标签:注意 groovy 步骤 regexp 链接 ash 影响 快捷 情况
来,先来看小漫画陶冶一下情操
OK,这里就说了。假设,你有一个表erp,如果你直接进行下面的命令
drop table erp这个时候所有的mysql的相关进程都会停止,直到drop结束,mysql才会恢复执行。出现这个情况的原因就是因为,在drop table的时候,innodb维护了一个全局锁,drop完毕锁就释放了。
这意味着,如果在白天,访问量非常大的时候,如果你在不做任何处理措施的情况下,执行了删大表的命令,整个mysql就挂在那了,在删表期间,QPS会严重下滑,然后产品经理就来找你喝茶了。所以才有了漫画中的一幕,你可以在晚上十二点,夜深人静的时候再删。
当然,有的人不服,可能会说:"你可以写一个删除表的存储过程,在晚上没啥访问量的时候运行一次就行。"
我内心一惊,细想一下,只能说:"大家还是别抬杠了,还是听我说一下业内通用做法。"
先说明一下,在这里有一个前提,mysql开启了独立表空间,MySQL5.6.7之后默认开启。
也就是在my.cnf中,有这么一条配置(这些是属于mysql优化的知识,后期给大家介绍)
innodb_file_per_table = 1查看表空间状态,用下面的命令
mysql> show variables like ‘%per_table‘;
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_file_per_table | OFF |
+-----------------------+-------+如果innodb_file_per_table的value值为OFF,代表采用的是共享表空间。
如果innodb_file_per_table的value值为ON ,代表采用的是独立表空间。
于是,大家要问我,独立表空间和共享表空间的区别?
共享表空间:某一个数据库的所有的表数据,索引文件全部放在一个文件中,默认这个共享表空间的文件路径在data目录下。 默认的文件名为:ibdata1(此文件,可以扩展成多个)。注意,在这种方式下,运维超级不方便。你看,所有数据都在一个文件里,要对单表维护,十分不方便。另外,你在做delete操作的时候,文件内会留下很多间隙,ibdata1文件不会自动收缩。换句话说,使用共享表空间来存储数据,会遭遇drop table之后,空间无法释放的问题。
独立表空间:每一个表都以独立方式来部署,每个表都有一个.frm表描述文件,还有一个.ibd文件。
.frm文件:保存了每个表的元数据,包括表结构的定义等,该文件与数据库引擎无关。
.ibd文件:保存了每个表的数据和索引的文件。
注意,在这种方式下,每个表都有自已独立的表空间,这样运维起来方便,可以实现单表在不同数据库之间的移动。另外,在执行drop table操作的时候,是可以自动回收表空间。在执行delete操作后,可以通过alter table TableName engine=innodb可以整理碎片,回收部分表空间。
ps:my.cnf中的datadir就是用来设置数据存储目录
好了,上面巴拉巴拉了一大堆,我只想说一个事情:
在绝大部分情况下,运维一定会为mysql选择独立表空间的存储方式,因为采用独立表空间的方式,从性能优化和运维难易角度来说,实在强太多。
所以,我在一开始所提到的前提,mysql需要开启独立表空间。这个假设,百分九十的情况下是成立的。如果真的遇到了,你们公司的mysql采用的是共享表空间的情况,请你和你们家的运维谈谈心,问问为啥用共享表空间。
假设,我们有datadir = /data/mysql/,另外,我们有有一个database,名为mytest。在数据库mytest中,有一个表,名为erp,执行下列命令
mysql> system ls -l /data/mysql/mytest/得到下面的输出(我过滤了一下)
-rw-r----- 1 mysql mysql 9023 8 18 05:21 erp.frm
-rw-r----- 1 mysql mysql 2356792000512 8 18 05:21 erp.ibdfrm和ibd的作用,上面介绍过了。现在就是erp.ibd文件太大,所以删除卡住了。
如何解决这个问题呢?
