标签:css 百度首页 bdr find 代码 font link drivers ble
我们在做WEB自动化时,最根本的就是操作页面上的元素,首先我们要能找到这些元素,然后才能操作这些元素。
元素定位的8种方法:
id、name、class、tag、link、partail_link、xpath、css_selector
从上面定位到的搜索框属性中,有个id="kw"的属性,我们可以通过这个id定位到这个搜索框
代码:
# coding = utf-8
from time import sleep
from selenium import webdriver
# 驱动文件路径
driverfile_path = r‘D:\coship\Test_Framework\drivers\chromedriver.exe‘
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r‘https://www.baidu.com/‘)
# 通过id定位搜索框,并输入selenium
driver.find_element_by_id(‘kw‘).send_keys(‘selenium‘)
# 等待5秒
sleep(5)
# 退出
driver.quit()
我们就知道HTML是通过tag来定义功能的,比如input是输入,table是表格,等等...。每个元素其实就是一个tag,一个tag往往用来定义一类功能,我们查看百度首页的html代码,可以看到有很多div,input,a等tag,所以很难通过tag去区分不同的元素。基本上在我们工作中用不到这种定义方法,仅了解就行。
有时候一个超链接的文本很长很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,用这种方法模糊匹配了。
我们用这种方法来定位百度首页的“新闻”超链接。
代码:
# coding = utf-8
from time import sleep
from selenium import webdriver
# 驱动文件路径
driverfile_path = r‘D:\coship\Test_Framework\drivers\chromedriver.exe‘
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r‘https://www.baidu.com/‘)
# 通过partial_link定位"新闻"这个链接并点击
driver.find_element_by_partial_link_text(‘闻‘).click()
# 等待5秒
sleep(5)
# 退出
driver.quit()
前面介绍的几种定位方法都是在理想状态下,有一定使用范围的,那就是:在当前页面中,每个元素都有一个唯一的id或name或class或超链接文本的属性,那么我们就可以通过这个唯一的属性值来定位他们。但是在实际工作中并非有这么美好,有时候我们要定位的元素并没有id,name,class属性,或者多个元素的这些属性值都相同,又或者刷新页面,这些属性值都会变化。那么这个时候我们就只能通过xpath或者CSS来定位了。
代码:
# coding = utf-8
from time import sleep
from selenium import webdriver
# 驱动文件路径
driverfile_path = r‘D:\coship\Test_Framework\drivers\chromedriver.exe‘
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r‘https://www.baidu.com/‘)
# 通过xpath定位搜索框,并输入selenium
driver.find_element_by_xpath("//*[@id=‘kw‘]").send_keys(‘selenium‘)
# 等待5秒
sleep(5)
# 退出
driver.quit()
这种方法相对xpath要简洁些,定位速度也要快些,但是学习起来会比较难理解,这里只做下简单的介绍。
CSS定位百度搜索框代码:
# coding = utf-8
from time import sleep
from selenium import webdriver
# 驱动文件路径
driverfile_path = r‘D:\coship\Test_Framework\drivers\chromedriver.exe‘
# 启动浏览器
driver = webdriver.Chrome(executable_path=driverfile_path)
# 打开百度首页
driver.get(r‘https://www.baidu.com/‘)
# 通过CSS定位搜索框,并输入selenium
driver.find_element_by_css_selector(‘#kw‘).send_keys(‘selenium‘)
# 等待5秒
sleep(5)
# 退出
driver.quit()
1 <html> 2 3 <head> 4 ........... 5 </head> 6 7 <body> 8 <div name="demo"> 9 <span1> 10 <p>这是一段实例文本</p> 11 </span1> 12 <span2> 13 <P>文本2</P> 14 </span2> 15 </div> 16 </body> 17 18 </html>
