标签:package http shu content 概述 style not 计算 存在
上一篇随笔【杂谈】一个回车下去,浏览器做了什么?讲了浏览器的处理,这里再用一个例子讲解一下,也不算讲解,算是梳理一下服务端处理浏览器请求的过程。当然实际过程要比这复杂多了。下文的例子,其实就是《How Tomcat Works》这本书的第一个例子,感兴趣的可以去看这本书。不过书上的例子有问题,我下文中会提到。
注:此项目不需要用tomcat,纯Java底层代码写就可以了。
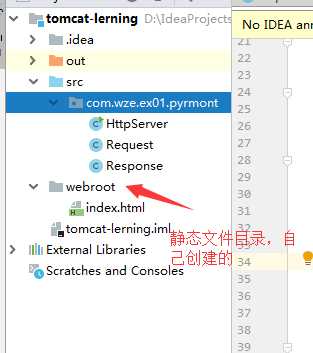
程序有三个类HttpServer,Request,Response。
HttpServer => 负责监听socket连接,创建Request、Response对象
Request => 用于获取请求信息的URI(利用Socket的InputStream),这里URI就是静态网页文件的相对路径
Response => 用于发送响应数据报(利用Request获取请求信息,利用OutputStream写出数据)
程序包图:
由于贴完整代码都会使篇幅略显过长,所以下面都折叠起来了,看客可以逐个展开查看。
HttpServer.java

package com.wze.ex01.pyrmont; import java.io.File; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.net.InetAddress; import java.net.ServerSocket; import java.net.Socket; public class HttpServer { public static final String WEB_ROOT = System.getProperty("user.dir") + File.separator + "webroot"; private static final String SHUTDOWN_COMMAND = "/SHUTDOWN"; private boolean shutdown = false; public static void main(String[] args) { System.out.println(WEB_ROOT); HttpServer server = new HttpServer(); server.await(); } public void await() { ServerSocket serverSocket = null; int port = 8080; try { //之所以要绑定监听的IP地址,是因为一个电脑可能有多个网卡 serverSocket = new ServerSocket(port, 1, InetAddress.getByName("127.0.0.1")); } catch (IOException e) { e.printStackTrace(); //如果绑定失败,那么这个程序也就没有运行下去的必要了。 System.exit(1); } while(!shutdown) { Socket socket = null; InputStream input = null; OutputStream output = null; try { //接收一个请求,处理完毕后关闭连接 socket = serverSocket.accept(); input = socket.getInputStream(); output = socket.getOutputStream(); Request request = new Request(input); request.parse(); Response response = new Response(output); response.setRequest(request); response.sendStaticResource(); socket.close(); shutdown = request.getUri().equals(SHUTDOWN_COMMAND); } catch (Exception e) { e.printStackTrace(); continue; } } } }
Request.java
package com.wze.ex01.pyrmont; import java.io.IOException; import java.io.InputStream; public class Request { private InputStream input; private String uri; public Request(InputStream input) { this.input = input; } public void parse() { //之所以是大小是2048,是因为请求行的大小一般就是2048 StringBuffer request = new StringBuffer(2048); int i; byte[] buffer = new byte[2048]; try { i = input.read(buffer); //读入数据到buffer,并返回请求行的实际长度 } catch (IOException e) { e.printStackTrace(); i = -1; } for(int j = 0; j < i; j++) { request.append((char)buffer[j]); } System.out.println(request.toString()); uri = parseUri(request.toString()); //从请求行中把uri取出来 System.out.println(uri); } /** * 获取请求行中的uri * * 请求行格式:Method URI Version * 用空格做分隔符 * @param requestString * @return */ private String parseUri(String requestString) { int index1, index2; index1 = requestString.indexOf(‘ ‘); if(index1 != -1) { index2 = requestString.indexOf(‘ ‘, index1+1); System.out.println(index1 + " " + index2); if(index2 > index1) return requestString.substring(index1 + 1, index2); } return null; } public String getUri() { return uri; } }
Response.java
package com.wze.ex01.pyrmont; import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.io.OutputStream; public class Response { private static final int BUFFER_SIZE = 1024; Request request; OutputStream output; public Response(OutputStream output) { this.output = output; } public void setRequest(Request request) { this.request = request; } public void sendStaticResource() throws IOException { byte[] bytes = new byte[BUFFER_SIZE]; FileInputStream fis = null; try { //获取用户请求文件的实际路径 File file = new File(HttpServer.WEB_ROOT + request.getUri()); System.out.println(file); if(file.exists()) { //如果文件存在,则读取到缓冲数组,再利用socket的outputstream写出数据 long contentLength = file.length(); String successMessage = "HTTP/1.1 200 success\r\n" + "Content-Type:text/html\r\n" + "Content-Length:"+contentLength +"\r\n" + "\r\n"; output.write(successMessage.getBytes()); fis = new FileInputStream(file); //每次最多读写1024字节,直到全部读完 int ch = fis.read(bytes, 0, BUFFER_SIZE); System.out.println(ch); while(ch != -1) { output.write(bytes, 0, ch); ch = fis.read(bytes, 0, BUFFER_SIZE); } } else { String errorMessage = "HTTP/1.1 404 File Not Found\r\n" + "Content-Type:text/html\r\n" + "Content-Length:23\r\n" + "\r\n" + "<h1>File Not Found</h1>"; output.write(errorMessage.getBytes()); } } catch (Exception e) { System.out.println(e.toString()); } finally { if(fis != null) fis.close(); } } }
运行HttpServer的主方法,然后在浏览器地址栏键入localhost:8080/index.html,你就可以在浏览器看见网页内容了。到这一步就相当于实现了一个apache服务器。
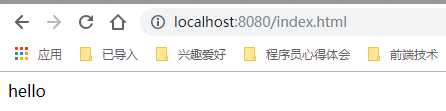
注意:index.html是你自己创建的,你随便写点内容。我是只在body里面写了hello。
Request对象中缓冲大小为什么是2048?
因为大多数浏览器请求行最大长度就是2048字节,所以读取2048字节,里面必然完全包含了请求行的数据。这也是parameter传参长度限制的原因,因为parameter在URI中,而URI又是组成请求行的元素之一。
注:HTTP请求报文的请求行由三部分组成,请求方法,URI,协议版本,且这三个参数用空格隔开。
前面说的例子有问题在哪里?
上面的例子是正常的,不过书本里面少了一部分,那就是响应头的编写,如果没有发送响应头给浏览器,它无法识别发送给它的数据是什么。
Content-Length在上文中起什么作用?
细心的朋友会发现,我在响应头中添加了Content-Length的头信息,指明了文件的长度,也就是字节数。有了这个头信息,浏览器就可以知道什么时候数据接收完成。这跟浏览器的加载提示有关。
怎么让别人也能访问到这个网页?
如果你的电脑有公网IP的话,那你要做的只是把程序跑起来挂着,然后开放端口。开放端口是什么意思?默认情况下,防火墙会为了安全,其他电脑是不能随便访问本机的端口(例外,80端口是默认开启的)。开启的方法就是进入防火墙设置进站规则,开放8080端口。
其实涉及到网络通信,底层传递的就是一堆字节,而"协议"从一个角度来说,其实就是双方共同遵守的数据格式,它指明从哪里到哪里的字节数据表示的是什么,应用程序根据这些进行处理。想来,其实这些东西在上《计算机网络》的时候都讲到了,只是当时没有现在这种感觉吧。
标签:package http shu content 概述 style not 计算 存在
原文地址:https://www.cnblogs.com/longfurcat/p/10355514.html
