标签:集合 成本高 扩展性 出现 方式 ima 名称 together 性能调优
爆炸式发展的NoSQL技术NoSQL非常年轻,但他拥有的众多优秀的特性已经让众多企业和开发者开始接受,让我们来看一下来自于美国数据库知识网站DB-engines上个月的数据库排名情况。
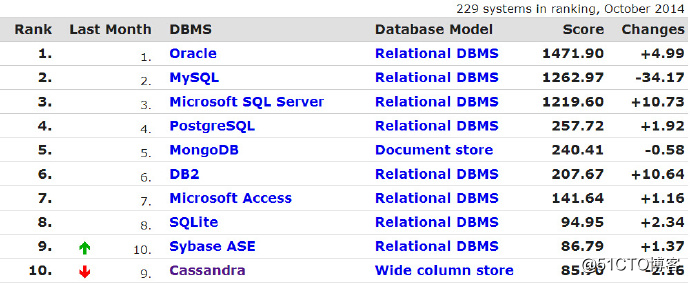
从排名中可以看到MongoDB数据库从众多的RDBMS(关系型数据库)中脱颖而出,已经成为第五名,并且还在不断上升中。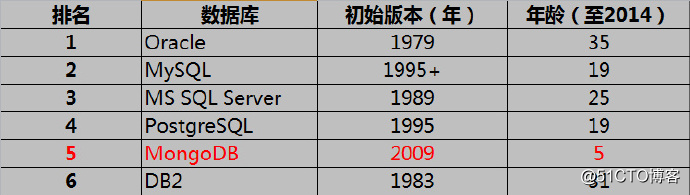
如果将数据库比喻成人类的话,那么MongoDB完全可以说是神童了,年仅5岁的他单枪匹马挑战一群叔叔级别的人物,并且按照近几年的发展速度来看,他也即将超越PgSQL成为第四名,虽然距离前方三位有着NB爹的富二代还有一定的距离,但在这样一个技术爆炸的年代还有什么不可能的事呢?
为什么选择MongoDB??
1.性能
在大数据时代中,大数据量的处理已经成了考量一个数据库最重要的原因之一。而MongoDB的一个主要目标就是尽可能的让数据库保持卓越的性能,这很大程度地决定了MongoDB的设计。在一个以传统机械硬盘为主导的年代,硬盘很可能会成为性能的短板,而MongoDB选择了最大程度而利用内存资源用作缓存来换取卓越的性能,并且会自动选择速度最快的索引来进行查询。MongoDB尽可能精简数据库,将尽可能多的操作交给客户端,这种方式也是MongoDB能够保持卓越性能的原因之一。
2.扩展
现在互联网的数据量已经从过去的MB、GB变为了现在的TB级别,单一的数据库显然已经无法承受,扩展性成为重要的话题,然而现在的开发人员常常在选择扩展方式的时候犯了难,到底是选择横向扩展还是纵向扩展呢?
