标签:hellip 安装 覆盖 思路 path 环境变量 blog linux 文件
最近在研究Spark,准确的说是pyspark,为了搭个测试环境,之前一直在云上开Linux机器来搭Hadoop,但是Spark可以Local执行,我就打算在本地搭个环境。遇到了一些问题,记录一下,也给其他朋友一个思路。
pyspark在本地搭建需要
Java JDK 1.8.0
Anacoda3
spark-2.2.3-bin-hadoop2.7
hadoop-2.7.7
hadooponwindows-master(后面提供下载连接)
操作步骤:
1,安装JDK和Anaconda3
2,把hadooponwindows-master的bin覆盖hadoop-2.7.7的bin
hadooponwindows-master里面的bin主要有winutils.exe,还有一些dll文件,都是需要的
3,配置Java,Spark,Hadoop环境变量
Spark和Hadoop的环境配置与Java类似
(1)需要完成spark_home和bin环境变量相关配置。
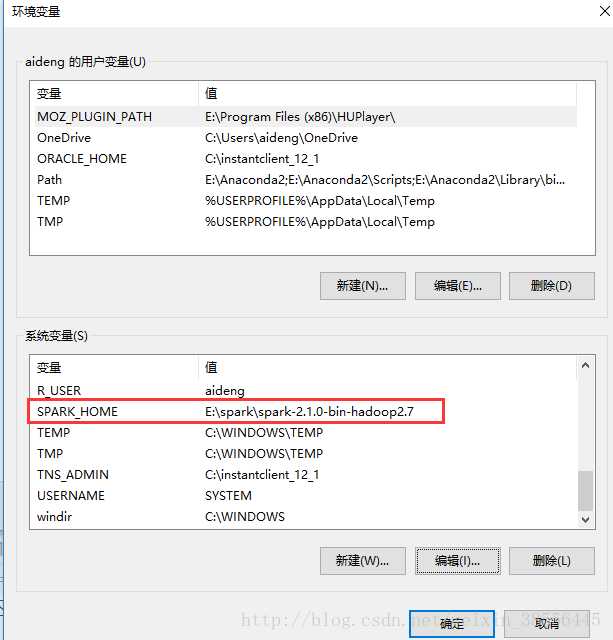
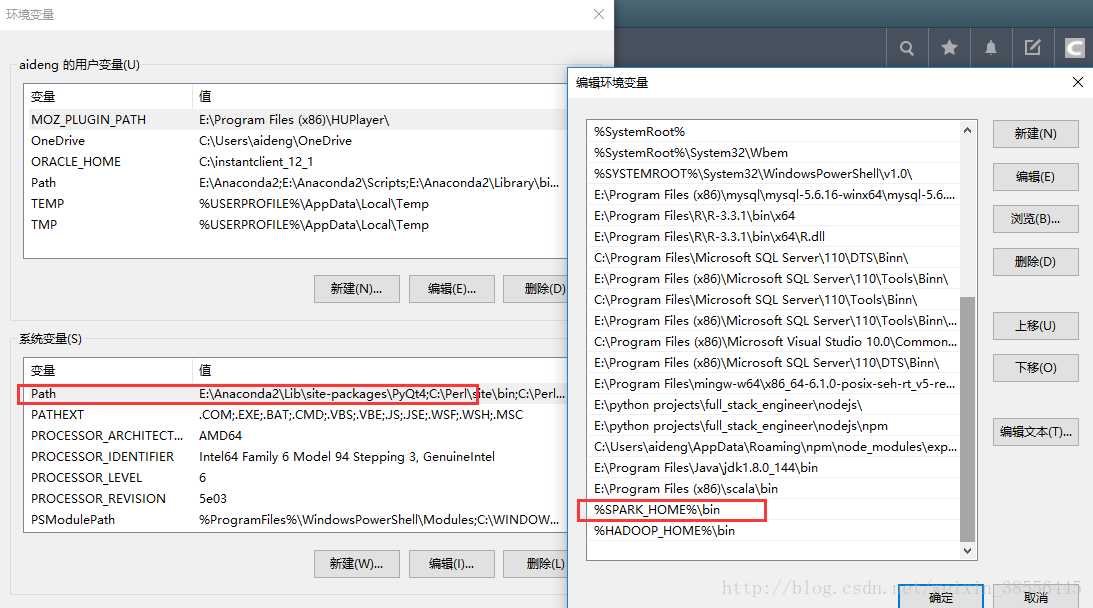
(2)同样地,这里也需要配置环境变量,新建HADOOP_HOME变量和新增在path变量下新增…/hadoop/bin。
为了偷懒,这一块我主要复制这个连接的内容(感谢):https://blog.csdn.net/weixin_38556445/article/details/78182264
下面说下我遇到的两个问题:
安装spark,环境变量已经配置,也已经解压,但是启动报错:
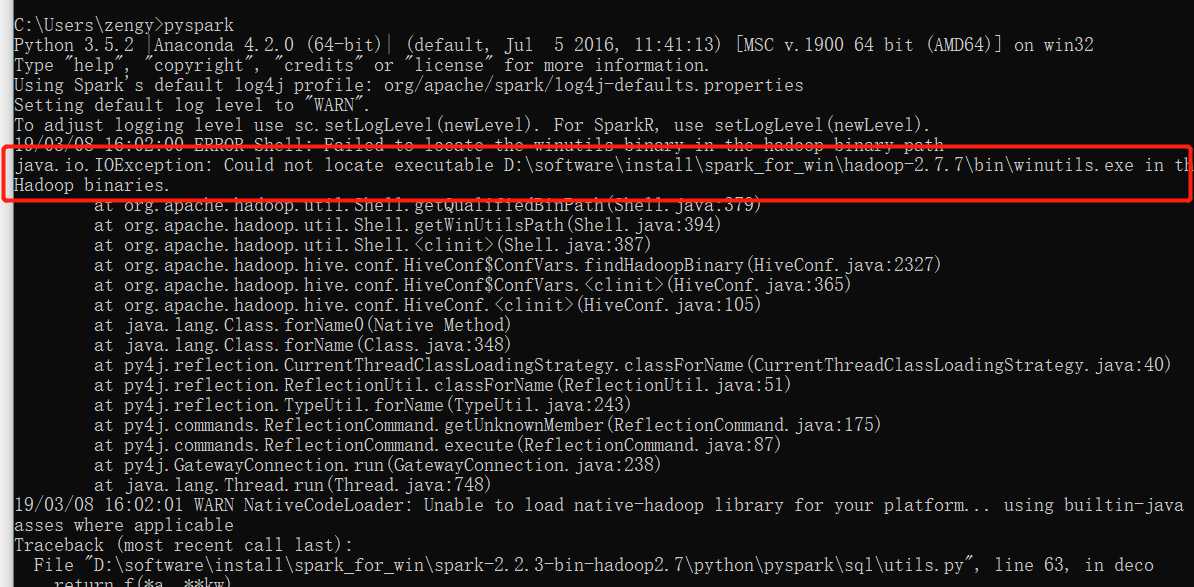
