标签:数据压缩 输入 loss match 实时 假设 压力 泛化 因子
目录
What:分类目录、搜索引擎、推荐系统
Why:需要在信息过载、用户需求不明确的背景下,留住用户和内容生产者,实现商业目标
准确性
覆盖率
多样性(推荐列表中两两物品的不相似性)、新颖性(未曾关注的类别、作者;推荐结果的平均流行度)、惊喜度(历史不相似(惊)但很满意(喜))
EE:exploitation(选择当前最佳)和exploration(选择效果不确定的)的权衡
商业目标、用户留存、满意度(总体)、信任度、实时性:
鲁棒性、可扩展性:技术问题
实践:离线评估和在线评估相结合,定期做问卷调查
推荐系统架构:收集 - 学习 - 服务 - 反馈 - 收集
Web Api -
Match:
Rank:
矩阵分解算法。用户的点击不同类别的商品,但不代表商品相似。LFM算法根据用户的点击来推测u2i和i2i的关系。
点散矩阵:user和item的矩阵,点击为1,未点击为0,未展示为null。模型迭代是根据user和item有交互的pair来计算的。分解后的向量维度为一超参。
场景:用户toplike、item的topsim、item的topic
数学理论:
\(p^{LFM}(u,i)=\sum_{f=1}^Fp_{uf}q_{if}\) ,loss function:\(\sum_{(u,i)\in D}(p(u,i)-p^{LFM}(u,i))^2+\lambda|p_u|^2\lambda|p_i|^2\)
通过梯度下降求解。
其他参数
与CF的比较
LFM的离线计算空间更小,复杂度比CF稍大,但同一数量级。LFM不能很好地实现实时调整。
代码:下面以python代码作为理解,实践上并非最优,连起码的np的矢量化计算都没有,另外对于大数据,应采用Spark内置的ALS模型进行计算。
def lfm_train(train_data, F, alpha, beta, step):
"""
Args:
train_data: a list: [(userid, itemid, label)...]; label: 0 or 1, dislike or like
F: the dimension of user vector and item vector
alpha: regularization factor
beta: learning rate
step: iteration
Return:
dict: key itemid, value np.array
dict: key userid, value np.array
"""
user_vec, item_vec = init_model(train_data, F)
for step_index in range(step):
for data_instance in train_data:
userid, itemid, label = data_instance
delta = label - model_predict(user_vec[userid], item_vec[itemid])
for index in range(F):
user_vec[userid][index] += beta * (delta * item_vec[itemid][index] - alpha * user_vec[userid][index])
item_vec[itemid][index] += beta * (delta * user_vec[userid][index] - alpha * item_vec[itemid][index])
beta = beta * 0.9
return user_vec, item_vec
def init_model(train_data, vector_len):
user_vec = {}
item_vec = {}
for data_instance in train_data:
userid, itemid, label = data_instance
if userid not in user_vec:
user_vec[userid] = np.random.randn(vector_len)
if itemid not in item_vec:
item_vec[itemid] = np.random.randn(vector_len)
return user_vec, item_vec
def model_predict(user_vector, item_vector):
res = np.dot(user_vector, item_vector) / (np.linalg.norm(user_vector) * np.linalg.norm(item_vector))
return res
def get_recom_result(user_vec, item_vec, userid, result_num):
if userid not in user_vec:
return []
record = {}
recom_list = []
user_vector = user_vec[userid]
for itemid in item_vec:
item_vector = item_vec[itemid]
res = np.dot(user_vector, item_vector) / (np.linalg.norm(user_vector) * np.linalg.norm(item_vector))
record[itemid] = res
for comb in sorted(record.items(), key=_operator.itemgetter(1), reverse=True)[:result_num]:
itemid = comb[0]
score = round(comb[1], 3)
recom_list.append((itemid, score))
return recom_list用户行为容易表示为图。下面的二分图中左边为user,右边为items,连线表示关联(点击、购买等)。根据下面提到的三个指标来判断对与A而言,没有关联的c和e哪个更值得推荐。
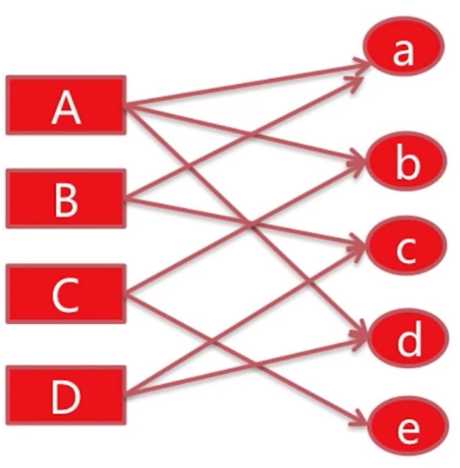
两个顶点之间连通路径数(越多)、长度(总长度越短)、经过顶点的出度(出度和越小)。当第一个因素相同时才考虑下一个。从第一条规则来看,A和c的路径数为2,即AaBc、AdDc;而A和e的路径数为1,即AbCe。第二条略。第三条,AaBc的出度为3+2+2+2.
