标签:str tle 朋友圈 string 意思 c语言标准 小端 content 语言编程
昨天最后一天工作日,让我碰到了两个有意思的C语言编程问题,周末前权当轻松一下,挺有意思就过去了,因为今晚雨夜通宵,就把它们记录了下来。
下午跟同事下楼抽烟,聊到一个有意思的问题,不讲故事了,直接看问题:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct data{
char a;
int b;
};
int main()
{
char *mem = calloc(1, 100);
struct data *dt;
memset(mem, ‘c‘, 1);
memset(mem+1, 2, 1);
memset(mem+2, 0, 99);
dt = (struct data*)mem;
printf("%c %d\n", dt->a, dt->b);
}很多人用这种方法给进行数据转换,想当然会认为a就是’c’,b在小端机器上就是2,大端机器上则是0x02000000,嗯,还不错,知道大小端。但是答案还是错了。
其实struct dt的size是8,并不是1+4=5,结构体默认被对齐了,所有在字段a后面会有3个字节的填充,如果直接用mem强转,那么3个填充的0恰好覆盖掉预期中的2,造成结果的错误。上面的代码正确答案应该是:c 0
如果你把结构体dt定义成:
struct data{
char a;
char c;
int b;
}就知道那个丢失的2去哪里了。
如果希望达到预期的c 2,则只需要如下定义结构体即可:
struct data{
char a;
int b;
}__attribute__((packed));这种问题在CPU和网络协议以及持久层序列化之间的矛盾处理中非常常见。毕竟不管是网络带宽也好还是存储介质也罢,每一个字节都是钱,能少一个字节甚至一个bit都是在节约,然而对于CPU而言,时间就是钱,空间反而不重要,所以CPU倾向于内存的对齐,于是乎CPU在处理网络协议头的时候非常容易犯上面的错,当前的Linux内核一般都不用结构体强转,都是手工转换,对于序列化程序而言,更是有诸如XML,json等上层库可用,免去了程序员的很多工作。
周五下班早,这是在下班的路上被人怼的:
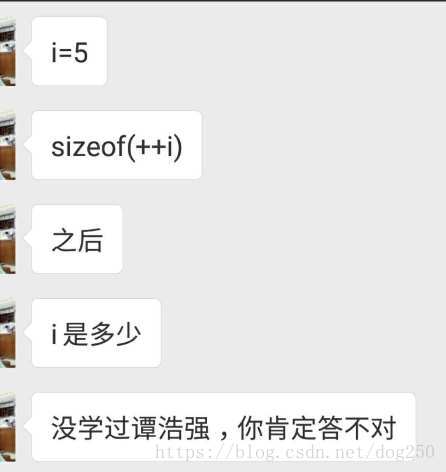
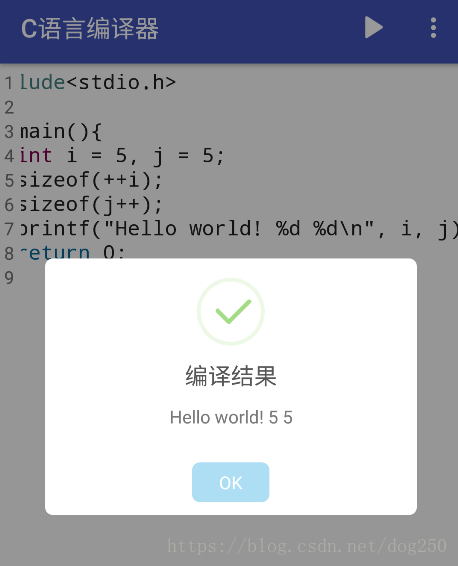
说实话,这个问题我不会,瞬间感觉被鄙视,然而我本来就承认自己不会编程,也就无所谓了。好在我有手机云编译器,就试了一下:
然后,我用这个问题调侃了朋友圈的几乎所有同行,当然除了前领导,现领导以及业界的比较牛的人,网上能搜到名字的人我也不敢调侃,这些人如果回答对了,显得我毫无水平且具有挑衅性情,万一回答不出来,我还想混呢…而且我怕被打…其他同等级别同等水平的就无所谓了,反正就是经常互相调侃,我这不就是被调侃的吗?
果然啊,不出所料,有人回答5,有人回答6,当然回答6的偏多。哈哈, 很多人跟我一样不会编程…我也就没什么觉得悲哀的了。
后来通过询问以及自己手机查找资料,知道了答案。
sizeof是一个编译期间预处理就决定结果的操作,编译期肯定不会执行任何语句,i++也好,++i也罢,都不会执行,到了运行期,sizeof的结果已经有了,就更不会去执行i++了…
后来朋友圈的回复不断,有人挖出了C语言标准,有人挖出了汇编码,有人挖出了编译器规程,不过最有意义的还是下面的图了:
就上面两个题目,面试的时候去问,相信大批量的人回答不对。但是这两个问题其实也就是知道了也就知道了,并没有什么一锤定音的功能,万万不能用这些问题去评价某个人,它们只是检测一个人对C语言的熟悉程度而已,编程者的事情知道的不多,不多说。
顺便一说,我学过谭浩强的书,但学的不好。
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://blog.csdn.net/jiangjunshow
标签:str tle 朋友圈 string 意思 c语言标准 小端 content 语言编程
原文地址:https://www.cnblogs.com/ksiwnhiwhs/p/10390491.html