标签:题目 时间性能 检测 效率 number 科研 3.4 out 五个
常用的几种数据结构
数据的逻辑结构常分为四大类:
(1)集合结构
(2)线性结构
(3)树形结构
(4)图结构(网结构)
存储结构可以分为:连续存储和链式存储。连续存储又可以分为:静态存储和动态存储
连续存储和链式存储比较
顺序存储的优点:
(1) 方法简单,各种高级语言中都提供数组结构,容易实现。
(2) 不用为表示结点间的逻辑关系而增加额外的存储开销。
(3) 顺序表具有按元素序号随机访问的特点。
顺序存储的缺点:
(1) 在顺序表中做插入删除操作时,平均移动大约表中一半的元素,因此对n较大的顺序表效率低。
(2) 需要预先分配足够大的存储空间,估计过大,可能会导致顺序表后部大量闲置;预先分配过小,又会造成溢出。
在选取存储结构时权衡因素有:
1)基于存储的考虑
顺序表的存储空间是静态分配的,在程序执行之前必须明确规定它的存储规模,也就是说事先对“MAXSIZE”要有合适的设定,过大造成浪费,过小造成溢出。可见对线性表的长度或存储规模难以估计时,不宜采用顺序表;链表不用事先估计存储规模,但链表的存储密度较低,
2)基于运算的考虑
在顺序表中按序号访问ai的时间性能时O(1),而链表中按序号访问的时间性能O(n),所以如果经常做的运算是按序号访问数据元素,显然顺序表优于链表;
3)基于环境的考虑
顺序表容易实现,任何高级语言中都有数组类型,链表的操作是基于指针的,操作简单。
【例1】某次选举,要从五个候选人(编号分别为1、2、3、4、5)中选一名厂长。请编程完成统计选票的工作。
算法设计:
1)虽然选票发放的数量一般是已知的,但收回的数量通常是无法预知的,所以算法采用随机循环,设计停止标志为“-1”。
2)统计过程的一般方法为:先为五个候选人各自设置五个“计数器”S1,S2,S3,S4,S5,然后根据录入数据通过多分支语句或嵌套条件语句决定为某个“计数器”累加1, 这样做效率太低。
现在把五个“计数器”用数组代替,选票中候选人的编号xp正好做下标,执行A(xp)=A(xp)+1就可方便地将选票内容累加到相应的“计数器”中。也就是说数组结构是存储统计结果的,而其下标正是原始信息。
3)考虑到算法的健壮性,要排除对1——5之外的数据进行统计。
算法如下:
vote( )
{ int i,xp,a[6];
print(“input data until input -1”);
input(xp );
while(xp!=-1)
{if (xp>=1 and xp<=5 )
a[xp]=a[xp]+1;
else
print(xp, "input error!");
input(xp );
}
for (i=1;i<=5;i++)
print(i,"number get", a[i], "votes");
}
【例2】编程统计身高(单位为厘米)。统计分150——154;155——159;160——164;165——169;170——174;175——179及低于是150、高于是179共八档次进行。
算法设计:
输入的身高可能在50——250之间,若用输入的身高数据直接作为数组下标进行统计,即使是用PASCAL语言可设置上、下标的下界,也要开辟200多个空间,而统计是分八个档次进行的,这样是完全没有必要的。
由于多数统计区间的大小是都固定为5,这样用“身高/5-29”做下标,则只需开辟8个元素的数组,对应八个统计档次,即可完成统计工作。
算法如下:
main( )
{ int i,sg,a[8];
print(“input height data until input -1”);
input(sg );
while (sg<>-1)
{if (sg>179) a[7]=a[7]+1;
else
if (sg<150) a[0]=a[0]+1;
else a[sg/5-29]=a[sg/5-29]+1;
