标签:splay 存储 requests dax 获取 代码 div .com 中国
我们需要爬取的网站:最好大学网
我们需要爬取的内容即为该网页中的表格部分:
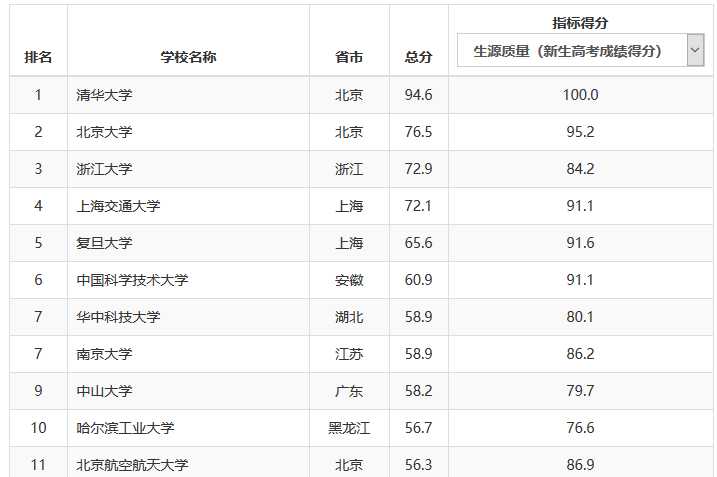
该部分的html关键代码为:
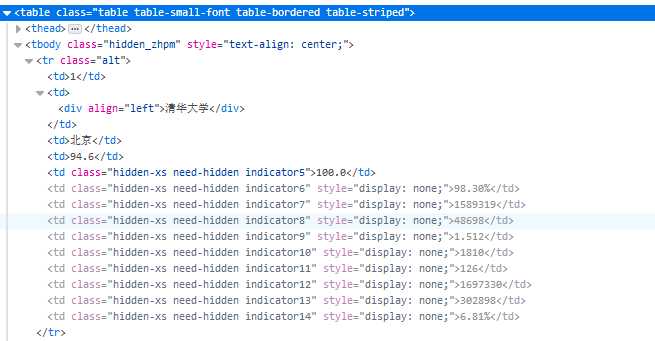
其中整个表的标签为<tbody>标签,每行的标签为<tr>标签,每行中的每个单元格的标签为<td>标签,而我们所需的内容即为每个单元格中的内容。
因此编写程序的大概思路就是先找到整个表格的<tbody>标签,再遍历<tbody>标签下的所有<tr>标签,最后遍历<tr>标签下的所有<td>标签,
我们用二维列表来存储所有的数据,其中二维列表中的每个列表用于存储一行中的每个单元格数据,即<tr>标签下的所有<td>标签中的所有字符串。
代码如下;
import requests from bs4 import BeautifulSoup import bs4 def get_html_text(url): ‘‘‘返回网页的HTML代码‘‘‘ try: res = requests.get(url, timeout = 6) res.raise_for_status() res.encoding = res.apparent_encoding return res.text except: return ‘‘ def fill_ulist(ulist, html): ‘‘‘将我们所需的数据写入一个列表ulist‘‘‘ #解析HTML代码,并获得解析后的对象soup soup = BeautifulSoup(html, ‘html.parser‘) #遍历得到第一个<tbody>标签 tbody = soup.tbody #遍历<tbody>标签的孩子,即<tbody>下的所有<tr>标签及字符串 for tr in tbody.children: #排除字符串 if isinstance(tr, bs4.element.Tag): #使用find_all()函数找到tr标签中的所有<td>标签 u = tr.find_all(‘td‘) #将<td>标签中的字符串内容写入列表ulist ulist.append([u[0].string, u[1].string, u[2].string, u[3].string]) def display_urank(ulist): ‘‘‘格式化输出大学排名‘‘‘ print("{:^10}\t{:^10}\t{:^10}\t{:^10}".format("排名", "大学名称", "省市", "总分")) for u in ulist: print("{:^10}\t{:^10}\t{:^10}\t{:^10}".format(u[0], u[1], u[2], u[3])) def write_in_file(ulist, file_path): ‘‘‘将大学排名写入文件‘‘‘ with open(file_path, ‘w‘) as file_object: file_object.write("{:^5}\t{:^6}\t{:^10}\t{:^10}\n".format("排名", "大学名称", "省市", "总分")) for u in ulist: file_object.write("{:^5}\t{:^6}\t{:^10}\t{:^10}\n".format(u[0], u[1], u[2], u[3])) def main(): ‘‘‘主函数‘‘‘ ulist = [] url = ‘http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html‘ file_path = ‘university rankings.txt‘ html = get_html_text(url) fill_ulist(ulist, html) display_urank(ulist) write_in_file(ulist, file_path) main()
打印显示:
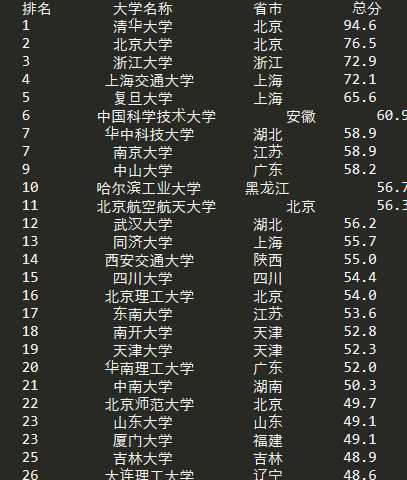
python爬虫入门---第二篇:获取2019年中国大学排名
标签:splay 存储 requests dax 获取 代码 div .com 中国
原文地址:https://www.cnblogs.com/huwt/p/10356543.html