标签:info eva 另一个 个人 float idt 存储方式 lis 参考
python的变量及其存储
在高级语言中,变量是对内存及其地址的抽象。对于python而言,python的一切变量都是对象,变量的存储,采用了引用语义的方式,存储的只是一个变量的值所在的内存地址,而不是这个变量的值本身。
引用语义:在python中,变量保存的是对象(值)的引用,我们称为引用语义。采用这种方式,变量所需的存储空间大小一致,因为变量只是保存了一个引用。也被称为对象语义和指针语义。
值语义:有些语言采用的不是这种方式,它们把变量的值直接保存在变量的存储区里,这种方式被我们称为值语义,例如C语言,采用这种存储方式,每一个变量在内存中所占的空间就要根据变量实际的大小而定,无法固定下来。
数据类型分类
在python中的数据类型包括:bool、int、long、float、str、set、list、tuple、dict等等。我们可以大致将这些数据类型归类为简单数据类型和复杂的数据结构。

变量的赋值:
(1)简单数据类型赋值:
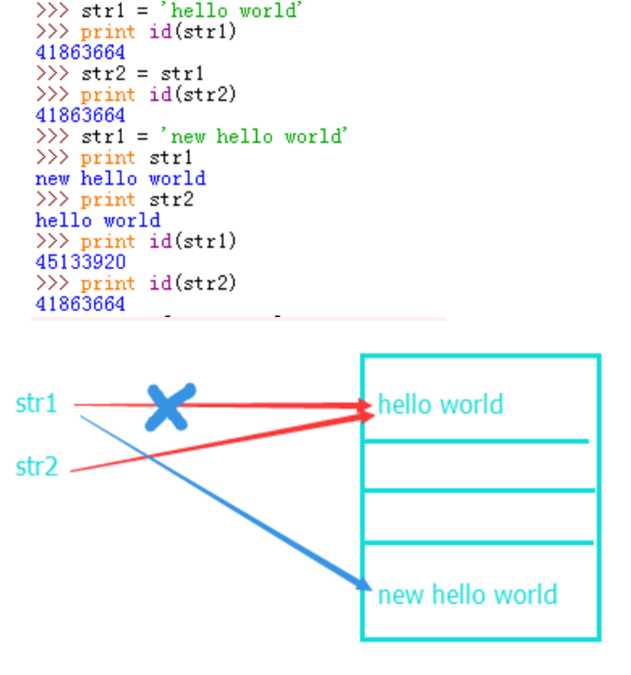
看内存中的变化,起始的赋值操作让str1和str2变量都存储了‘hello world’所在的地址,重新对str1初始化,使str1中存储的地址发生了改变,指向了新建的值,此时str2变量存储的内存地址并未改变,所以不受影响。
(2)复杂的数据结构中的赋值:
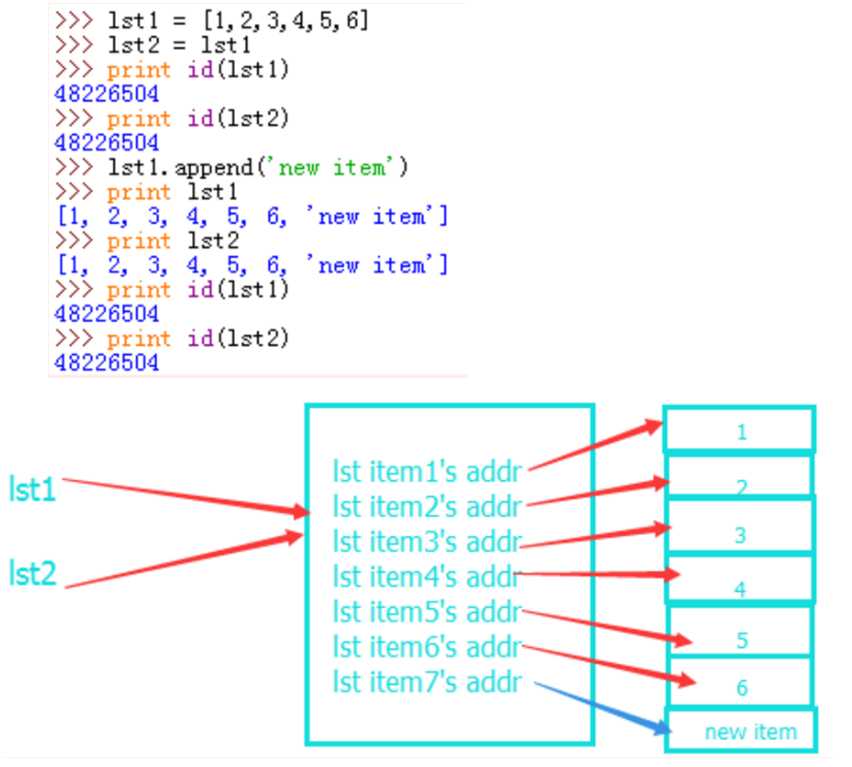
上图对列表的增加修改操作,没有改变列表的内存地址,lst1和lst2都发生了变化。对照内存图我们不难看出,在列表中添加新值时,列表中又多存储了一个新元素的地址,而列表本身的地址没有变化,所以lst1和lst2的id均没有改变并且都被添加了一个新的元素。简单的比喻一下,我们出去吃饭,lst1和lst2就像是同桌吃饭的两个人,两个人公用一张桌子,只要桌子不变,桌子上的菜发生了变化两个人是共同感受的。
初识拷贝
我们已经详细了解了变量赋值的过程。对于复杂的数据结构来说,赋值就等于完全共享了资源,一个值的改变会完全被另一个值共享。
然而有的时候,我们偏偏需要将一份数据的原始内容保留一份,再去处理数据,这个时候使用赋值就不够明智了。python为这种需求提供了copy模块。提供了两种主要的copy方法,一种是普通的copy,另一种是deepcopy。我们称前者是浅拷贝,后者为深拷贝。
深浅拷贝一直是所有编程语言的重要知识点,下面我们就从内存的角度来分析一下两者的区别。
深浅拷贝
详细分析参考博文:http://www.cnblogs.com/Eva-J/p/5534037.html
浅拷贝:

当sourceLst列表发生变化,copyLst中存储的lst内存地址没有改变,所以当lst发生改变的时候,sourceLst和copyLst两个列表就都发生了改变。这种情况发生在字典套字典、列表套字典、字典套列表,列表套列表,以及各种复杂数据结构的嵌套中,所以当我们的数据类型很复杂的时候,用copy去进行浅拷贝就要非常小心。。。
深拷贝:
深拷贝就是在内存中重新开辟一块空间,不管数据结构多么复杂,只要遇到可能发生改变的数据类型,就重新开辟一块内存空间把内容复制下来,直到最后一层,不再有复杂的数据类型,就保持其原引用。这样,不管数据结构多么的复杂,数据之间的修改都不会相互影响。这就是深拷贝~~~
标签:info eva 另一个 个人 float idt 存储方式 lis 参考
原文地址:https://www.cnblogs.com/girl1314/p/10489861.html