标签:time() l数据库 har 刷新 mozilla 结果 word ffffff browser
功能实现爬取所有银行的银行名称和官网地址(如果没有官网就忽略),并写入数据库;
银行链接: http://www.cbrc.gov.cn/chinese/jrjg/index.html1.利用url访问页面并获取页面信息
2.利用正则表达式对页面信息进行筛选,获取我们需要的信息
3.保存至Mysql数据库中from urllib.request import urlopen
# 获取页面信息
def getPageInfo(url):
pageInfo = urlopen(url)
content = pageInfo.read().decode(‘utf-8‘)
return content
# 主函数
def main():
url = ‘http://www.cbrc.gov.cn/chinese/jrjg/index.html‘
pageInfo = getPageInfo(url)
print(pageInfo)
def main():
url = ‘http://www.cbrc.gov.cn/chinese/jrjg/index.html‘
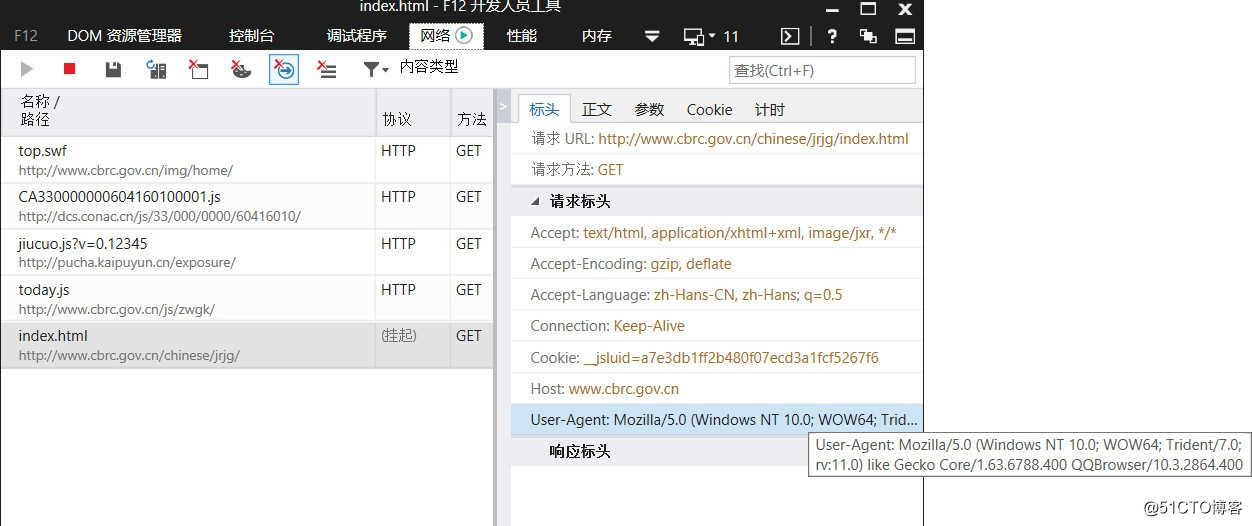
#修改UA,伪装成浏览器,以获取相应页面
user_agent = "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko Core/1.63.6788.400 QQBrowser/10.3.2864.400"
reqObj = request.Request(url, headers={‘User-Agent‘: user_agent})
pageInfo = getPageInfo(reqObj)
print(pageInfo)# 保存到文件pageContent
def saveInfo(data):
with open(‘doc/pageContent‘,‘w+‘,encoding=‘utf-8‘) as f:
f.write(data)
图中是获取的页面信息中所需信息中的一例
需要获取其中的 网址 和 银行名称
使用的正则表达式为‘<a href="(http.*?)".*?>\s+(.+?)\s+?</a>‘
这里注意利用\s+匹配额外的\t和\n# 利用正则匹配获取信息
def getInfo(data):
pattern = r‘<a href="(http.*?)".*?>\s+(.+?)\s+?</a>‘
info = re.findall(pattern ,data)
print(info)
首先在mysql中创建一个名为bankUrl的数据库
## 连接数据库
conn = pymysql.connect(
host=‘localhost‘, # 主机名
user=‘root‘, # 用户名
password=‘mysql‘, # 密码
database=‘bankUrl‘, # 连接对应数据库
charset=‘utf8‘, # utf-8编码
autocommit=True # 自动提交数据
)
cur = conn.cursor() # 创建游标
# 删除重建表格来刷新每次写入的数据
cur.execute(‘drop table bankurl‘)
creatTableSql = ‘create table if not exists bankUrl(银行名称 varchar(20),网址 varchar(100))default charset=utf8;‘
cur.execute(creatTableSql)
# 写入数据库
for item in getInfo(pageInfo):
insertSql = ‘insert into bankUrl(银行名称,网址) value("{1}","{0}")‘.format(item[0],item[1])
