标签:style blog http strong sp 数据 2014 on 问题
1.用数学方法描述规律
由于自然语言具有上下文相关性,所以我们要依此建模,这就是我们常说的统计语言模型(statistical Language Model)。
比如一句话:国家主席习近ping昨天宣布将给非洲提供100亿美元的资金,帮助他们发展。
这句话很容易理解。但是如果换成:习近ping国家主席将宣布100亿美元的资金,帮助他们发展给非洲。这样意思含混了,虽然多少还能猜到一点。但是如果换成习近ping昨天宣布将给非洲国家主席提供100亿美元的资,帮助他们金发展。基本上读者就不知所云了。
针对上面的情况,贾里尼克出发点就是:一个句子是否合理,就看看它的可能性(概率)大小如何。第一句话的概率如果是10-20,第二个句子大概是10-25,第三个概率是10-70,可见第一个是最有可能,较常规的情况。
下面我们用马尔科夫模型来正式描述一下。笔者之前虽然在52NLP等网站上看过马尔科夫模型,也推导了1层马尔科夫,但是还是没有打到质的突破。今天一看书,顿悟了!大致是这样一个情况。如果完整的来讲,一个句子的概率,等于各个单词的联合概率,即:

上式计算上来说,前两个计算复杂度还不算高,到了第三个之后,计算就变得复杂多了,甚至无法估计。怎么办呢?
这时候,马尔科夫来了。他跟朴素类似,都是建立在一个偷懒的假设上的。马尔科夫假设任意一个单词wi,出现的概率只同它前面的词Wi-1有关,于是问题就变得简单了:
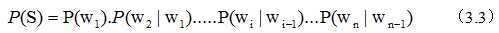
这种只涉及到2个单词的称为二元模型。
至于3.3式中每个P的求解,我们选择用频度代替概率做近似计算。
2.延伸阅读:
2.1高阶语言模型
很多情况下,一个词不是与前面的一个词有点,而是前二或者前三个词有关。这就是我们常说的N元模型。上面讲的3.3式子,就是N=2的情况,其他情况下的假设为:
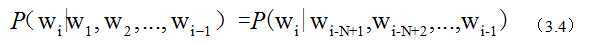
我们知道,一般N取得都比较小,为什么呢?主要还是效率的问题。一来,N元模型的时间空间复杂度都是N的指数函数,因此N不能太大;二来N从1到2,2到3时,模型效果上升较为明显,之后就不怎么明显了。所以出于性价比考虑,一般不会去3以上的值。
最后,高阶模型不可能覆盖所有的语言现象。前面我们讲马尔科夫用了偷懒的方法,解决了一部分计算问题,但是偷懒终究是偷懒,这就是它的局限性。
2.2模型的训练、零概率问题和平滑方法
要是有些词或者字在语料中没有出现,那么就有可能出现0的情况。在朴素贝叶斯中,我们用的是拉普拉斯平滑,这里。我们采用了另一种方法,通过对已有数据的概率打折扣,分出一些概率给未出现的事件。这种方法我们称为古德-图灵估计。
假定在语料库中出现r次的词有Nr个,特别的,未出现的词有N0个。语料库大小为N。
进行古德-图灵估计后: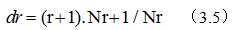
这样扔保持累加和为1.
一般来说,随着出现次数r的增加,这样的词的数量会减少,所以对于N0,在经过处理之后,我们会得到一个略大于0的数。
在实际自然语言处理中,一般对出现次数超过某个阈值的词,频率不下调,只对出现次数低于某个阈值的词,频率才下调。
下面给出一个例子,是二元组的情况。
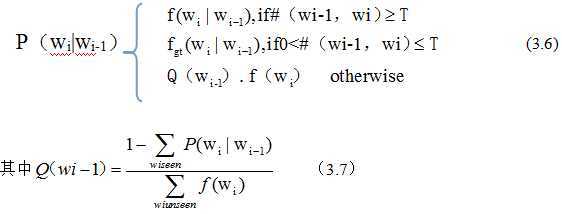
类似的三元我就不举例了。
2.3语料选取
NLP语料的选取,其实相当于机器学习算法的训练集的选取,训练集的好坏直接影响模型的性能。比如你要处理的都是一些评论什么的较为口语化的东西,却用人民日报的标准语料去训练,这样的效果肯定会是很差的。但是用同类型的语料,由于获得的语料中肯定会有噪音,我们要先对其中一些有规律的噪音做处理。
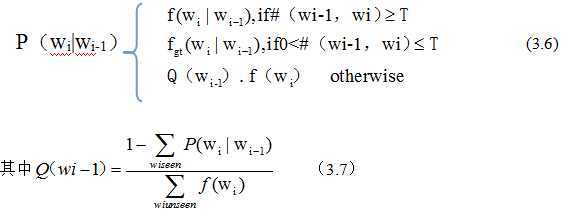
标签:style blog http strong sp 数据 2014 on 问题
原文地址:http://www.cnblogs.com/KingKou/p/4033577.html