input( sg );
}
for (i=0;i<=7;i=i+1)
print(i+1 ,“field the number of people: ”,a[i]);
}
【例3】一次考试共考了语文、代数和外语三科。某小组共有九人,考后各科及格名单如下表,请编写算法找出三科全及格的学生的名单(学号)。
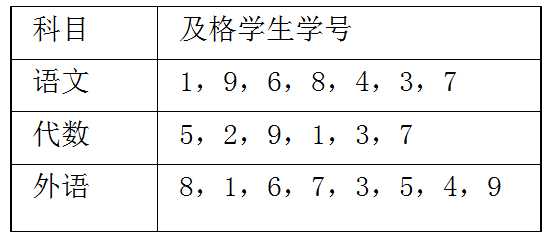
方法一:
从语文及格名单中逐一抽出各及格学生学号,先在代数及格名单核对,若有该学号(说明代数也及格了),再在外语及格名单中继续查找,看该学号是否也在外语及格名单中。若仍在,说明该号属全及格学生的学号,否则就是至少有一科不及格的。若语文及格名单中就没有某生的号,显然该生根本不在比较之列,自然不属全及格学生 。
该方法采用了枚举尝试的方法
A,B,C三组分别存放语文、代数、外语及格名单,尝试范围为三重循环:
I循环, 初值0, 终值6, 步长1
J循环, 初值0, 终值5, 步长1
K循环, 初值0, 终值7, 步长1
定解条件:
A[I]=B[J]=C[K]
共尝试7*6*8=336次。
方法一算法如下:
main( )
{int a[7], b[6], c[8],i,j,k,v,flag;
for( i =0;i<=6;i=i+1) input(a[i]);
for( i =0;i<=5;i=i+1) input(b[i]);
for( i =0;i<=7;i=i+1) input(c[i]);
for( i =0;i<=6;i=i+1)
{v=a[i];
for( j =0;j<=5;j=j+1)
if ( b[j]=v )
for(k =0;k<=7;k=k+1)
if(c[k]=v)
{print(v); break;}
}
}
方法二 :
用数组A的九个下标分量作为各号考生及格科目的计数器。将三科及格名单共存一个数组,当扫描完毕总及格名单后,凡下标计数器的值为3的就是全及格的,其余则至少有一科不及格的。
该方法同样也采用了枚举尝试的方法。
算法步骤为:
1)用下标计数器累加各学号学生及格科数,
2)尝试、输出部分。
累加部分为一重循环,初值1 ,终值为三科及格的总人数,包括重复部分。计7+6+8=21,步长1。
尝试部分的尝试范围为一重循环,初值1 ,终值9,步长1。
定解条件:A(i)=3
方法二算法如下:
main( )
{int a[10],i,xh;
for(i =1;i<=21;i=i+1)
{input(xh);
a[xh]=a[xh]+1;}
for(xh =1;xh<=9;xh=xh+1)
if(a[xh] =3 )
print(xh);
}
【例4】统计找数字对的出现频率
算法说明:
输入N(2≤N≤100)个数字(在0与9之间),然后统计出这组数中相邻两数字组成的链环数字对出现的次数。例如:
输入:N=20 {表示要输入数的数目}
0 1 5 9 8 7 2 2 2 3 2 7 8 7 8 7 9 6 5 9
输出:(7,8)=2 (8,7)=3 {指(7,8)、(8,7)数字对出现次数分别为2次、3次
(7,2)=1 (2,7)=1
(2,2)=2
(2,3)=1 (3,2)=1
算法设计:
其实并不是只有一维数组这样的数据结构可以在算法设计中有多采的应用,根据数据信息的特点,二维数组的使用同样可以使算法易于实现,此题就正是如此。
用10*10的二维数组(行、列下标均为0-9),存储统计结果,i行j列存储数字对(i,j)出现的次数,无需存储原始数据,用其做下标,在数据输入的同时就能统计出问题的结果,
算法如下:
main( )
{int a[10][10],m,i,j,k1,k0;
print(“How many is numbers?”);
input(n);
print(“Please input these numbers:”);
input(k0);