横向扩展(scale out)是以增加分区的方式将数据库拆分成不同的区块来分布到不同的机器中来,这样的优势是扩展成本低但管理困难。
纵向扩展(scale up) 纵向扩展与横向扩展不同的是他会将原本的服务器进行升级,让其拥有更强大的计算能力。这样的优势是易于管理无需考虑扩展带来的众多问题,但缺点也显而易见,那就是成本高。一台大型机的价格往往非常昂贵,并且这样的升级在数据达到极限时,可能就找不到计算能力更为强大的机器了。
而MongoDB选择的是更为经济的横向扩展,他可以很容易的将数据拆分至不同的服务器中。而且在获取数据时开发者也无需考虑多服务器带来的问题,MongoDB可以将开发者的请求自动路由到正确的服务器中,让开发者脱离横向扩展带来的弊病,更专注于程序的开发上。
3.使用
MongoDB采用的是NoSQL的设计方式,可以更加灵活的操作数据。在进行传统的RDBMS中你一定遇到过几十行甚至上百行的复杂SQL语句,传统的RDBMS的SQL语句中包含着大量关联,子查询等语句,在增加复杂性的同时还让性能调优变得更加困难。MongoDB的面向文档(document-oriented)设计中采用更为灵活的文档来作为数据模型用来取代RDBMS中的行,面向文档的设计让开发人员获取数据的方式更加灵活,甚至于开发人员仅用一条语句即可查询复杂的嵌套关系,让开发人员不必为了获取数据而绞尽脑汁。
NoSQL对传统数据库设计思维的影响
1.预设计模式与动态模式
传统数据库设计思维中,项目的设计阶段需要对数据库表中的字段名称、字段类型、进行规定,如果尝试插入不符合设计的数据,数据库不会接受这条数据以保证数据的完整性。
MySQL
--数据库字段:NAME, SONG
INSERT INTO T_INFO VALUES(‘John‘,‘Come Together‘); --成功
INSERT INTO T_INFO VALUES(‘小明‘, 20, ‘xiaoming@111.com‘); --失败
--数据库字段:NAME, SONG
INSERT INTO T_INFO VALUES(‘John‘,‘Come Together‘); --成功
INSERT INTO T_INFO VALUES(‘小明‘, 20, ‘xiaoming@111.com‘); --失败
NoSQL采用的是对集合(类似”表”)中的文档(类似于”行”)进行动态追加,在创建集合之初不会对数据类型进行限定,任何文档都可以追加到任何集合中去,例如我们可以将这样两条文档添加到一个集合中去:
MySQL
{"name" : "John", "song" : "Come Together"}
{"name" : "小明", "age":"20", "email" : "xiaoming@111.com"}
{"name" : "John", "song" : "Come Together"}
{"name" : "小明", "age":"20", "email" : "xiaoming@111.com"}
MongoDB中文档的格式类似于我们常见的JSON,由此可见,我们第一个拥有”name”、”song”两个字段,而第二个拥有”name”、”age”、”email”三个字段,这在预设计模式中的数据库是不可能插入成功的,但在MongoDB的动态模式是可以的,这样做的优势是我们不必为一些数量很少,但种类很多的字段单独设计一张表,可以将他们集中在单独一张表进行存储,但这样做的弊病也是显而易见的,我们在获取数据时需要对同一张表的不同文档进行区分,增加了开发上的代码量。所以在设计之初需要权衡动态模式的优劣来选择表中的数据类型。
2.范式化与反范式化
范式化(normalization)是关系模型的发明者埃德加·科德于1970年提出这一概念,范式化会将数据分散到不同的表中,利用关系模型进行关联,由此带来的优点是,在后期进行修改时,不会影响到与其关联的数据,仅对自身修改即可完成。
反范式化(denormalization)是针对范式化提出的相反理念,反范式化会将当前文档的数据集中存放在本表中,而不会采用拆分的方式进行存储。
范式化和反范式化之间不存在优劣的问题,范式化的好处是可以在我们写入、修改、删除时的提供更高性能,而反范式化可以提高我们在查询时的性能。当然NoSQL中是不存在关联查询的,以此提高查询性能,但我们依旧可以以在表中存储关联表ID的方式进行范式化。但由此可见,NoSQL的理念中反范式化的地位是大于范式化的。
MongoDB还年轻
MongoDB又有众多卓越的设计,但MongoDB依然存在着许多不擅长的问题,其中包括:
MongoDB不支持事务,现在众多的软件依旧需要事务的管理,所以对于事务一致性要求较高的程序只能在软件层面进行管理,而无法从数据库进行管理。
其他工具的支持范围,MongoDB从发布起到现在还不到5年的时间,所以会面临着许多的语言没有对应的工具包,所以如果你使用的语言没有对应的包,可能是导致你无法使用MongoDB最大的阻碍。
近几年的技术发展之快是激动人心的,每年都会出现让人眼前一亮的产品,然而它都需要经过时间的累积才能成为一个成熟的产品,MongoDB还需要成长,但他优秀的设计,肯定会让越来越多的开发者接受它
标签:集合 成本高 扩展性 出现 方式 ima 名称 together 性能调优
原文地址:http://blog.51cto.com/14158311/2348105