标签:tree 三层 vpd 算法 col arc jpg none class
深度&&广度优先算法
1.爬虫系列 深度&广度优先搜索 介绍
1.DFS(Depth-First-Search)深度优先搜索,是计算机术语,是一种在开发爬虫早期使用较多的方法,
是搜索算法的一种。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。
深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到这个HTML文件,再继续选择该HTML文件中的其他超链。
当不再有其他超链可选择时,说明搜索已经结束。
深度优先搜索是一个递归的过程
2.深度优先和广度优先搜索模型
广度优先搜索算法(Breadth First Search),又称为"宽度优先搜索"或"横向优先搜索",简称BFS
理解了深度优先搜索,也可以说是纵向,而广度优先搜索可以理解为横向同步搜索。初始点开始后以层次的方式,从第一层的邻接点开始,从第一层的1节点到2节点等。然后第二层的3节点到4节点5节点再三层的5节点到6节点7节点8节点等。
图:
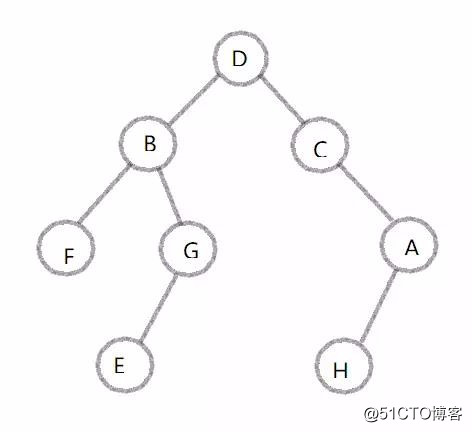
# 深度优先:根左右 遍历
#广度优先: 层次遍历,即一层一层遍历
# 深度优先:根左右 遍历
def depth_tree(tree_node):
if tree_node is not None:
print(tree_node._data)
if tree_node._left is not None:
return depth_tree(tree_node._left) #递归遍历
if tree_node._right is not None:
return depth_tree(tree_node._right) #递归遍历
#广度优先: 层次遍历,即一层一层遍历
def level_queue(root):
if root is None:
return
my_queue=[]
node = root
my_queue.append(node) # 根结点入队列
while my_queue:
node = my_queue.pop(0) # 出队列
print(node.elem) # 访问结点
if node.lchild is not None:
my_queue.append(node.lchild) # 入队列
if node.rchild is not None:
my_queue.append(node.rchild) # 入队列
3.数据结构设计、遍历代码
3.1列表法
根据树形图来实现
# 简述:列表里包含三个元素:根结点、左结点、右结点
my_Tree = [
‘D‘, # 根结点
[‘B‘,
[‘F‘,[],[]],
[‘G‘,[‘E‘,[],[]],[]]
], # 左子树
[‘C‘,
[],
[‘A‘,[‘H‘,[],[]],[]]
] # 右子树
]
# 列表操作函数
#POP(0) 函数用于一处列表中的一个元素(默认最后一个元素),并且返回该元素的值。
#insert()函数用于将制定对象插入列表的制定位置,没有返回值。
# 深度优先: 根左右 遍历 (递归实现)
def depth_tree(tree_node):
if tree_node:
print(tree_node[0])
#访问左子树
if tree_node[1]:
depth_tree(tree_node[1]) #递归遍历
#访问右子树
if tree_node[2]:
depth_tree(tree_node[2]) #递归遍历
depth_tree(my_Tree)
执行结果:为纵向搜索
D
B
F
G
E
C
A
H
广度优先: 层次遍历,一层一层遍历(队列实现)