求解过程:对A进行推荐时,从A开始进行random walk,以alpha的概率从A中等概率选择一条路径,如果到达a,那么继续有alpha的概率继续从a中等概率选择一条路径,或者(1-alpha)的概率回到起点(A),多次迭代后各个顶点对用户A的重要度收敛。alpha为超参,一般0.6~0.8.
数学理论:
PR值为不同item对user的重要度。初始化起点user的PR值为1,其他顶点PR值为0。下面为PR公式的矩阵形式。
\(r=(1-\alpha)r_0+\alpha M^{T}r\),其中\(M_{ij}=\frac{1}{|out(i)|}\ \ if \ \ j\in out(i) \ \ else\ \ 0\)
公式可化简为\(r=(E-\alpha M^T)^{-1}(1-\alpha)r_0\)
代码:略
将用户的行为系列转化为item组成的句子,模仿word2vec训练word embedding将item embedding。
缺陷:用户的行为序列时序性缺失;用户行为序列中的item强度无区分性
流程:
Word2vec Model
CBOW:..., W(t-2), W(t-1), W(t+1), W(t+2),..., 全连接得到W(t)。每个W是一个向量。由于语料库的词很多,t只是其中一个,即正样本1个,n-1个负样本,这样训练的时间会很长,通过负采样的出部分负样本来代替。目标是得到W(t)的概率最大,得到W(非t)的概率最小。
数学理论:
\(g(w)=\prod p(u|Context(w))\),其中\(p(.)=\sigma(X_w^T\theta^u)^{I^w(u)}(1-\sigma(X^T_w\theta^u))^{1-I^w(u)}\),其中I是指示函数,当u=w时为1,反之为0.