for (i=2;i<=n;i=i+1)
{input(k1); a[k0][k1]=a[k0][k1]+1; k0=k1;}
for (i=0;i<=9;i=i+1)
for (j=0;j<=9;j=j+1)
if (a[i][j]<>0 and a[j][i]<>0); print(“(”,i,j,”)=“,a[i][j],”,(”,j,i,”)=”,a[j][i])
}
数组使信息有序化
当题目中的数据缺乏规律时,很难把重复的工作抽象成循环不变式来完成,但先用数组结构存储这些地信息后,问题就迎刃而解了,
【例1】编程将编号“翻译”成英文。例35706“翻译”成three-five-seven-zero-six。
算法设计1:
算法设计1:
1) 编号一般位数较多,可按长整型输入和存储。
2) 将英文的“zero——nine”存储在数组中,对应下标为0——9。这样无数值规律可循的单词,通过下标就可以方便存取、访问了。
3) 通过求余、取整运算,可以取到编号的各个位数字。用这个数字作下标,正好能找到对应的英文数字。
4)考虑输出翻译结果是从高位到低位进行的,而取各位数字,比较简单的方法是从低位开始通过求余和整除运算逐步完成的。所以还要开辟一个数组来存储从低位到高位翻译好的结果,并记录编号的位数,最后倒着从高位到低位输出结果。
算法如下:
main( )
{int i,a[10], ind; long num1,num2;
char eng[10][6]={“zero”,”one”,”two”,”three ”,” four”,
” five”,”six”,”seven”,“eight”,”nine”};
print(“Input a num”);
input(num1); num2=num1; ind =0;
while (num2<>0)
{a[ind]=num2 mod 10; ind= ind +1; num2=num2/10; }
print(num1, “English_exp:”, eng[a[ind-1]]);
for( i=ind-2;i>=0;i=i-1)
print(“-”,eng[a[i]]);
}
【例2】一个顾客买了价值x元的商品,并将y元的钱交给售货员。售货员希望用张数最少的钱币找给顾客。
问题分析:无论买商品的价值x是多大,找给他的钱最多需要以下六种币值:50,20,10,5,2,1。
算法设计:
1)为了能达到找给顾客钱的张数最少,先尽量多地取大面额的币种,由大面额到小面额币种逐渐进行。
2)六种面额不是等到差数列,为了能构造出循环不变式,将六种币值存储在数组B。这样,六种币值就可表示为B[i],i=1,2,3,4,5,6。为了能达到先尽量多地找大面额的币种,六种币值应该由大到小存储。
3)另外还要为统计六种面额的数量,同样为了能构造出循环不变式,设置一个有六个元素的累加器数组S,这样操作就可以通过循环顺利完成了。
算法如下:
main( )
{int i,j,x,y,z,a,b[7]={0,50,20,10,5,2,1},s[7];
input(x,y);
z=y-x;
for(i=1;i<=6;i=i+1)
{a=z\b[i]; s[i]=s[i]+a; z=z-a*b[i];}
print(y,”-”x,”=”,z:);
for(i=1;i<=6;i=i+1)
if (s[i]<>0)
print(b[i], “----”, s[i]);
}
算法说明:
1)每求出一种面额所需的张数后,一定要把这部分金额减去: “y=y-A*B[j];”,否则将会重复计算。
2)算法无论要找的钱z是多大,我们都从50元开始统计,所以在输出时要注意合理性,不要输出无用的张数为0 的信息。
算法分析:问题的规模是常量,时间复杂性肯定为O(1)。
数组记录状态信息
问题提出:
有的问题会限定在现有数据中,每个数据只能被使用一次,怎么样表示一个数据“使用过”还是没有“使用过”?