cur.execute(insertSql)import re
import time
from urllib import request
from urllib.request import urlopen
import pymysql
def timeCounter(fun):
def wrapper(*arg ,**kwargs):
startTime = time.time()
fun(*arg,**kwargs)
endTime = time.time()
print(fun.__name__+‘运行时间为%.2f‘%(startTime-endTime))
return wrapper
# 获取页面信息
def getPageInfo(url):
pageInfo = urlopen(url)
content = pageInfo.read().decode(‘utf-8‘)
return content
# 保存页面信息到文件
def saveInfo(data):
with open(‘doc/pageContent‘,‘w+‘,encoding=‘utf-8‘) as f:
f.write(data)
# 利用正则匹配获取信息
def getInfo(data):
pattern = r‘<a href="(http.*?)".*?>\s+(.+?)\s+?</a>‘
info = re.findall(pattern ,data)
return info
@timeCounter
def main():
url = ‘http://www.cbrc.gov.cn/chinese/jrjg/index.html‘
user_agent = "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko Core/1.63.6788.400 QQBrowser/10.3.2864.400"
reqObj = request.Request(url, headers={‘User-Agent‘: user_agent})
pageInfo = getPageInfo(reqObj)
# saveInfo(pageInfo)
conn = pymysql.connect(
host=‘localhost‘,
user=‘root‘,
password=‘mysql‘,
database=‘bankUrl‘,
charset=‘utf8‘,
autocommit=True, # 如果插入数据,, 是否自动提交? 和conn.commit()功能一致。
)
cur = conn.cursor()
# cur.execute(‘create database if not exists bankUrl;‘)
cur.execute(‘drop table bankurl‘)
creatTableSql = ‘create table if not exists bankUrl(银行名称 varchar(20),网址 varchar(100))default charset=utf8;‘
cur.execute(creatTableSql)
for item in getInfo(pageInfo):
insertSql = ‘insert into bankUrl(银行名称,网址) value("{1}","{0}")‘.format(item[0],item[1])
cur.execute(insertSql)
if __name__ == ‘__main__‘:
main()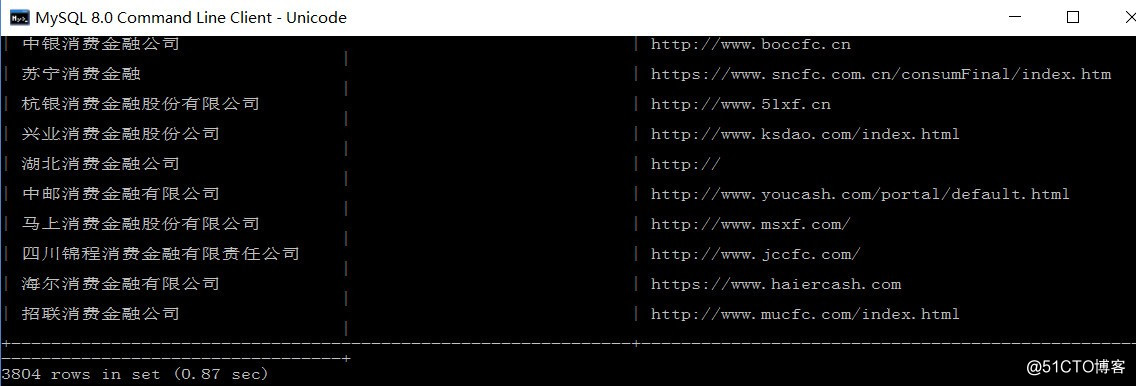
标签:time() l数据库 har 刷新 mozilla 结果 word ffffff browser
原文地址:http://blog.51cto.com/13992211/2349065