标签:复杂度 如何 open fun 数据结构 算法介绍 代码 http div
算法是指解题方案的准确而完整的描述,是一系列解决问题的清晰指定,算法代表着用系统的方法描述解决问题的策略机制。这个解释来源于百度,对于入门来说这个解释等于白说了,你的一脸懵逼我懂,大神略过。
开始了解算法就应该对程序有一些认识和理解了,其实我们所有的程序可以理解为算法加数据结构。撇开数据结构不谈,我们日常写的代码如if-else、for(...)等就是算法。在数学里加减乘除是算法,方程公式,几何公式,乃至高数也都是算法,而我们的if-else、for(...)就相当于数学中的加减乘除这种级别的算法,当然在程序里也有加减乘除,同样也是算法。
但是我们日常所表达的算法和算法通常的说法有一些区别,我们日常表达的算法基本上都是特指一些特殊的算法,这些特殊的算法就相当于数学中的高数级别(不是指难度)。这些算法的特殊性并非其难度,而是具备通用性、高效(空间和时间)、解决特定问题的程序。
在前端编程中查重是比较常见的应用,以数组查重为例,通常的思路是通过嵌套循环,让每个值与其他每个值进行逐个对比。思路有了,我们就来实现以下:
var arr = [8,4,79,38,2,67,4,19,8,13,47,68,37,13,48,2]; var cont = 0;//记录比较次数 for(var i = 0; i < arr.length; i++){ for(var j = 0; j < arr.length; j++){ if(arr[i] == arr[j] && i != j){//‘i != j‘-->排除与自己比较 console.log(arr[i]); } cont ++;//累计 } } console.log(cont);//256
这个查重算法可以说基本就实现了,因为解决了特定问题:找到重复的元素。但是这个算法并不是我们真正需要的算法,因为这样对比出现了很多重复,浪费很多计算资源和时间,所以这个算法需要改进。
改进的目的就是消除重复对比,从数组的有序性我们可以知道,每一次内部循环不需要从头开始对比,因为前面已经对比过了,所以改进代码如下:
for(var i = 0; i < arr.length; i++){ for(var j = i + 1; j < arr.length ; j++){//i+1表示自身和自身之前的元素都不需要比较了 if(arr[i] == arr[j]){ console.log(arr[i]); } cont ++;//累计 } } console.log(cont);//120
这样改进后的查重效率可以从对比次数看到,减少了一半多,也就说明了改进后的查重算法效率提高了一倍多。在算法中,不存在对错的概念,而是在保证实现功能的最优方案是什么。这些最优方案就是我们需要的算法,这些算法可以提高用户的体验,减少硬件资源的消耗。
用这样的思路我们来实现以下数组去重算法:(这段代码折叠,大家可以先尝试自己写)

function unique(arr){ var obj = {}; var result = []; for(var i in arr){ if(!obj[arr[i]]){ obj[arr[i]] = true; result.push(arr[i]); } } return result; }
这里暂时介绍两种排序算法,就这两种排序算法介绍一些关于排序的应用场景解析,在前面的查重和去重算法中我们主要考虑到了效率。接着我们用这两个排序算法来将算法的解决特定问题引述出来,这两个算法并不能全面说明什么是特定的问题,它们仅仅只能告诉我们不同的算法存在其优点和缺点,适应的场景也就会随之发生变化,而这些场景往往来自不同的业务和功能的需求,需求来源不同,但可以根据其不同特性归类从而选择不同的算法,这就是算法的通用性。
1.冒泡排序(升序):
for(var j = 0; j < arr.length - 1; j++){ for(var i = 0; i < arr.length - j - 1; i++){ if(arr[i] > arr[i + 1]){ var temp = arr[i]; arr[i] = arr[i + 1]; arr[i + 1] = temp; } } }
首先我们就这这个升序的冒泡排序算法做一个图解,来理解冒泡排序的逻辑及其原理:
假设有数组:var arr = [5,3,7,2,8,6,1,9,4];
当外层循环第一次时:j == 0, i == 0。
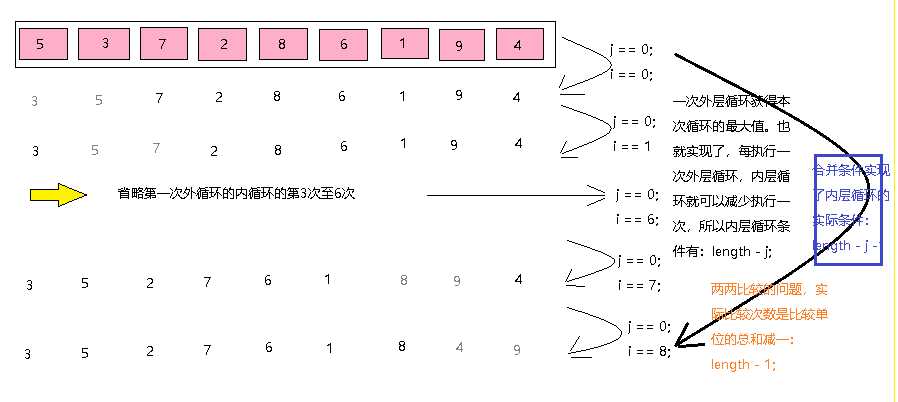
通过一次外层循环,图解内部完全循环,可以看到冒泡循环就是通过两个相邻元素两两比较,升序就是将大值交换到后面的逻辑,每一次外层循环都可以获得对应循环终点的最大值。既然是两两比较,那么最一个单独的元素就不需要在循环比较了,所以外层循环也可以减去一次。
2.选择排序(升序):
for(var j = 0; j < arr.length - 1; j ++){ var max = 0; for(var i = 0; i < arr.length - j - 1; i++){ if (arr[i + 1] > arr[max]) { max = i + 1; } } var temp = arr[arr.length - j -1]; arr[arr.length - j - 1] = arr[max]; arr[max] = temp; }