一个朴素的想法是:用数组存储已使用过的数据,然后每处理一个新数据就与前面的数据逐一比较看是否重复。这样做,当数据量大时,判断工作的效率就会越来越低。
【例1】求X,使X2为一个各位数字互不相同的九位数。
分析:只能用枚举法尝试完成此题。由X2为一个九位数,估算X应在10000——32000之间。
算法设计:
1) 用一个10 个元素的状态数组p,记录数字0——9在X2中出现的情况。数组元素都赋初值为1,表示数字0——9没有被使用过。
2) 对尝试的每一个数x,求x*x,并取其各个位数字,数字作为数组的下标,若对应元素为1,则该数字第一次出现,将对应的元素赋为0,表示该数字已出现一次。否则,若对应元素为0,则说明有重复数字,结束这次尝试。
3) 容易理解当状态数组p中有9个元素为0时,就找到了问题的解。但这样判定有解,需要扫描一遍数组p。为避免这个步骤,设置一个计数器k,在取x*x各个位数字的过程中记录不同的数字的个数,当k=9时就找到了问题的解。
算法如下:
main( )
{long x, y1, y2; int p[10], 2, i, t, k, num=0;
for (x=10000;x<32000; x=x+1)
{ for(i=0; i<=9; i=i+1) p[i]=1;
y1=x*x ; y2=y1; k=0;
for(i=1; i<=9. i=i+1)
{t=y2 mod 10;
y2=y2/10;
if(p[t]=1) {k=k+1; p[t]=0;}
else break;
}
if(k=9)
{num=num+1;
print (“No.”,num , “:n=”, x, “n2=”, y1);}
}
}
【例2】游戏问题:
12个小朋友手拉手站成一个圆圈,从某一个小朋友开始报数,报到7的那个小朋友退到圈外,然后他的下一位重新报“1”。这样继续下去,直到最后只剩下一个小朋友,求解这个小朋友原来站在什么位置上呢?
算法设计:
这个问题初看起来很复杂,又是手拉手,又是站成圈,报数到7时退出圈……似乎很难入手。
细细分析起来,首先是如何表示状态的问题。开辟12个元素的数组,记录12个小朋友的状态,开始时将12个元素的数组值均赋为1,表示大家都在圈内。这样小朋友报数就用累加数组元素的值来模拟,累加到7时,该元素所代表的小朋友退到圈外,将相应元素的值改赋为0,这样再累加到该元素时和不会改变,又模拟了已出圈外的状态。
为了算法的通用性,算法允许对游戏的总人数、报数的起点、退出圈外的报数点任意输入。其中n表示做游戏的总人数,k表示开始及状态数组的下标变量,m表示退出圈外的报数点,即报m的人出队,p表示已退出圈外的人数。
算法如下:
main( )
{int a[100],i,k,p,m;
print(“input numbers of game:”);
input(n);
print(“input serial number of game start:”);
input(k);
print(“input number of out_ring:”);
input(m);
for( i=1;i<=n;i++)
a[i]=1;
p=0;
while (p<n-1)
{x=0;
while x<m
{k=k+1;
if(k>n) k=1;
x=x+a[k];}
print(k);
a[k]=0;
p=p+1;
}
for( i=1;i<=n;i++)
if ( a[i]=1)
print( “i=”,i);
}
算法说明:
1) 算法中当变量k >n时,赋k=1,表示n号报完数就该1号报数。模拟了将n个人连成了一个“圈”的情况(2.10“算术运算的妙用”中还介绍了其它技巧,请参考)。
2) x为“报”出的数,x=m时输出退出圈外人的下标k,将a[k]赋值为0;
3) p=n-1时游戏结束;
4) 最后检测还在圈上a[i]=1的人,输出其下标值即编号(原来位置)。
思考:可选择顺时针或反时针方向报数。
大整数的存储及运算
计算机存储数据是按类型分配空间的。在微型机上为整型提供2个字节16位的存储空间,则整型数据的范围为-32768——32767;为长整型提供4个字节32位的存储空间,则长整型数据的范围为-2147483648——2147483647;为实型也是提供4个字节32位的存储空间,但不是精确存储数据,只有六位精度,数据的范围±(3.4e-38~3.4e+38) ;为双精度型数据提供8个字节64位的存储空间,数据的范围±(1.7e-308~1.7e+308),其精确位数是17位。
虽然现在工作站或小型机等机型上都有更高精度的数值类型,但这些机型价格昂贵,只有大型科研机构才有可能拥有,一般不易接触。当我们需要在个人机上,对超过长整型的多位数(简称为“高精度数据”)操作时,只能借助于数组才能精确存储、计算。
在用数组存储高精度数据时,从计算的方便性考虑,决定将数据是由低到高还是由高到低存储到数组中;可以每位占一个数组元素空间,也可几位占一个数组元素空间。
