标签:secondary stat access main ica 成员 output 磁盘 file
HDFS的shell操作和JavaAPI的使用:
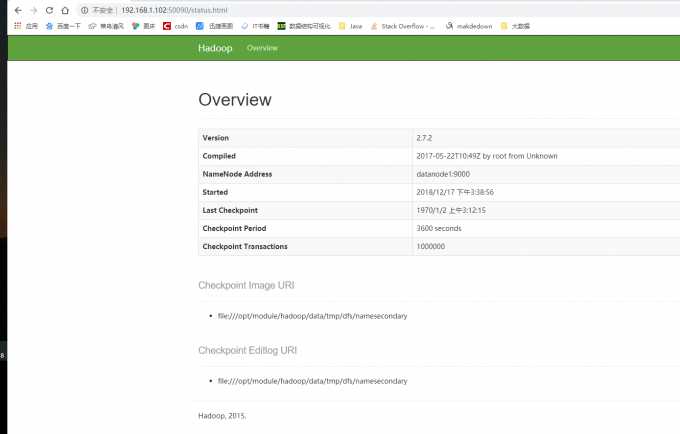
WEB端口50090查看SecondaryNameNode信息。可以查看Hadoop的版本,NameNode的IP,Checkpoint等信息。
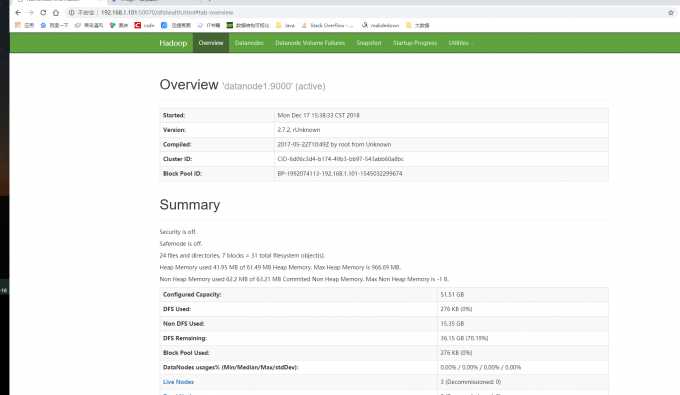
WEB端口50070可以查看HDFS的信息和目录结构
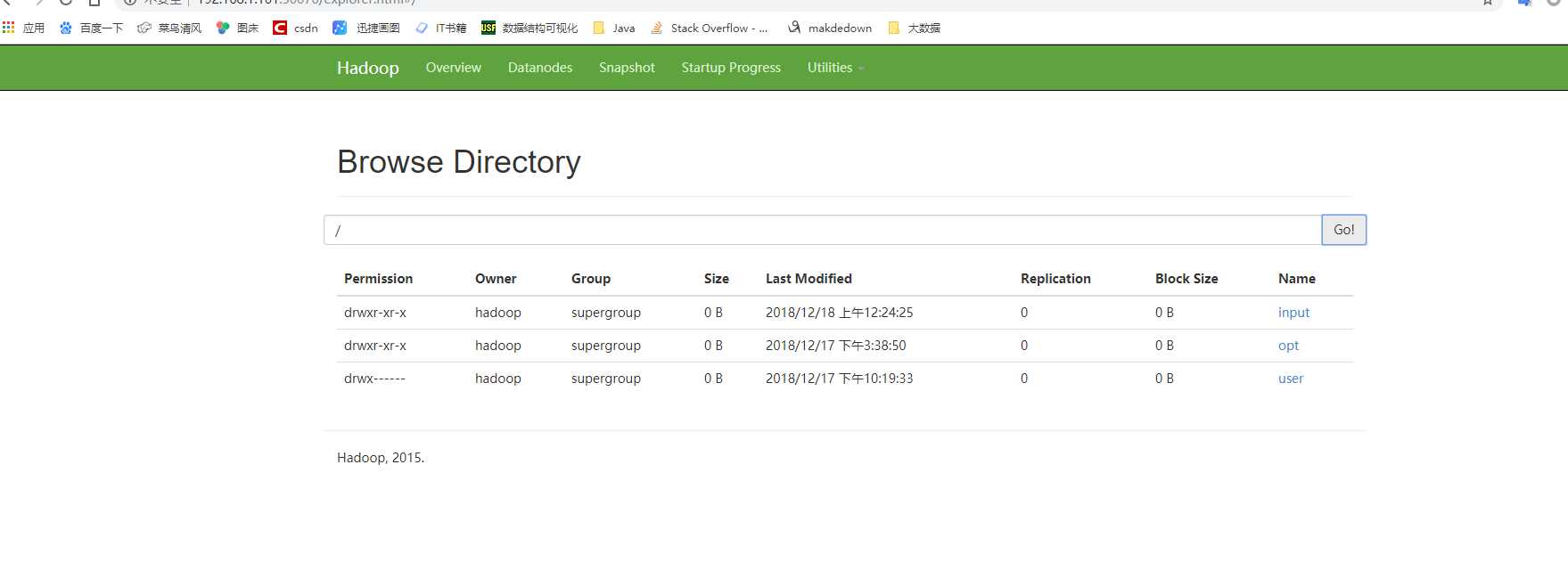
hdfs dfs -ls [-d][-h][-R] <paths> [-d]:返回path [-h]:按照KMG数据大小单位显示文件大小,默认B [-R]:级联显示paths下文件
创建文件夹
hdfs dfs -mkdir [-p]<paths>
新建文件
hdfs dfs -touchz<paths>
查看文件
hdfs dfs -cat/[-ignoreCrc] [src] hdfs dfs -text -ignoreCrc /input/test #忽略校验 hdfs dfs -cat -ignoreCrc /input/test
追写文件
hdfs dfs --appendToFile <localsrc> <dst> 如果localsrc为"-"表示数据来自键盘输入用"Ctrc+C"取消输入
上传下载
hdfs dfs -put [-f][-p]<localsrc> <dst> # 上传到指定目录 hdfs dfs -get [-p]<src> <localhost> # 现在到本地
删除文件
hdfs dfs -rm [-f] [-r] <src> -f 如果要删除的文件不存在,不显示错误信息 -r/R 级联删除目录下所有文件和子目录文件
磁盘空间
hdfs dfs -du[-s][-h]<path> [-s]显示指定目录所占空间大小 [-h]按照K M G 数据显示文件大小
Configuration封装了客户端或服务器的配置,Confiuration实例会自动加载HDFS的配置文件core-site.xml,从中获取Hadoop集群中的配置信息。因此我们要把集群的配置core-site.xml放在Maven项目的resources目录下。
Configuration conf = new Configuration();
FileSystem类是客户端访问文件系统的入口,是一个抽象的文件系统。DistributedFileSystem类是FileSystem的一个具体实现。实例化FileSystem并发挥默认的文件系统代码如下:
FileSystem fs = FileSystem.get(conf);
HDFS API 提供了Path类来封装文件路径。PATH类位于org.apache.hadoop.fs.Path包中,代码如下:
Path path = new Path("/input/write.txt");
得到Filesystem实例后,就可以使用该实例提供的方法成员执行相应的操作。如果:打开文件,创建文件、重命名文件、删除文件。
? FileSystem类常用成员函数
| 方法名称及参数 | 返回值 | 功能 |
|---|---|---|
| create(Path f) | FSDataOutputStream | 创建一个文件 |
| open(Path f) | FSDatatInputStream | 打开指定的文件 |
| delete(Path f) | boolean | 删除指定文件 |
| exsits(Path f) | boolean | 检查文件是否存在 |
| getBlockSize(Path f) | long | 返回指定的数据块的大小 |
| getLength(Path f) | long | 返回文件长度 |
| mkdir(Path f) | boolean | 检查文件是否存在 |
| copyFromLocalFile(Path src, Path dst) | void | 从本地磁盘复制文件到HDFS |
| copyToLocalFile(Path src, Path dst) | void | 从HDFS复制文件到本地磁盘 |
| ……….. | ………. | ……………. |
package hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class PutFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://datanode1:9000"),conf,"hadoop");
//本地文件
Path src = new Path("D:\\上传文件.txt");
//HDFS 路径
Path dst = new Path("/input/上传文件.txt");
fs.copyFromLocalFile(src, dst);
fs.close();
System.out.println("文件上传成功");
