标签:切分 技术 学习 处理 end 机器学习 jar包 not ++
一、前提
IKAnalyzer分词器常应用于大数据开发的数据准备阶段,它能对任意长的文字进行关键字提取、文字重组、数据清洗等二次处理,并将处理好的关键数据通过某种分割符重新拼接起来,形成一个可用于进行机器学习的数据集。
二、准备阶段
使用eclipse创建一个Maven工程,通过配置pom.xml文件来导入IKAnalyzer的jar包,我这用导入的是ikanalyzer-2012_u6.jar,然后在src目录下分别创建IKAnalyzer.cfg.xml、extend.dic、stopword.dic这三个文件,然后再去百度新闻中截取一段新闻内容进行处理。
新闻内容:
多次说幸福都是奋斗出来的,奋斗本身就是一种幸福。辛勤奋斗的人生是精彩的,也值得点赞。2019年1月16日,在河北雄安新区规划展示中心,通过大屏幕连线京雄城际铁路雄安站建设工地现场。他对现场施工人员说:“现在是数九寒冬、天寒地冻,但我们的铁路建设者仍然辛勤劳动着。在此,我代表党中央,向你们并通过你们向全国所有的铁路建设者、劳动者们致以亲切的问候和良好的祝愿!”他勉励大家说,你们正在为雄安新区建设这个“千年大计”做着开路先锋的工作,功不可没。
配置IKAnalyzer.cfg.xml:
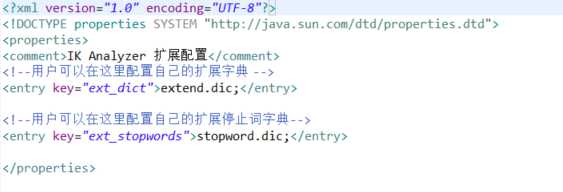
extend.dic:扩展词典,是为了让需要切分的语句里面的词根据扩展词典里的词进行比较,对此进行拼接,不切分。
设置extend.dic:

stopword.dic:停止词典,将语句与停用词典进行比较,直接将无用词进行删除
设置stopword.dic:

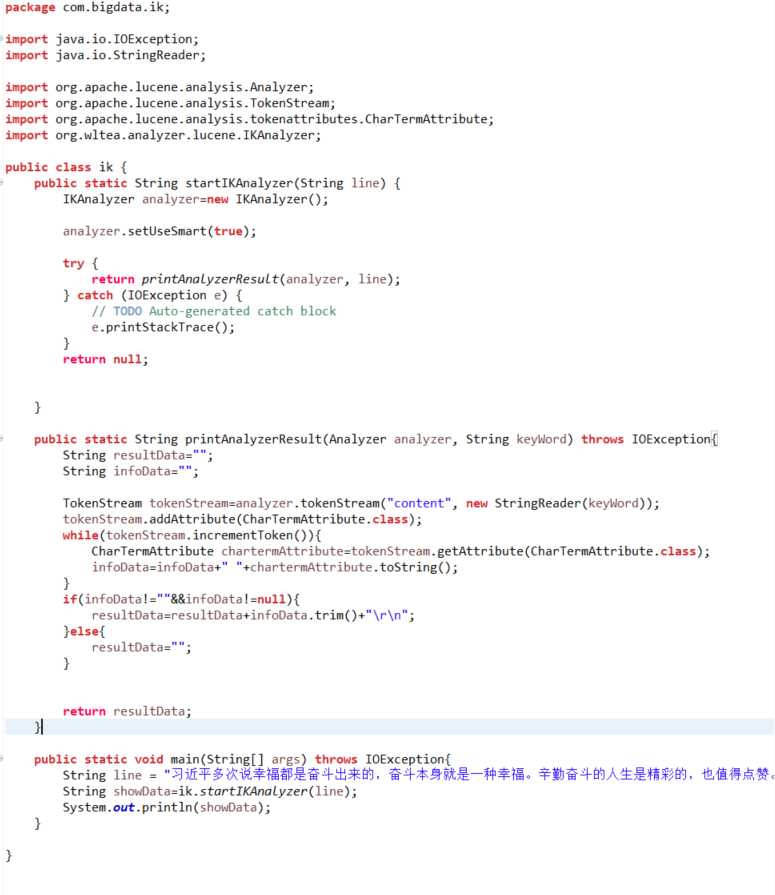
三、代码
创建一个ik.java文件,代码如下:
四、运行结果
(1)未加载extend.dic和stopword.dic的情况:
多次 说 幸福 都是 奋斗 出来 的 奋斗 本身 就是 一种 幸福 辛勤 奋斗 的 人生 是 精彩 的 也 值 得点 赞 2019年 1月 16日 在 河北 雄 安 新区 规划 展示中心 通过 大屏幕 连线 京 雄 城际 铁路 雄 安 站 建设 工地 现场 他 对 现场 施工人员 说 现在是 数九寒冬 天寒地冻 但 我们 的 铁路 建设者 仍然 辛勤劳动 着 在此 我 代表 党中央 向 你们 并 通过 你们 向 全国 所有 的 铁路 建设者 劳动者 们 致以 亲切 的 问候 和 良好 的 祝愿 他 勉励 大家 说 你们 正 在为 雄 安 新区 建设 这个 千年 大计 做着 开路先锋 的 工作 功不可没
(2) 加载extend.dic和stopword.dic的情况
多次说 幸福 都是 出来 本身 就是 幸福 辛勤 人生是精彩的 也 值得 点赞 2019年1月16日 在 河北 雄安新区 展示中心 通过 大屏幕 连线 京 雄 城际 铁路 雄 安 站 建设 工地 他 对 施工人员 说 现在是 数九寒冬 天寒地冻 但 我们 铁路 建设者 仍然 辛勤劳动 着 在此 我 代表 党中央 向 你们 并 通过 你们 向 全国 所有 铁路 建设者 劳动者 们 致以 亲切 问候 和 良好 祝愿 他 勉励 大家 说 你们 正在为 雄安新区 建设 这个 千年 大计 做着 开路先锋 工作 功不可没
五、注意事项
修改extend.dic和stopword.dic文件最好使用Notepad++工具,文字编码格式为UTF-8编码
标签:切分 技术 学习 处理 end 机器学习 jar包 not ++
原文地址:https://www.cnblogs.com/zjkf8686/p/10351093.html