若需从键盘输入要处理的高精度数据,一般用字符数型组存储,这样无需对高精度数据进行分段输入。当然这样存储后,需要有类型转换的操作,不同语言转换的操作差别虽然较大,但都是利用数字字符的ASCII码进行的。其它的技巧和注意事项通过下面的例子来说明。本节只针对大 整数的计算进行讨论,对高精度实数的计算可以仿照进行。
【例】编程求当N<=100时,N!的准确值
问题分析:问题要求对输入的正整数N,计算N!的准确值,而N!的增长速度仅次于指数增长的速度,所以这是一个高精度计算问题。
例如:
9!=362880
100! = 93 326215 443944 152681 699263
856266 700490 715968 264381 621468 592963
895217 599993 229915 608914 463976 156578
286253 697920 827223 758251 185210 916864
000000 000000 000000 000000
算法设计:
1)乘法的结果是按由低位到高位存储在数组ab中,由于计算结果位数太多,若存储结果的数组,每个存储空间只存储一位数字,对每一位进行累乘次数太多。所以将数组定义为长整型,每个元素存储六位。
2)对两个高精度数据的乘法运算,比较简单的方法就是两个高精度数据的按元素交叉相乘,用二重循环来实现。其中一个循环变量i代表累乘的数据,b存储计算的中间结果,数组ab存储每次累乘的结果,每个元素存储六位数据,d存储超过六位数后的进位。
算法如下:
main( )
{long ab[256],b,d; int m,n,i,j,r;
input(n);
m=log(n)*n/6+2; ab[1]=1;
for( i=2; i<=m;i++)
ab[i]=0;
d=0;
for( i=2; i<=n;i++)
for (j=1;j<=m;j++)
{b=ab[j]*i+d; ab[j]=b%1000000; d=b/1000000;}
for (i=m ;i>=1;i--)
if( ab[i]==0) continue;
else {r=i; break;}
print(n,“!=”); print(ab[r]);
for(i=r-1;i>=1;i--)
{if (ab[i]>99999) {print(ab[i]); continue;}
if (ab[i]>9999) {print( “0”,ab[i]); continue;}
if (ab[i]> 999) {print( “00”,ab[i]); continue;}
if (ab[i]>99 ) {print( “000”,ab[i]); continue;}
if (ab[i]>9) {print( “0000”,ab[i]); continue;}
print( “00000”,ab[i]);
}//for
}
算法说明:
1)算法中“m=log(n)*n/6+2;”是对N!位数的粗略估计。
2)输出时,首先计算结果的准确位数r,然后输出最高位数据,在输出其它存储单元的数据时要特别注意,如若计算结果是123000001,ab[2]中存储的是123,而ab[1]中存储的不是000001,而是1。所以在输出时,通过多个条件语句保证输出的正确性。
构造趣味矩阵
趣味矩阵 经常用二维数组来解决
根据趣味矩阵中的数据规律,设计算法把要输出的数据存储到一个二维数组中,最后按行输出该数组中的元素。
基本常识:
1)当对二维表按行进行操作时,应该“外层循环控制行;内层循环控制列”;反之若要对二维表按列进行操作时,应该“外层循环控制列;内层循环控制行”。
2)二维表和二维数组的显示输出,只能按行从上到下连续进行,每行各列则只能从左到右连续输出。所以,只能用“外层循环控制行;内层循环控制列”。
3)用i代表行下标,以j代表列下标(除特别声明以后都遵守此约定),则对n*n矩阵有以下常识:
主对角线元素i=j;
副对角线元素: 下标下界为1时 i+j=n+1,
下标下界为0时i+j=n-1;
主上三角◥元素: i <=j;
主下三角◣元素: i >=j;
次上三角◤元素:下标下界为1时i +j<=n+1,
下标下界为0时i+j<=n-1;
次下三角◢元素:下标下界为1时i +j>=n+1,
下标下界为0时i+j>=n-1;
【例1】编程打印形如下规律的n*n方阵。
例如下图:使左对角线和右对角线上的元素为0,它们上方的元素为1,左方的元素为2,下方元素为3,右方元素为4,下图是一个符合条件的阶矩阵。
0 1
1 1 0
2 0
1 0 4
2 2
0 4 4
2 0
3 0 4
0 3
3 3 0
算法设计:根据数据分布的特点,利用以上关于二维数组的基本常识,在只考虑可读性的情况下,
算法如下:
main( )
{int i,j,a[100][100],n;
input(n);
