标签:缓冲区 src 缓存 ttl text 无法 use amount 原因
为了弥补pcap文件的缺陷,让抓包文件可以容纳更多的信息,pcapng格式应运而生。关于它的介绍详见《PCAP Next Generation Dump File Format》
当前的wireshark/tshark抓取的包默认都被保存为pcapng格式。形而上的论述就不多谈了,直接给出一个pcapng数据包文件的例子:
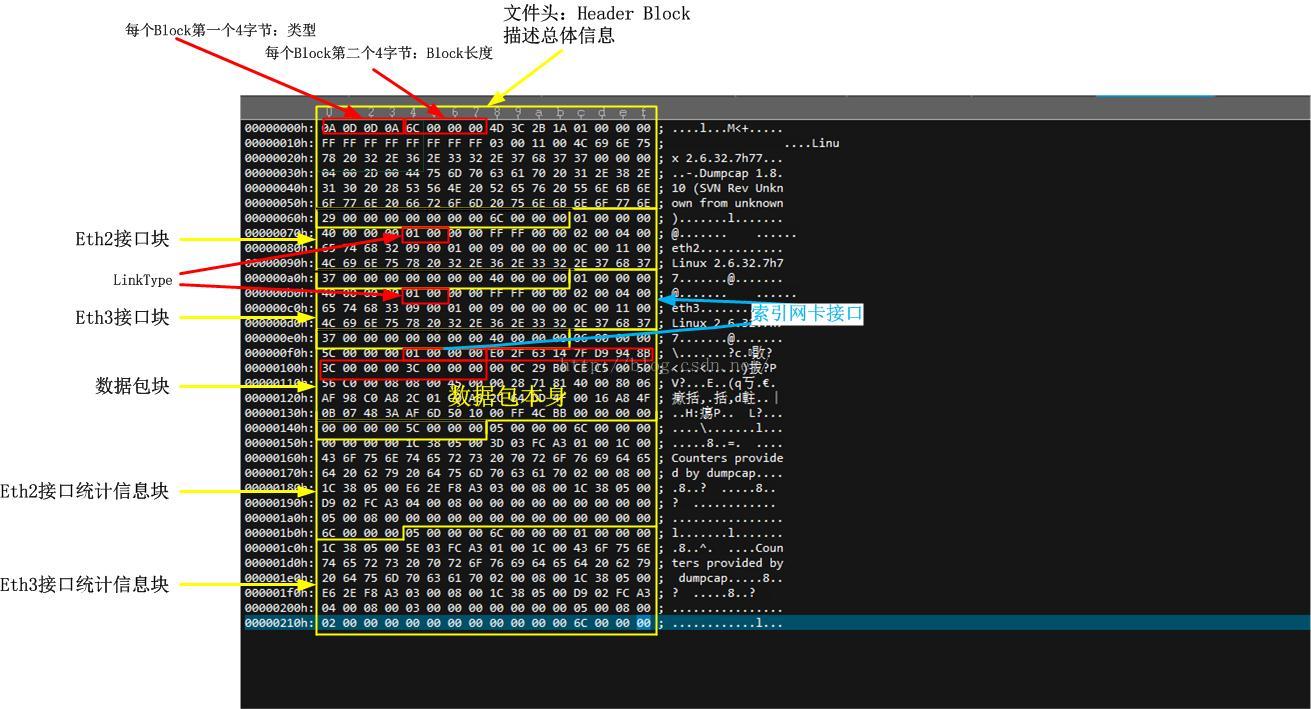
然后我强烈建议,对着《PCAP Next Generation Dump File Format》来把一个实际抓取的pcapng文件里面的每一个字节都对应清除,接下来写一个python脚本,手工构造一个这样的文件,可以用wireshark打开并解析的那种(其实这并不是一件特别难的事情)。这样你就算彻底掌握了这个格式。
还是那个需求,统计一个抓包文件中一个IP地址发出的数据总量,对于pcapng文件,由于其格式已经有了大不同啊大不同,python脚本也就截然不同了,列如下:#!/usr/bin/python
# Default tcpdump buffer size seems to 2M
import sys
import socket
import struct
filename = sys.argv[0]
filename = sys.argv[1]
#print filename
ipaddr = sys.argv[2]
direction = sys.argv[3]
packed = socket.inet_aton(ipaddr)
ip32 = struct.unpack("!L", packed)[0]
file = open(filename, "rb")
pkthdrlen=16
iphdrlen=20
tcphdrlen=20
stdtcp = 20
total = 0
pos = 0
start_seq = 0
end_seq = 0
# Read file header(type and size)
typedata = file.read(8)
(type, size) = struct.unpack("=LL", typedata)
# Skip header description
skipdata = file.read(size-8)
# Read interface desc block
interfacedata = file.read(8)
(type, size) = struct.unpack("=LL", interfacedata)
# Get linktype from int-desc block
ltdata = file.read(4)
(type, ltsize) = struct.unpack("=HH", ltdata)
if ltsize == 0x71:
pkthdrlen = 16
else:
pkthdrlen = 14
# Skip other of int-desc block
skipdata = file.read(size-8-4)
# Read packet block
pktdata = file.read(8)
(type, size) = struct.unpack("=LL", pktdata)
ipcmp = 0
cnt = 0
while pktdata:
# Skip Interface ID
skipdata = file.read(4)
# Get time and length
# sec:
# microsec:
# iplensave:
# origlen:
data = file.read(16)
(sec, microsec, iplensave, origlen) = struct.unpack("=LLLL", data)
# Read linklayer
linkdata = file.read(pkthdrlen)
# Read IP header
ipdata = file.read(iphdrlen)
(vl, tos, tot_len, id, frag_off, ttl, protocol, check, saddr, daddr) = struct.unpack(">ssHHHssHLL", ipdata)