\(Loss = log(g(w))=\sum(I^w(u)\times log(\sigma(X_w^T\theta^u))+(1-I^w(u))\times log(1-\sigma(X_w^T\theta^u)))\)
对\(\theta\)和x求导:\(\frac{\partial Loss}{\partial \theta^u}=(I^w(u)-\delta(x_w^T\theta^u))x_w\), \(\frac{\partial Loss}{\partial x_w}=(I^w(u)-\delta(x_w^T\theta^u))\theta^u\)
更新(注意先更新theta):\(\theta^u = \theta^u + \alpha \times \frac{\partial Loss}{\partial \theta^u}\), \(v(w_{context})=v(w_{context})+\sum\alpha \times \frac{\partial Loss}{\partial x_w}\)
Skip Gram:已知W(t),全连接得到..., W(t-2), W(t-1), W(t+1), W(t+2),...。
数学理论:略。
代码:spark有相关工具(略)
可解析性强,跨领域推荐弱。
流程:
Item profile(类别、关键字):Topic Finding、Genre Classify。存储在搜索引擎
User profile:Topic/Genre、Time Decay。存储在kv
Online Recommendation:topk Topic/Genre、best n item from fixed Topic/Genre
代码:例子流程
1.获得电影平均分
2.获取dict1 {itemid: dict {cat: ratio}}
3.获取dict2 {cat:[itemid1, itemid2, ...]},每个cat的topk
4.获取dict3 {userid: [(cat, ratio), (cat, ratio)]},用户的Genre属性。遍历每条数据,只对用户喜欢的电影的数据进行计算(rating大于阈值),根据每条数据中的item的cat来更新user的genre属性
record[userid][fix_cat] += rating * time_score * item_cat[itemid][fix_cat]
取用户genre的topk并归一。time_score由 1/(1+timestamp最大值-当前ts) 得出
5.推荐,需要dict2和3、userid和topk中的k
先遍历dict3,利用num = topk*ratio + 1得出从dict2对应cat中取前num的数量将个性化match的物品候选集根据物品本身属性结合用户属性,上下文等信息给出展现优先级的过程。
rank还可分为PreRank、Rank和ReRank。
model分为单一浅层、组合浅层、深度学习
LR模型
CTR中的benchmark模型。由于线性模型本身的局限,可以进行一些非线性的转换,如连续特征离散化、特征之间的交叉等。
特征工程耗费了大量的精力,而且即使有经验的工程师也很难穷尽所有的特征交叉组合。
数学理论:参考《机器学习总结》