for(i=1;i<=n;i=i+1)
for(j=1;j<=n;j=j+1)
{if (i=j or i+j=n+1) a [i][j]=0;
if (i+j<n+1 and i<j) a [i][j]=1;
if (i+j<n+1 and i>j) a [i][j]=2;
if (i+j>n+1 and i>j) a [i][j]=3;
if (i+j>n+1 and i<j) a [i][j]=4;}
for(i=1;i<=n;i=i+1)
{print( “换行符”);
for( j=1;j<=n;j=j+1)
print(a[i][j]);
}
}
【例2】螺旋阵:任意给定n值,按如下螺旋的方式输出方阵:
n=3 输出:
1 8 7
2 9 6
3 4 5
n=4 输出:
1 12 11 10
2 13 16 9
3 14 15 8
4 5 6 7
算法设计:
算法设计1:此例可以按照“摆放”数据的过程,逐层(圈)分别处理每圈的左侧、下方、右侧、上方的数据。以n=4为例详细设计如下:
把“1——12”看做一层(一圈)“13-16”看做二层……以层做为外层循环,下标变量为i。由以上两个例子,n=3、4均为两层,用n\2表示下取整,这样(n+1)/2下好表示对n/2上取整。所以下标变量i的范围1——(n+1)/2。
i层内“摆放”数据的四个过程为(四角元素分别归四个边):
1) i列(左侧),从i行到n-i行
( n=4,i=1时 “摆放1,2,3”)
2) n+1-i行(下方),从i列到n-i列
( n=4,i=1时 “摆放4,5,6”)
3) n+1-i列(右侧),从n+1-i行到i+1行
( n=4,i=1时 “摆放7,8,9”)
4) i行(上方),从n+1-i列到i+1列
( n=4,i=1时 “摆放10,11,12”)
四个过程通过四个循环实现,用j表示i层内每边中行或列的下标。
算法如下:
main( )
{int i,j,a[100][100],n,k;
input(n); k=1;
for(i=1;i<=n/2;i=i+1)
{for( j=i;j<=n-i;j=j+1) { a [j][i]=k; k=k+1;} /左侧/
for( j=i;j<=n-i;j=j+1) {a [n+1-i][j]=k; k=k+1;} /下方/
for( j= n-i+1;j>=i+1;j=j-1){a[j][n+1-i]=k;k=k+1;} /右侧/
for( j= n-i+1;j>=i+1;j=j-1) {a[i][j]=k; k=k+1;} /上方/
}
if (n mod 2=1)
{i=(n+1)/2; a[i][i]=n*n;}
for(i=1;i<=n;i=i+1)
{print(“换行符”);
for( j=1;j<=n;j=j+1)
print(a[i][j]);
}
}
算法设计2为了用统一的表达式表示循环变量的范围,引入变量k,k表示在某一方向的上数据的个数,k的初值是n,每当数据存放到左下角时,k就减1,又存放到右上角时,k又减1;此时的k 值又恰好是下一圈左侧的数据个数。
同样,为了将向下和向上“摆放”数据时,行下标i 的变化用统一的表达式表示;同时也将向右向左“摆放”数据时, 列下标j的变化用统一的表达式表示。引入符号变量t,t的初值为1,表示处理前半圈:左侧i向下变大,j向右变大;t就变为-1;表示处理后半圈:右侧i向上变小,j向左变小。于是一圈内下标的变化情况如下:
j=1 i=i+t 1----n
i=n j=j+t 2----n 前半圈共2*k-1个
t= -t k=k-1
j=n i=i+t n-1----1
i=1 j=j+t n-1----2 后半圈共2*k-1个
t= -t
用x模拟“摆放”的数据;用y(1——2*k-1)作循环变量,模拟半圈内数据的处理的过程。
算法如下:
main( )
{int i,j,k,n,a[100][100],b[2],x,y;
b[0]=0; b[1]=1; k=n; t=1; x=1;
while x<=n*n
{for (y=1;y<=2*k-1;y++) // t=1时处理左下角
{ b[y/(k+1)]=b[y/(k+1)]+t; //t= -1时处理右上角
a[b[0]][b[1]]=x;
x=x+1;}
k=k-1; t=-t;
}
for( i=1;i<=n;i++)
{print(“换行符”);
for(j=1;j<=n;j++)
print(a[i][j]);
}
}
算法说明:
在“算法设计”中我们没有介绍数组b,由算法中的“a[b[0]][b[1]]=x;”语句可以体会到,数组元素b[0]表示存储矩阵的数组a的行下标,数组元素b[1]是数组a的列下标。那么为什么不用习惯的i,j作行、列的下标变量呢?使用数组元素作下标变量的必要性是什么?表达式“b[y/(k+1)]= b[y/(k+1)]+t;”的意义又是什么?
