标签:word spark sql .data 定义 content using exit purpose omd
1 涉及到的API
BaseRelation: In a simple way, we can say it represents the collection of tuples with known schema TableScan: provides a way to scan the data and generates the RDD[Row] from the data
RelationProvider: takes a list of parameters and returns a BaseRelation.
BaseRelation提供了定义数据结构Schema的方法,类似tuples的集合结构
TableScan,提供了扫描数据并生成RDD[Row]的方法
RelationProvider,拿到参数列表并返回一个BaseRelation
2 代码实现
定义ralation
package cn.zj.spark.sql.datasource
import org.apache.hadoop.fs.Path
import org.apache.spark.sql.{DataFrame, SQLContext, SaveMode}
import org.apache.spark.sql.sources.{BaseRelation, CreatableRelationProvider, RelationProvider, SchemaRelationProvider}
import org.apache.spark.sql.types.StructType
/**
* Created by rana on 29/9/16.
*/
class DefaultSource extends RelationProvider with SchemaRelationProvider with CreatableRelationProvider {
override def createRelation(sqlContext: SQLContext, parameters: Map[String, String]): BaseRelation = {
createRelation(sqlContext, parameters, null)
}
override def createRelation(sqlContext: SQLContext, parameters: Map[String, String], schema: StructType): BaseRelation = {
val path = parameters.get("path")
path match {
case Some(p) => new CustomDatasourceRelation(sqlContext, p, schema)
case _ => throw new IllegalArgumentException("Path is required for custom-datasource format!!")
}
}
override def createRelation(sqlContext: SQLContext, mode: SaveMode, parameters: Map[String, String],
data: DataFrame): BaseRelation = {
val path = parameters.getOrElse("path", "./output/") //can throw an exception/error, it‘s just for this tutorial
val fsPath = new Path(path)
val fs = fsPath.getFileSystem(sqlContext.sparkContext.hadoopConfiguration)
mode match {
case SaveMode.Append => sys.error("Append mode is not supported by " + this.getClass.getCanonicalName); sys.exit(1)
case SaveMode.Overwrite => fs.delete(fsPath, true)
case SaveMode.ErrorIfExists => sys.error("Given path: " + path + " already exists!!"); sys.exit(1)
case SaveMode.Ignore => sys.exit()
}
val formatName = parameters.getOrElse("format", "customFormat")
formatName match {
case "customFormat" => saveAsCustomFormat(data, path, mode)
case "json" => saveAsJson(data, path, mode)
case _ => throw new IllegalArgumentException(formatName + " is not supported!!!")
}
createRelation(sqlContext, parameters, data.schema)
}
private def saveAsJson(data : DataFrame, path : String, mode: SaveMode): Unit = {
/**
* Here, I am using the dataframe‘s Api for storing it as json.
* you can have your own apis and ways for saving!!
*/
data.write.mode(mode).json(path)
}
private def saveAsCustomFormat(data : DataFrame, path : String, mode: SaveMode): Unit = {
/**
* Here, I am going to save this as simple text file which has values separated by "|".
* But you can have your own way to store without any restriction.
*/
val customFormatRDD = data.rdd.map(row => {
row.toSeq.map(value => value.toString).mkString("|")
})
customFormatRDD.saveAsTextFile(path)
}
}
定义Schema以及读取数据代码
package cn.zj.spark.sql.datasource
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.sql.sources._
import org.apache.spark.sql.types._
/**
* Created by rana on 29/9/16.
*/
class CustomDatasourceRelation(override val sqlContext : SQLContext, path : String, userSchema : StructType)
extends BaseRelation with TableScan with PrunedScan with PrunedFilteredScan with Serializable {
override def schema: StructType = {
if (userSchema != null) {
userSchema
} else {
StructType(
StructField("id", IntegerType, false) ::
StructField("name", StringType, true) ::
StructField("gender", StringType, true) ::
StructField("salary", LongType, true) ::
StructField("expenses", LongType, true) :: Nil
)
}
}
override def buildScan(): RDD[Row] = {
println("TableScan: buildScan called...")
val schemaFields = schema.fields
// Reading the file‘s content
val rdd = sqlContext.sparkContext.wholeTextFiles(path).map(f => f._2)
val rows = rdd.map(fileContent => {
val lines = fileContent.split("\n")
val data = lines.map(line => line.split(",").map(word => word.trim).toSeq)
val tmp = data.map(words => words.zipWithIndex.map{
case (value, index) =>
val colName = schemaFields(index).name
Util.castTo(if (colName.equalsIgnoreCase("gender")) {if(value.toInt == 1) "Male" else "Female"} else value,
schemaFields(index).dataType)
})
tmp.map(s => Row.fromSeq(s))
})
rows.flatMap(e => e)
}
override def buildScan(requiredColumns: Array[String]): RDD[Row] = {
println("PrunedScan: buildScan called...")
val schemaFields = schema.fields
// Reading the file‘s content
val rdd = sqlContext.sparkContext.wholeTextFiles(path).map(f => f._2)
val rows = rdd.map(fileContent => {
val lines = fileContent.split("\n")
val data = lines.map(line => line.split(",").map(word => word.trim).toSeq)
val tmp = data.map(words => words.zipWithIndex.map{
case (value, index) =>
val colName = schemaFields(index).name
val castedValue = Util.castTo(if (colName.equalsIgnoreCase("gender")) {if(value.toInt == 1) "Male" else "Female"} else value,
schemaFields(index).dataType)
if (requiredColumns.contains(colName)) Some(castedValue) else None
})
tmp.map(s => Row.fromSeq(s.filter(_.isDefined).map(value => value.get)))
})
rows.flatMap(e => e)
}
override def buildScan(requiredColumns: Array[String], filters: Array[Filter]): RDD[Row] = {
println("PrunedFilterScan: buildScan called...")