def level_queue(root):
if not root:
return
my_queue = []
node = root
my_queue.append(node) # 根节点入队列
while my_queue:
node = my_queue.pop(0) # 根节点出队列
print(node[0]) #访问节点
if node[1]:
my_queue.append(node[1])
if node[2]:
my_queue.append(node[2])
level_queue(my_Tree)
执行结果:结果为横向搜索
D
B
C
F
G
A
E
H
3.2 构建类节点法
# tree类,类变量root为根节点,为str类型
#类变量right/left 为左右节点,为tree型,默认为空
class Tree:
root = ‘‘
right = None
left = None
# 初始化类
def __init__(self,node):
self.root = node
def set_root(self,node):
self.root = node
def get_root(self):
return self.root
#初始化树
#设置所有根节点
a = Tree(‘A‘)
b = Tree(‘B‘)
c = Tree(‘C‘)
d = Tree(‘D‘)
e = Tree(‘E‘)
f = Tree(‘F‘)
g = Tree(‘G‘)
h = Tree(‘H‘)
# 设置节点之间联系,生成树
a.left = h
b.left = f
b.right = g
c.right = a
d.left = b
d.right = c
g.left = e
#深度优先:根左右 遍历(递归实现)
def depth_tree(tree_node):
if tree_node is not None:
print(tree_node.root)
if tree_node.left is not None:
depth_tree(tree_node.left) # 递归遍历
if tree_node.right is not None:
depth_tree(tree_node.right) # 递归遍历
depth_tree(d) # 传入根节点
执行结果:
D
B
F
G
E
C
A
H
读取顺序
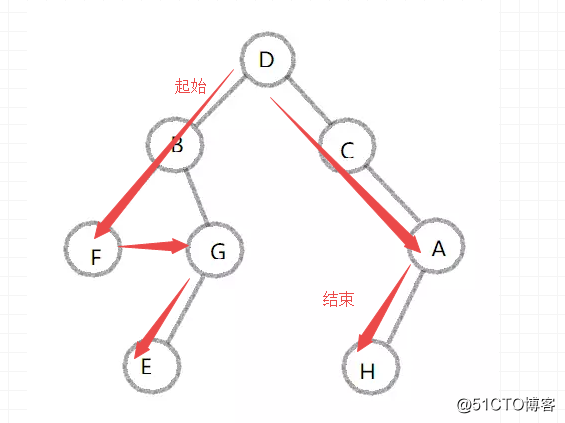
#广度优先:层次遍历,一层一层遍历(队列实现)
def level_queue(root):
if root is None:
return
my_queue = []
node = root
my_queue.append(node)# 根节点入队列
while my_queue:
node = my_queue.pop(0) #出队列
print(node.root) #访问节点
if node.left is not None:
my_queue.append(node.left) #入队列
if node.right is not None:
my_queue.append(node.right) #出队列
level_queue(d)
#result:
结果:
D
B
C
F
G
A
E
H
读取顺序
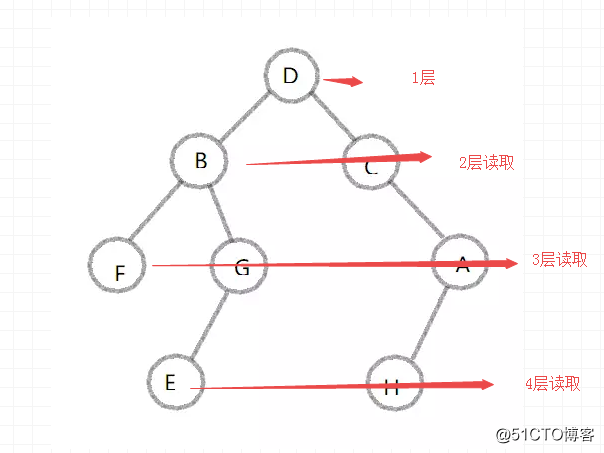
做完深度优先和广度优先策略算法后,返回来讲,主要实现什么?
这两种策略是爬虫系统抓取url的抓取策略,他们决定了爬取的url以什么样的顺序队列进行排列,深度优先就是一条路走到黑,广度优先就是多条并发路线同时进行排列。标签:tree 三层 vpd 算法 col arc jpg none class
原文地址:http://blog.51cto.com/2367685/2349184