“算法设计”中已说明,y用作循环变量,模拟半圈内数据的处理的过程。变化范围是1——2*k-1。而在半圈里,当y=1——k时,是行下标在变化,列下标不变;注意:此时y/(k+1)的值为0,确实实现了行下标b[0]的变化(加1或减1,由t决定)。当y=k+1——2*k-1时, 是行下标在不变,列下标在变化;注意:此时y/(k+1)的值为1,确实实现了列下标b[1]的变化。这又验证了2.5.4节介绍的利用一维数组“便于循环”的技巧,当然这离不开对数组下标的构造。
综上所述,引入变量t,k和数组b后,通过算术运算将一圈中的上下左右四种不同的变化情况,归结构造成了一个循环“不变式”。
【例3】设计算法生成魔方阵
魔方阵是我国古代发明的一种数字游戏:n阶魔方是指这样一种方阵,它的每一行、每一列以及对角线上的各数之和为一个常数,这个常数是:1/2*n*(n2+1),此常数被称为魔方阵常数。由于偶次阶魔方阵(n=偶数)求解起来比较困难,我们这里只考虑n为奇数的情况。
以下就是一个n=3的魔方阵:
6 1 8
7 5 3
2 9 4
它的各行、各列及对角线上的元素之和为15。
算法设计:有趣的是如果我们将1,2,……n2按某种规则依次填入到方阵中,得到的恰好是奇次魔方阵,这个规则可以描述如下:
(1)首先将1填在方阵第一行的中间,即(1,(n+1)/2)的位置;
(2)下一个数填在上一个数的主对角线的上方,若上一个数的位置是(i,j),下一个数应填在(i1,j1),其中i1=i-1、j1=j-1。
(3)若应填写的位置下标出界,则出界的值用n 来替代;即若i-1=0,则取i1=n;若j-1=0,则取j1=n。
(4)若应填的位置虽然没有出界,但是已经填有数据的话,则应填在上一个数的下面(行减1,列不变),即取i1=i-1,j1=j。
这样循环填数,直到把n*n个数全部填入方阵中,最后得到的是一个n阶魔方阵。
算法如下:
main( )
{int i,j, i1,j1,x,n,t,a[100][100];
print(“input an odd number:”);
input(n);
if (n mod 2=0) {print(“input error!”); return;}
for( i=1;i<=n;i=i+1)
for(j=1;j<=n;j=j+1)
a[i][j]=0;
i=1; j=int((n+1)/2); x=1;
while (x<=n*n)
{a[i][j]=x; x=x+1; i1=i; j1=j; i=i-1; j=j-1;
if ( i=0) i=n;
if (j=0) j=n;
if ( a[i][j]<>0 ) { i=i1+1; j=j1;} }
for( i=1;i<=n;i=i+1)
{print(“换行符”);
for(j=1;j<=n;j=j+1)
print(a[i][j]);
}
}
算法说明:若当前位置已经填有数的话,则应填在上一个数的下面,所以需要用变量记录上一个数据填入的位置,算法中i1,j1的功能就是记录上一个数据填入的位置。
算法分析:算法的时间复杂度为O(n2)。
标签:题目 时间性能 检测 效率 number 科研 3.4 out 五个
原文地址:https://www.cnblogs.com/gd-luojialin/p/10381459.html