%%%解决办法,或者是问题是没有把hadooponwindows-master的bin覆盖hadoop-2.7.7的bin,导致hadoop-2.7.7里面找不到winutils.exe
(2)报了一个py4j.protocol.Py4JJavaError,这个错查了很久没有找到原因,但是我通过下面的方式解决了,不一定对,大家自己尝试下把。
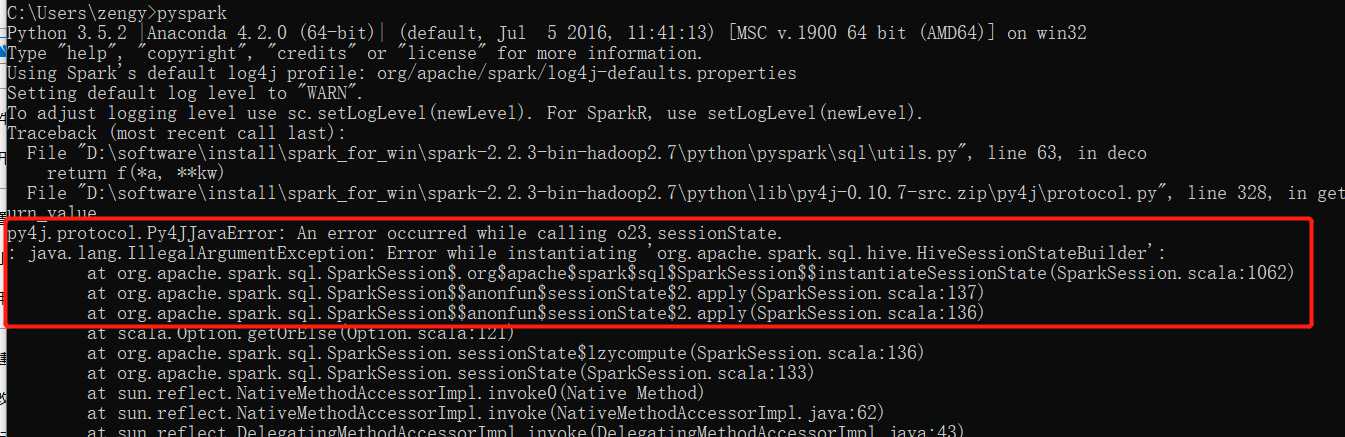
解决办法:以管理员的身份打开cmd,然后通过cd命令进入到Hadoop的bin目录下,然后执行以下命令:
winutils.exe chmod 777 c:\tmp\Hive
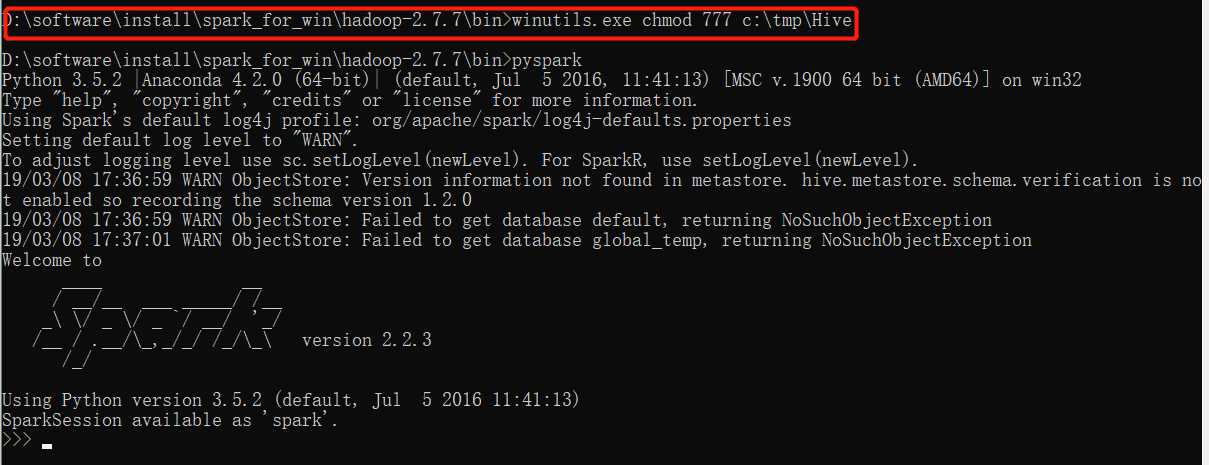
终于OK了,

标签:hellip 安装 覆盖 思路 path 环境变量 blog linux 文件
原文地址:https://www.cnblogs.com/zengyouxuan/p/10497482.html