一般在浏览器自带的开发者工具中,使用$x("xpath表达式")验证xpath的正确性,$$("css Selector")验证css选择器的正确性。
A、$x( "//元素名[@属性名=‘属性值‘] [序号]" ) ——使用元素的开始标签中的 “属性” 来定位
例如:定位<div>元素:$x("//div[@name=‘demo‘]")
B、$x( "//元素名[text()=‘文本内容‘] [序号]" ) ——使用开始标签和结束标签之间的文本内容来定位
例如:定位<p>元素:$x("//p[text()=‘这是一段实例文本‘]")
1、使用“//”表示在整个页面的所有元素中进行全路径的查找(常用“//”来减少中间层级的元素,用于相对路径查找,以//开头,表示在文档任意层级位置开始查找,表达式中的//,则表示在当前层级内任意位置开始查找,类比于在某个文件夹下搜索文件。),
2、如果换成“/”表示在当前指定的元素中进行查找(用于绝对路径查找,以/html开头的XPath表达式从HTML文档的最上级元素开始逐层查找。类比于在windows文件系统中通过层层打开文件夹找文件。),例如:
定位<div>元素:$x("/html/body/div")
定位<p>元素:$x("/html/body/div/span1/p")
3、也可以“//”和“/”混合使用:
定位<p>元素:$x("//body/div//p[text()=‘文本2‘]")
a、定位元素时的路径,除了使用“=”方式,也可以使用“contains”方式(对应的属性值或者文本内容可以只包含其中一部分,相当于模糊查询)。
语法是:contains(@属性名,‘属性值的一部分‘) 或者 contains(text(),‘文本内容的一部分‘)
查找<div>元素: $x("//div[contains(@name,‘de‘)]") 或者 $x("//p[contains(text(),‘这是‘)]")
b、类似于contains的用法还有:stars-with等等,
strats-with(@属性,"属性值的一部分"):表示属性以某些内容开头
1、某一个元素定位成功后还可以使用 “/” 、"//" 接上后续的子孙元素。
2、在xpath当中,下标的序号从1开始。
3、$x()获取出来的内容会是一个数组存放的形式,可以通过下标来进行选择,下标从0开始。
假设上述的<span1>和<span2>的名称都是<span>时,那么 $x("//body/div/<span>][1]") 和 $x("//body/div/<span>]")[0] 都是定位到的第一个<span>元素。
css:cascading style sheet 层叠样式表,用于给HTML当中的元素指定样式。


css选择器的定位方法: $("css选择器")和 $$("css选择器") 的区别:
$(“selector”)找到的元素只会匹配selector的第一个元素,
而 $$("selector")匹配到的是所有符合selector的元素的数组。
html的元素层级:父元素、子元素、祖宗元素、子孙元素、兄弟元素
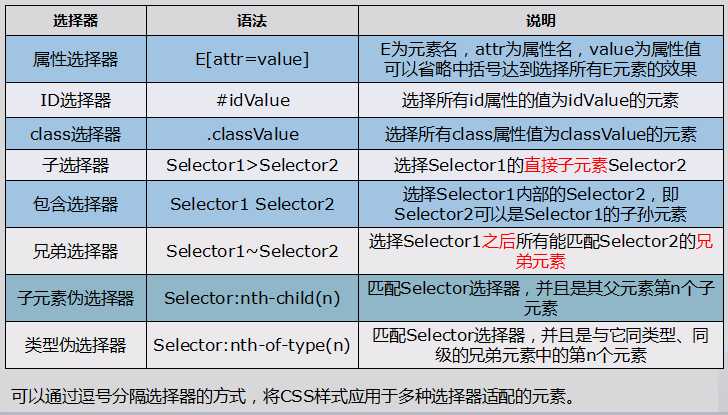
“=”也可以搭配 “ ^ ” 、" $ " 或者 " * "使用,
如:E[attr^=‘value‘] 表示以value属性中开头的元素E;
E[attr$=‘value‘] 表示以value属性中结尾的元素E;
E[attr*=‘value‘] 表示属性中包含value的元素E;
css选择器中, " selector1 selector2 " 的空格相当于xpath中的“//”,
css选择器中“selector1 > selector2”的“>”相当于xpath中的“/”。
定位元素后,可以通过 “.” 运算符获取元素中的属性:
innerHTML:获取元素中包含其他子元素在内的所有内容
innerText:获取元素中所有的文本
text:获取元素中的文本,适用范围比innertext少,有些元素不支持。
value:通过设置input或者其他输入框中的值,来调试网页
在HTML中某些事件发生时,可以调用JavaScript脚本来处理事件响应。
例如: <button type="button" onclick="myFunction()">Try it</button>
常用的一些事件属性比如: onclick、onblur、onfocus、oninput 等等。
通过DOM语法,也可以对HTML页面中的元素进行调试和操作。常用的dom语句和操作可以在浏览器的console中进行调试,这也是进行UI自动化测试的手段之一。
可以操作的DOM语法:
innerHTML:获取元素中包含其他子元素在内的所有内容
innerText:获取元素中所有的文本
text:获取元素中的文本,适用范围比innertext少,有些元素不支持。
value:通过设置input或者其他输入框中的值,来调试网页
click():通过点击方法,操作对应的元素。
标签:css 百度首页 bdr find 代码 font link drivers ble
原文地址:https://www.cnblogs.com/zzp-biog/p/10171750.html