GBDT模型
LR + GBDT
典型的例子就是Facebook 2014年的论文中介绍的通过GBDT模型解决LR模型的特征组合问题。特征工程分为两部分,一部分特征用于训练一个GBDT模型,把GBDT模型每颗树的叶子节点编号作为新的特征,加入到原始特征集中,再用LR模型训练最终的模型。例如x输入到GBDT,其中GBDT有两棵树,产生了分别产生了3个和2个叶子节点,结果之一为[0,1,0,1,0]。这个结果会被作为LR的输入。
GBDT模型能够学习高阶非线性特征组合,对应树的一条路径(叶子节点为1表示出口)。通常把一些连续值特征、值空间不大的categorical特征都丢给GBDT模型(1.树模型不适合学习高度稀疏数据的特征组合,因为效率低,2.而且不能学习很少出现或者没有出现的特征组合);空间很大的ID特征(比如商品ID)留在LR模型中训练,既能做高阶特征组合又能利用线性模型易于处理大规模稀疏数据的优势。
流程:
通过特征对之间的隐变量内积来提取特征组合。这能够克服树模型的第二个缺点,因为即使i和j的组合没有出现过,只要i和l,l和j出现过,那么i和j依旧能建立关系。
FM公式:
\[
y=(w_0 + \sum_{i=1}^{n}w_i x_i) + (\sum_{i=1}^{n}\sum_{j=i+1}^n \langle v_i,v_j \rangle x_i x_j)
\]
优化后计算复杂度为O(kn),效率比树模型快。
上面公式可理解为lr和特征交叉两个部分。特征交叉以User-Item的推荐模型为例,如果用embedding的方式表示,user和item各连接到自己的m维的embedding层,然后embedding层再组合成m个x作为最终\(f\)的输入。
FFM模型是对FM模型的扩展,通过引入field的概念,FFM把相同性质的特征归于同一个field。二次参数由FM的kn个变为kfn个。
alibaba的ctr模型,目标函数为
\[
f(x)=\sum_{i=1}^m \pi_i(x,\mu)\cdot \eta_i(x,w)=\sum_{i=1}^m \frac{e^{\mu_i^T x}}{\sum_{j=1}^m e^{\mu_j^T x}} \cdot \frac{1}{1+e^{-w^Tx}}
\]
其中m为分片数,当m=1时退化为LR。
\(\pi_i(x,\mu)= \frac{e^{\mu_i^T x}}{\sum_{j=1}^m e^{\mu_j^T x}}\)是聚类参数,决定分片空间的划分,即某个样本属于某个特定分片的概率
\(\eta_i(x,w) = \frac{1}{1+e^{-w^Tx}}\)是分类参数,决定分片空间内的预测
\(\mu\) 和 \(w\) 都是待学习的参数。最终模型的预测值为所有分片对应的子模型的预测值的期望。上述模型可以看作是两个embedding,聚类和分类,最后通过内积后加全平均得出预测值。
MLR模型在大规模稀疏数据上探索和实现了非线性拟合能力,在分片数足够多时,有较强的非线性能力;同时模型复杂度可控,有较好泛化能力;同时保留了LR模型的自动特征选择能力。但该模型非凸非光滑,从而不适用传统GD。
