标签:数据结构 where 计数 inf 很多 com 读写 必须 节点
索引的目的在于提高查询效率,它的作用就相当于一本书的目录;
优点:适用于等值查询的场景;
缺点:范围查询效率较低;
优点:范围查询和等值查询效率较高;
缺点:插入、删除操作效率较低;
适用于静态存储引擎,保存一些不会修改的数据;
二叉树是一个经典的数据结构,增删改查效率都不错。不过由于索引需要存储在磁盘中,使用二叉树时,当节点数量很大时,树的高度会变的很高,一次查询可能访问很多数据块,由于磁盘IO问题,导致效率偏低;
为了查询中尽量减少磁盘IO,必须访问尽量少的数据块,N叉树就是一个不错的选择;N叉树由于读写性能上的优点,以及适配磁盘的访问模式,已经广泛的用于搜索引擎。
磁盘IO是非常高昂的操作,当进行一次磁盘IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次磁盘IO。
设计数据库时,我们可以将N叉树的一个节点的大小设计为刚好一个操作系统的数据页大小,这样一次磁盘IO就可以将一个节点的数据全部读取到内存当中。
在InnoDB中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。
InnoDB中使用B+树索引模型,所以数据都是存储在B+树中的。
根据B+树叶子节点的内容,索引类型可分为主键索引和非主键索引。
主键索引的叶子节点存储的是整行数据,主键索引也被称为聚簇索引;
非主键索引的叶子节点存储的是主键的值,在InnoDB中,非主键索引也被称为二级索引;
基于主键索引查询时,只需要搜索主键这棵B+树就可以查到这条记录的全部信息;
基于非主键索引查询时,如果在这个非主键索引树上未查询到想要的信息,需要通过在非主键缩印树上查到的主键信息在主键索引树再查询一次,这个过程称为回表;
主键索引的长度越小,普通索引的叶子节点就越小,其占用空间就越小;
假如有一个表,有一个主键索引为身份证号码,一个普通索引为年龄;
select card_id from user where age between 10 and 20;
在这个查询中,在 age 的索引树上已经有card_id 的值了,因此可以直接获得查询结果,不需要回表。在这个查询中,索引 age 已经覆盖了我们的查询需求,我们称之为覆盖索引;
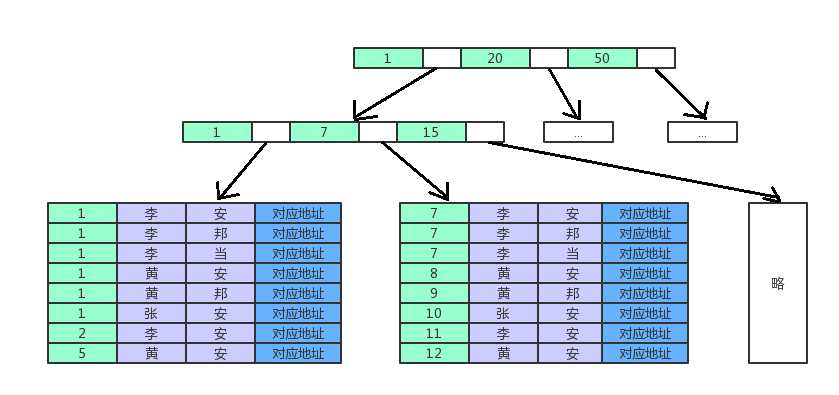
联合索引(col1, col2,col3)也是一棵B+Tree,其非叶子节点存储的是第一个关键字的索引,而叶节点存储的则是三个关键字col1、col2、col3三个关键字的数据,且按照col1、col2、col3的顺序进行排序。
当一个数据页已经满了,此时如果向该页中插入数据,则会申请一个新的数据页,然后挪动部分数据过去,该过程称之为页分裂;页分裂会使空间的使用率降低50%左右;
当相邻两个页删除了数据,利用率很低时,会将数据页做合并,称为页合并;
标签:数据结构 where 计数 inf 很多 com 读写 必须 节点
原文地址:https://www.cnblogs.com/virgosnail/p/10434650.html