); JedisCluster jedisCluster=new JedisCluster(set); jedisCluster.set("k1", "v1"); System.out.println(jedisCluster.get("k1")); } }
Redis 集群提供了以下好处:
Redis 集群的不足:
标签:ado 支持 高效 creat 功能 备份 doc div 恢复
原文地址:https://www.cnblogs.com/shengyang17/p/10264950.html