Google在2016年paper提出的模型,它分为wide和deep两部分联合训练。单看wide部分与LR模型并没有什么区别;deep部分则是先对不同的ID类型特征做embedding,在embedding层接一个全连接的MLP(多层感知机),用于学习特征之间的高阶交叉组合关系。由于Embedding机制的引入,WDL相对于单纯的wide模型有更强的泛化能力。
有点像LR+GBDT、FM的模式(LR+MF)。
先用FM模型学习到特征的embedding表示,再用学到的embedding向量代替原始特征作为最终模型的特征。
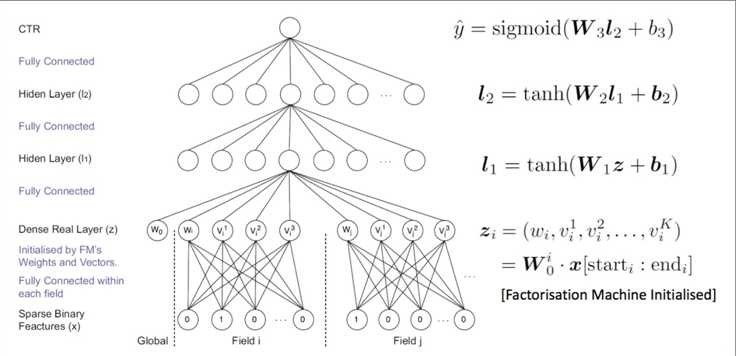
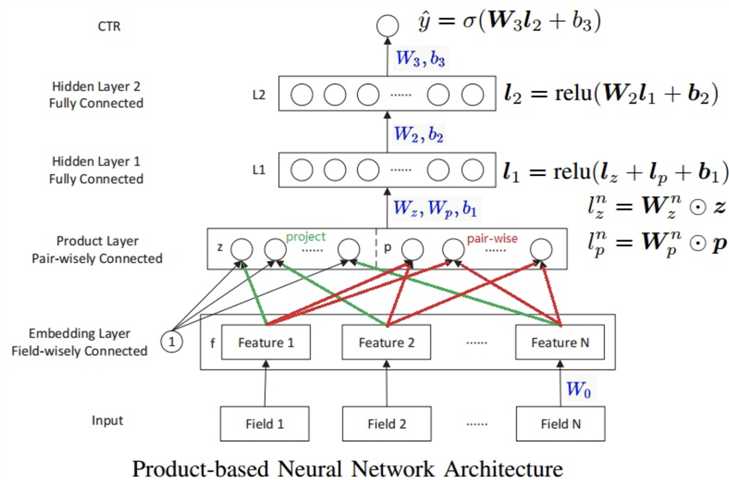
主要关注点在Embedding Layer和Product Layer之间的变化。Embedding Layer和Product Layer之间的权重为常量1,在学习过程中不更新。Product Layer的节点分为两部分,z向量和p向量。z向量的维数与输入层的field个数相同(N)。p向量是pair-wise,经过product操作(分为内积和外积),有N x (N-1)个。这里的\(f_i\)是field i的embedding向量, !\(f_i=W_0^i x[start_i : end_i]\) ,其中 x是输入向量, \(x[start_i : end_i]\)是field i的one-hot编码向量。
深度神经网络对于学习复杂的特征关系非常有潜力。目前也有很多基于CNN与RNN的用于CTR预估的模型。但是基于CNN的模型比较偏向于相邻的特征组合关系提取,基于RNN的模型更适合有序列依赖的点击数据。
DeepFM的结构中包含了因子分解机部分以及深度神经网络部分,分别负责低阶特征的提取和高阶特征的提取。
FM部分:\(y_{FM}=\langle w,x \rangle + \sum_{i=1}^d \sum_{j=i+1}^d \langle V_i,V_j \rangle x_i x_j\) 其中 \(w∈R^d,V_i∈R^k\) 。加法部分反映了一阶特征的重要性,而内积部分反应了二阶特征的影响。
深度部分:\(y_{DNN}=\sigma(W^{H+1} \cdot a^H + b^{H+1})\) 其中H是hidden layer的数量。一个前馈神经网络,在第一层hidden前增加embedding层将数据压缩到底维稠密向量。
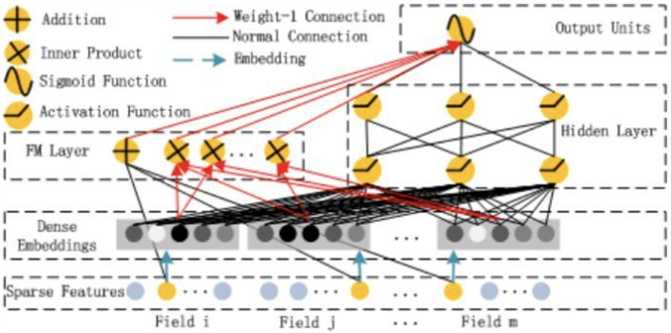
上图中红色箭头所表示的链接权重恒定为1,在训练过程中不更新,可以认为是把节点的值直接拷贝到后一层,再参与后一层节点的运算操作。
与Wide&Deep Model不同,DeepFM共享相同的输入与embedding向量。在Wide&Deep Model中,因为在Wide部分包含了人工设计的成对特征组,所以输入向量的长度也会显著增加,这也增加了复杂性。
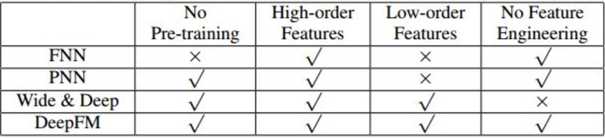
FNN模型首先预训练FM,再将训练好的FM应用到DNN中。PNN网络的embedding层与全连接层之间加了一层Product Layer来完成特征组合。PNN和FNN与其他已有的深度学习模型类似,都很难有效地提取出低阶特征组合。WDL模型混合了宽度模型与深度模型,但是宽度模型的输入依旧依赖于特征工程。