iphdrlen = ord(vl) & 0x0F
iphdrlen *= 4
# Read TCP standard header
tcpdata = file.read(stdtcp)
(sport, dport, seq, ack_seq, pad1, win, check, urgp) = struct.unpack(">HHLLHHHH", tcpdata)
tcphdrlen = pad1 & 0xF000
tcphdrlen = tcphdrlen >> 12
tcphdrlen = tcphdrlen*4
if direction == ‘out‘:
ipcmp = saddr
else:
ipcmp = daddr
if ipcmp == ip32:
cnt += 1
total += tot_len
total -= iphdrlen + tcphdrlen
if start_seq == 0: # BUG?
start_seq = seq
end_seq = seq
# Skip options and data
skipdata = file.read(size - 8 - 4 - 16 - pkthdrlen - iphdrlen - stdtcp)
# Read next packet
pos += 1
pktdata = file.read(8)
(type, size) = struct.unpack("=LL", pktdata)
if type <> 0x06:
break
# Get interface statistics
if type == 0x05:
skiphdr = file.read(12)
opthdr = file.read(4)
(code, length) = struct.unpack("=HH", opthdr)
while length <> 0:
# 32-bit boundary! BUG?
if code == 5:
opt = file.read(length)
(drops,) = struct.unpack("=Q", opt)
# 不能这么将丢弃的数据包算进去!抓包时就这一个流吗?每个被丢弃的包都是携带数据的吗?...
# 所以,pcapng仅仅统计被丢弃的数据包的数量,不够!怎么才够?不知道!!
# total += drops*1460
elif code == 7:
opt = file.read(length)
(drops,) = struct.unpack("=Q", opt)
# total += drops*1460
else:
skipopt = file.read(length)
opthdr = file.read(4)
(code, length) = struct.unpack("=HH", opthdr)
print pos, ‘Actual:‘+str(total), ‘ideal:‘+str(end_seq-start_seq)pcapng可以把抓包过程中被丢弃的数据包的数量统计在一个section里最终导出给用户看,我们注意到pcapng文件格式的section类型中有一个”Interface Statistics Block“的可选字段,其中统计了在整个抓包过程中的以下信息:

但是这些够了吗?
有的时候,我可能会一次性抓取所有的数据包保存为一个超级大的pcapng文件,然后利用wireshark/tshark的析取功能去析出那些感兴趣的数据流,此时被析取的数据流的大小已经很小了,但是”Interface Statistics Block“依然保持不变,因为在抓包这个层次上,系统根本没有办法去区分数据流!这可怎么办?!总有人质疑,这是人之本性,我是人,我也会这样,这是亚里士多德的理论,是吗?是的!由于抓包丢失我无法统计出精确的数据包发送的数值,谁能精确统计以及怎么统计?请回答,如果不能回答,请沉默。
我不沉默,因为我有办法统计。我可以对照TCP的序列号,就像wireshark发现抓包丢失那样发现抓包丢失,但是我并不认为这是有用的,这毫无意义!
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow
标签:缓冲区 src 缓存 ttl text 无法 use amount 原因
原文地址:https://www.cnblogs.com/ksiwnhiwhs/p/10390152.html