println("Filters: ")
filters.foreach(f => println(f.toString))
var customFilters: Map[String, List[CustomFilter]] = Map[String, List[CustomFilter]]()
filters.foreach( f => f match {
case EqualTo(attr, value) =>
println("EqualTo filter is used!!" + "Attribute: " + attr + " Value: " + value)
/**
* as we are implementing only one filter for now, you can think that this below line doesn‘t mak emuch sense
* because any attribute can be equal to one value at a time. so what‘s the purpose of storing the same filter
* again if there are.
* but it will be useful when we have more than one filter on the same attribute. Take the below condition
* for example:
* attr > 5 && attr < 10
* so for such cases, it‘s better to keep a list.
* you can add some more filters in this code and try them. Here, we are implementing only equalTo filter
* for understanding of this concept.
*/
customFilters = customFilters ++ Map(attr -> {
customFilters.getOrElse(attr, List[CustomFilter]()) :+ new CustomFilter(attr, value, "equalTo")
})
case _ => println("filter: " + f.toString + " is not implemented by us!!")
})
val schemaFields = schema.fields
// Reading the file‘s content
val rdd = sqlContext.sparkContext.wholeTextFiles(path).map(f => f._2)
val rows = rdd.map(file => {
val lines = file.split("\n")
val data = lines.map(line => line.split(",").map(word => word.trim).toSeq)
val filteredData = data.map(s => if (customFilters.nonEmpty) {
var includeInResultSet = true
s.zipWithIndex.foreach {
case (value, index) =>
val attr = schemaFields(index).name
val filtersList = customFilters.getOrElse(attr, List())
if (filtersList.nonEmpty) {
if (CustomFilter.applyFilters(filtersList, value, schema)) {
} else {
includeInResultSet = false
}
}
}
if (includeInResultSet) s else Seq()
} else s)
val tmp = filteredData.filter(_.nonEmpty).map(s => s.zipWithIndex.map {
case (value, index) =>
val colName = schemaFields(index).name
val castedValue = Util.castTo(if (colName.equalsIgnoreCase("gender")) {
if (value.toInt == 1) "Male" else "Female"
} else value,
schemaFields(index).dataType)
if (requiredColumns.contains(colName)) Some(castedValue) else None
})
tmp.map(s => Row.fromSeq(s.filter(_.isDefined).map(value => value.get)))
})
rows.flatMap(e => e)
}
}
类型转换类
package cn.zj.spark.sql.datasource
import org.apache.spark.sql.types.{DataType, IntegerType, LongType, StringType}
/**
* Created by rana on 30/9/16.
*/
object Util {
def castTo(value : String, dataType : DataType) = {
dataType match {
case _ : IntegerType => value.toInt
case _ : LongType => value.toLong
case _ : StringType => value
}
}
}
3 依赖的pom文件配置
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
<!--<hadoop.version>2.6.0-cdh5.7.0</hadoop.version>-->
<!--<hbase.version>1.2.0-cdh5.7.0</hbase.version>-->
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<!-- 导入spark的依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- 导入spark的依赖 -->
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>
4测试代码以及测试文件数据
package cn.zj.spark.sql.datasource
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* Created by rana on 29/9/16.
*/
object app extends App {
println("Application started...")
val conf = new SparkConf().setAppName("spark-custom-datasource")
val spark = SparkSession.builder().config(conf).master("local").getOrCreate()
val df = spark.sqlContext.read.format("cn.zj.spark.sql.datasource").load("1229practice/data/")
df.createOrReplaceTempView("test")
spark.sql("select * from test where salary = 50000").show()
println("Application Ended...")
}
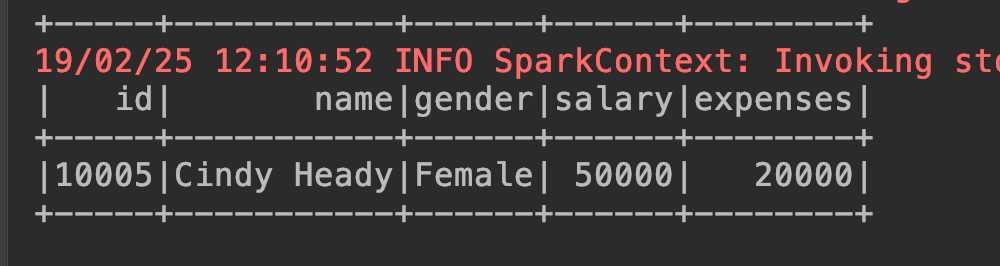
数据
10002, Alice Heady, 0, 20000, 8000 10003, Jenny Brown, 0, 30000, 120000 10004, Bob Hayden, 1, 40000, 16000 10005, Cindy Heady, 0, 50000, 20000 10006, Doug Brown, 1, 60000, 24000 10007, Carolina Hayden, 0, 70000, 280000
参考文献:http://sparkdatasourceapi.blogspot.com/2016/10/spark-data-source-api-write-custom.html
标签:word spark sql .data 定义 content using exit purpose omd
原文地址:https://www.cnblogs.com/QuestionsZhang/p/10430230.html