上述模型要不然偏向于低阶特征或者高阶特征的提取,要不然依赖于特征工程。而DeepFM模型可以以端对端的方式来学习不同阶的组合特征关系,并且不需要其他特征工程。
阿里17年论文模型。根据历史行为数据进行两个假设:多样性(一个用户可能对多种品类的东西感兴趣)和部分对应(只有一部分的历史数据对目前的点击预测有帮助,比如点击泳镜会与泳衣产生关联,而对书本关系不大)
DIN设计了一个attention结构,对用户的历史数据和待估算的广告之间部分匹配,从而得到一个权重值,用来进行embedding间的加权求和。
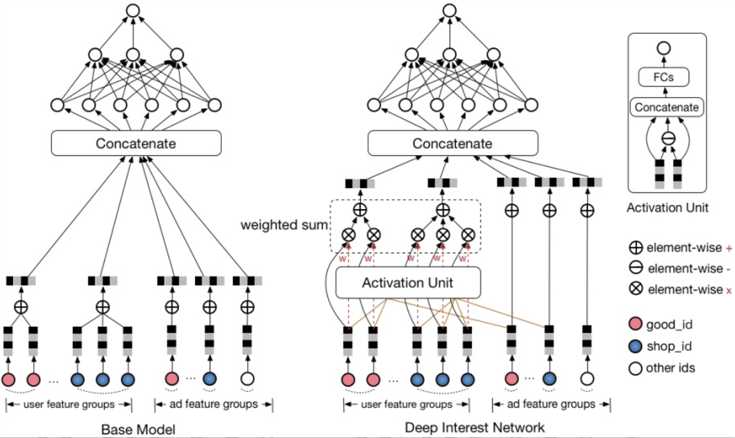
用户特征由用户历史行为的不同实体ID序列组成。在对用户的表示计算上引入了attention network (也即图中的Activation Unit) 。DIN把用户特征、用户历史行为特征进行embedding操作,视为对用户兴趣的表示,之后通过attention network,对每个兴趣表示赋予不同的权值。这个权值是由用户的兴趣和待估算的广告进行匹配计算得到的。
Attention network 的公式:\(V_u=f(V_a)=\sum_{i=1}^N w_i \cdot V_i =\sum_{i=1}^N g(V_i,V_a) \cdot V_i\) 其中,V_u 代表用户表示向量, V_i 是用户行为 i 的embedding向量,V_a代表广告的表示向量。核心在于用户的表示向量不仅仅取决于用户的历史行为,而且还与待评估的广告有直接的关联。
google 和 Stanford 在2017年的paper提出。模型对sparse和dense的输入自动学习特征交叉,可以有效地捕获有限阶(bounded degrees)上的有效特征交叉,无需人工特征工程或暴力搜索(exhaustive searching),并且计算代价较低。
模型结构如下:
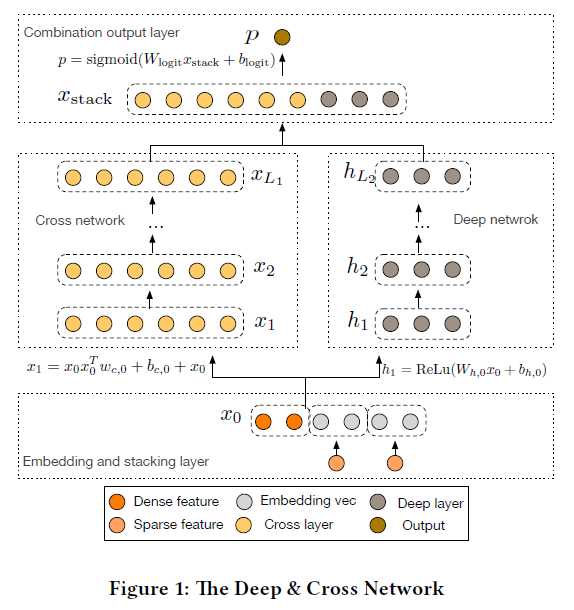
Cross network:目的是有效地应用显式特征交叉。
公式:\(x_{l+1} = x_0 x_l^T w_l + b_l + x_l = f(x_l, w_l, b_l) + x_l\),由公式可知,the degress of cross features随着layer的深入而增加。涉及的参数数量为\(d \times L \times 2\),其中d为x的维度数,L为层数。
cross network的复杂度和传统的DNN在同一水平上,因为$ x_0 x_l^T$的实现避免存储/计算整个matrix
Deep network:目的是捕获高阶非线性交叉。
公式:\(h_{l+1} = f(W_l h_l + b_l)\)
涉及参数数量:\(d×m+m+(m^2+m)×(L_d?1)?\)
代码:基于Spark和Tensorflow构建DCN模型进行CTR预测
参考:
镶嵌在互联网技术上的明珠:漫谈深度学习时代点击率预估技术进展
玩转企业级Deep&Cross Network模型你只差一步
标签:数据压缩 输入 loss match 实时 假设 压力 泛化 因子
原文地址:https://www.cnblogs.com/code2one/p/10366238.html