标签:取出 链接 定义函数 sdn ldb 右击 代码 fetchall 时间
csdn博客部分截图
博客链接:https://blog.csdn.net/kevinelstri/article/list/1?
此次目的是要爬取文章标题,发表文章时间以及阅读数量
1.浏览器打开网址,选择一个右击标题,审查元素。如图

通过观察可以发现每篇文章有一个div,格式大多相同,就可以写爬取代码了
2.爬取文章标题,时间,阅读数的网页定位代码:
count=driver.find_elements_by_xpath("//div[@class=‘article-list‘]/div[position()>1]/div/p[3]/span/span")
time=driver.find_elements_by_xpath("//div[@class=‘article-list‘]/div[position()>1]/div/p[1]/span")
content=driver.find_elements_by_xpath("//div[@class=‘article-list‘]/div[position()>1]/h4/a")
三条代码都是通过xpath定位元素
3.取出爬取元素的值,并且打包成列表(方便数据的对应存储)
time_list=[]
content_list=[]
count_list=[]
for t in time:
time_list.append(t.text)
for c in content:
content_list.append(c.text)
for c in count:
count_list.append(c.text)
end1=list(zip(content_list,time_list,count_list))#将爬取的标题和时间压缩成列表
4.将爬取的数据存入数据库(原本已经在数据库test下建立了表格climb_boke),
这里选择写了个自定义函数
def Mysql(data):
conn=MySQLdb.connect(host=‘localhost‘,user=‘root‘,passwd=‘cmy1234‘,port=3306)
cur=conn.cursor()
conn.set_character_set(‘utf8‘)#设置编码
cur.execute(‘set names utf8;‘)
cur.execute(‘set character set utf8;‘)
cur.execute(‘set character_set_connection=utf8;‘)
cur.execute(‘use test‘)
sql=‘‘‘insert into climb_boke(title,time,count) values(%s,%s,%s)‘‘‘
for i in range(0,len(data)):
cur.execute(sql,list(data[i]))#插入的数据必须是列表形势
print("插入数据成功")
cur.execute(‘select* from climb_boke‘)
for data in cur.fetchall():
print(data)
conn.commit()
cur.close()
conn.close()
整体代码:

这里翻页我只取了两页,可以做修改
while k<=2:
url=‘https://blog.csdn.net/kevinelstri/article/list/‘+str(k)+‘?‘
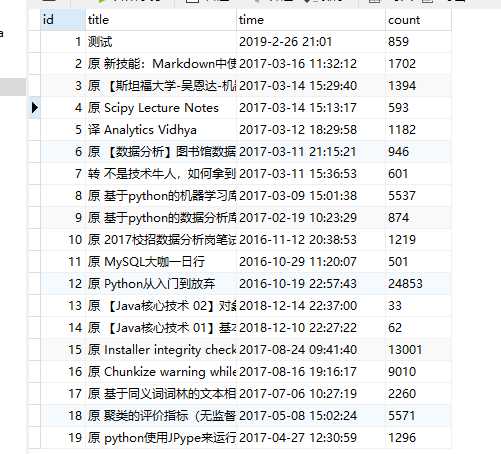
最终Navicat查看的成果
Python-selenium翻页爬取csdn博客保存数据入mysql
标签:取出 链接 定义函数 sdn ldb 右击 代码 fetchall 时间
原文地址:https://www.cnblogs.com/chenminyu/p/10442918.html