这里需要利用了linux中硬链接的知识,来进行快速删除。下面容我上《鸟哥的私房菜》中的一些内容,
软链接其实大家可以类比理解为windows中的快捷方式,就不多介绍了,主要介绍一下硬链接。
至于这个硬链接,我简单说一下,不想贴一大堆话过来,看起来太累。
就是对于真正存储的文件来说,有一个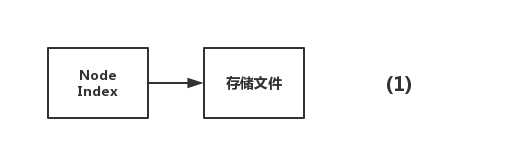
然后呢有一个文件名指向上面的node Index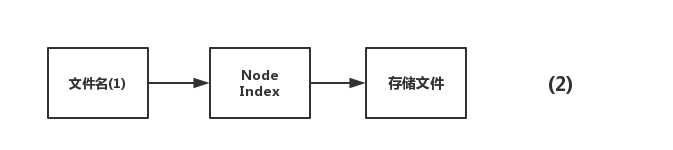
那么,所谓的硬链接,就是不止一个文件名指向node Index,有好几个文件名指向node Index。
假设,这会又有一个文件名指向上面的node Index,即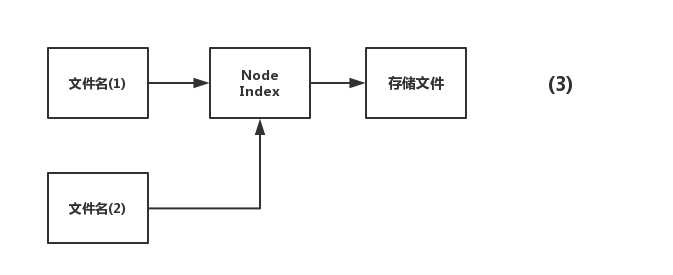
这个时候,你做了删除文件名(1)的操作,linux系统检测到,还有一个文件名(2)指向node Index,因此并不会真正的把文件删了,而是把步骤(2)的引用给删了,这步操作非常快,毕竟只是删除引用。于是图就变成了这样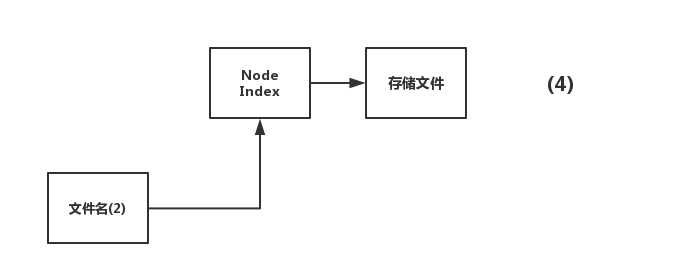
接下来,你再做删除文件名(2)的操作,linux系统检测到,没有其他文件名指向该node Index,就会删除真正的存储文件,这步操作,是删真正的文件,所以比较慢。
OK,我们用的就是上面的原理。
先给erp.ibd建立一个硬链接,利用ln命令
mysql> system ln /data/mysql/mytest/erp.ibd /data/mysql/mytest/erp.ibd.hdlk 此时,文件目录如下所示
-rw-r----- 1 mysql mysql 9023 8 18 05:21 erp.frm
-rw-r----- 2 mysql mysql 2356792000512 8 18 05:21 erp.ibd
-rw-r----- 2 mysql mysql 2356792000512 8 18 05:21 erp.ibd.hdlk 你会发现,多了一个erp.ibd.hdlk文件,且erp.ibd和erp.ibd.hdlk的inode均为2。
此时,你执行drop table操作
mysql> drop table erp;
Query OK, 0 rows affected (0.99 sec)你会发现,不到1秒就删除了。因为,此时有两个文件名称(erp.ibd和erp.ibd.hdlk),同时指向一个inode.这个时候,执行删除操作,只是把引用给删了,所以非常快。
那么,这时的删除,已经把table从mysql中删除。但是磁盘空间,还没释放,因为还剩一个文件erp.ibd.hdlk。
如何正确的删除erp.ibd.hdlk呢?
如果你没啥经验,一定会回答我,用rm命令来删。这里需要说明的是,在生产环境,直接用rm命令来删大文件,会造成磁盘IO开销飙升,CPU负载过高,是会影响其他程序运行的。
那么,这种时候,就是应该用truncate命令来删,truncate命令在coreutils工具集中。
详情,大家可以去百度一下,有人对rm和truncate命令,专程测试过,truncate命令对磁盘IO,CPU负载几乎无影响。
删除脚本如下
TRUNCATE=/usr/local/bin/truncate
for i in `seq 2194 -10 10 `;
do
sleep 2
$TRUNCATE -s ${i}G /data/mysql/mytest/erp.ibd.hdlk
done
rm -rf /data/mysql/mytest/erp.ibd.hdlk ;从2194G开始,每次缩减10G,停2秒,继续,直到文件只剩10G,最后使用rm命令删除剩余的部分。
这里指的是,如果数据库是部署在windows上怎么办。这个问题,我来回答,其实不够专业。因为我出道以来,还没碰到过,生产环境上,mysql是部在windows上的。假设真的碰到了,windows下有一个工具叫mklink,是在windows下创建硬链接锁用,应该能完成类似功能
标签:注意 groovy 步骤 regexp 链接 ash 影响 快捷 情况
原文地址:https://www.cnblogs.com/liliuguang/p/10368946.html