选择排序的逻辑就是外层负责交换,内层负责找到对应一次外层循环终点内的最大值的索引,然后在一次外层循环结束时,将最大值与该次循环终点的元素进行交换位置。下面提供选择排序的图解:
假设有数组:var arr = [5,3,7,2,8,6,1,9,4];
第一轮外层循环
i [i+1]>[max] max
0 3>5 =>false 0
1 7>5 =>true 2
2 2>7 =>false 2
3 8>7 =>true 4
4 6>8 =>false 4
5 1>8 =>false 4
6 9>8 =>true 7
7 4>9 =>false 7
max=7;终点=8;
第二轮外层循环
i [i+1]>[max] max
0 3>5 =>false 0
1 7>5 =>true 2
2 2>7 =>false 2
3 8>7 =>true 4
4 6>8 =>false 4
5 1>8 =>false 4
6 4>8 =>false 4
max=4;终点=7;
第三轮外层循环
i [i+1]>[max] max
0 3>5 =>false 0
1 7>5 =>true 2
2 2>7 =>false 2
3 4>7 =>false 2
4 6>7 =>false 2
5 1>7 =>false 2
max=2;终点=6;
第四轮外层循环
i [i+1]>[max] max
0 3>5 =>false 0
1 1>5 =>false 0
2 2>5 =>false 0
3 4>5 =>false 0
4 6>5 =>true 5
max=5;终点=5;
第五轮外层循环
i [i+1]>[max] max
0 3>5 =>false 0
1 1>5 =>false 0
2 2>5 =>false 0
3 4>5 =>false 0
max=0;终点=4;
第六轮外层循环
i [i+1]>[max] max
0 3>4 =>false 0
1 1>4 =>false 0
2 2>4 =>false 0
max=0;终点=3;
第七轮外层循环
i [i+1]>[max] max
0 3>2 =>true 1
1 1>3 =>false 1
max=1;终点=2;
第八轮外层循环
i [i+1]>[max] max
0 1>2 =>false 0
max=0;终点=1;
通过上图将选择排序的处理逻辑可视化展示后,可以看到交换次数明显少于冒泡排序,但是借助了一个最大值索引变量来完成,这个变量会在每次外层循环时被创建,从这个角度来说对于空间的需求比冒泡排序要大。从效率的角度来讲选择排序的空间效率是肯定弱于冒泡排序,但是时间效率会如何呢?这个问题需要考虑更多的因素才能得到结果,由于这篇博客是基于入门级别的角度来阐述,所以暂时不探讨太深入的问题。
通过两个排序算法我们可以了解到解决同一个问题有多种方案,但是不同方案会有不同的优势和劣势,怎么在实际问题中应用这两个算法,需要对它们的优势和劣势进行深入的分析,这不在入门的范围内,后期会有博客更新算法知识点的深入理解部分。这篇博客旨在介绍算法是什么?我们如何对具体问题进行分析及编写算法,所以上面的两个排序算法还并不是我们能拿来解决具体问题的工具,我们还需要对其进一步逻辑分析和封装,修改成可以在需要是随时使用的函数。
这两个问题其实是一个问题,排序算法的核心工作就是【比较+交换】,这也是排序算法的共同特点,所以根据这个核心工作原理,上面两个排序算法可以封装成以下具体方法:
//比较 function compare(a,b){ if (a > b) { return true; }else{ return false; } } //交换 function exchange(arr,m,n){ var temp = arr[m]; arr[m] = arr[n]; arr[n] = temp; } //封装冒泡排序 function bubbleSort(arr){ for(var j = 0; j < arr.length - 1; j++){ for(var i = 0; i < arr.length - j - 1 ; i++){ if(compare(arr[i] , arr[i + 1])){ exchange(arr,i,i+1) } } } } //封装选择排序 function selectionSort(arr){ for(var j = 0; j < arr.length - 1; j ++){ var max = 0; for(var i = 0; i < arr.length - j - 1; i++){ if(compare(arr[i +1] , arr[max])){ max = i + 1; } } exchange(arr,arr.length - j -1,max); } }
了解到这里,我们应该可以大概的理解算法的定义了:算法是指解题方案的准确而完整的描述,是一系列解决问题的清晰指定,算法代表着用系统的方法描述解决问题的策略机制。对于同一个问题我们又会有不同的策略机制,就拿排序算法来说,我们分析的就有两种了,但是并不止这两种,常见的排序算法还有快速排序、直接插入排序、希尔排序、堆排序、归并排序、基数排序。不同的排序算法有不同的应用场景,有时间再来更新深入分析算法的内容了,今天是大年初四,在这里祝福大家猪年好运,身体健康,猪定幸福!
想深入了解算法的话可以先参考这两个博客:
标签:复杂度 如何 open fun 数据结构 算法介绍 代码 http div
原文地址:https://www.cnblogs.com/ZheOneAndOnly/p/10355397.html