}
}
创建文件
package hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class CreateFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://datanode1:9000"), conf, "hadoop");
Path dfs = new Path("/input/上传文件.txt");
FSDataOutputStream newFile = fs.create(dfs, true); //是否覆盖文件 true 覆盖 false 追加
newFile.writeBytes("this is a create file tes");
System.out.println("创建文件成功");
}
}
文件详情
package hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
import java.text.SimpleDateFormat;
import java.util.Date;
public class SeeInfo {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://datanode1:9000"), conf, "hadoop");
// HDFS文件
Path fpath = new Path("/input/上传文件.txt");
FileStatus fileLinkStatus = fs.getFileLinkStatus(fpath);
//获得块大小
long blockSize = fileLinkStatus.getBlockSize();
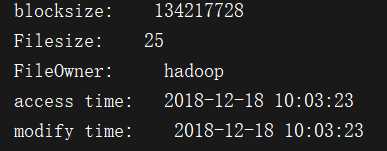
System.out.println("blocksize: " + blockSize);
//获得文件大小
long len = fileLinkStatus.getLen();
System.out.println("Filesize: " + len);
//获得文件所有者
String owner = fileLinkStatus.getOwner();
System.out.println("FileOwner: " + owner);
//获得创建时间
SimpleDateFormat formater = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
long accessTime = fileLinkStatus.getAccessTime();
System.out.println("access time: " + formater.format(new Date(accessTime)));
//获得修改时间
long modificationTime = fileLinkStatus.getModificationTime();
System.out.println("modify time: " + formater.format(new Date(modificationTime)));
}
}
package hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
public class GetFIle {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://datanode1:9000"), conf, "hadoop");
// HDFS 文件
InputStream in = fs.open(new Path("/input/上传文件.txt"));
//保存到本地位置
OutputStream out = new FileOutputStream("D://下载文件.txt");
IOUtils.copyBytes(in, out, 4096, true);
System.out.println("下载文件成功");
fs.close();
}
}
删除文件
package hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.net.URI;
public class DeleteFile {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://datanode1:9000"), conf, "hadoop");
Path path = new Path("/input/上传文件.txt");
fs.delete(path);
System.out.println("删除成功");
}
}
标签:secondary stat access main ica 成员 output 磁盘 file
原文地址:https://www.cnblogs.com/fmgao-technology/p/10417302.html