标签:object ceo 文件的 重点 指定 gconf throw java 部分
applicationContext文件加载和bean注册流程? applicationContext.xml到底是如何加载的呢?我把他简化成以下流程,当然了每个环节里Spring的实现都是错综复杂的,也是很佩服写Spring的大神。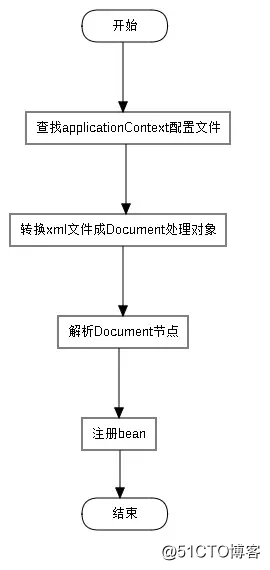
Spring初始化
? 当我们初学Spring的教程的时候,教程里面肯定会有这样的一步操作,就是新建一个applicationContext.xml文件,当然了这是Spring里必须要有的一个文件,在这个文件里面我们可以进行bean的配置等等工作,让Spring来管理我们的Bean。然后,这个文件放在哪里也是个比较讲究的事情,可能对于初学者来说可额能会往WEB-INF文件夹一放就了事了,确实这样是可以的,因为Spring默认的位置就是这个,但是我们一般不这么做,一般会把这个文件放在resource里面,那这样子做的话,你就要指定位置,让Spring知道你这个文件的位置,这就有了下面一段代码,我们的Spring项目都会在web.xml配置这样的代码:
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:applicationContext.xml</param-value>
</context-param>那问题来了,当项目启动的时候,spring是怎么去初始化应用的上下文的呢?答案就在类ContextLoader.java里面。当Tomcat启动时候会调用该类里面的一个方法public WebApplicationContext initWebApplicationContext(ServletContext servletContext),这个方法主要完成,根据我们在web.xml里面配置的contextConfigLocation初始化spring的web的应用上下文。具体看下改方法的实现(非完整代码,PS:由于太长了):
public WebApplicationContext initWebApplicationContext(ServletContext servletContext) {
......
this.context = createWebApplicationContext(servletContext);//主要代码,创建web应用上下文
......
configureAndRefreshWebApplicationContext(cwac, servletContext);//配置参数并调用初始化方法
......
}在这个方法里面有两句重要代码,第一句createWebApplicationContext(servletContext),这个会根据你配置的contextClass创建一个WebApplicationContext对象,但是我们一般不会配置这个参数,所以Spring默认会创建一个XMLWebApplicationContext对象,而这个就是后续操作的的重要对象,然后接下来一句重要代码configureAndRefreshWebApplicationContext(cwac, servletContext)这个就会去读取我们在web.xml里面配置的参数并set到变量里头去,这样Spring就能找到我们项目的applicationContext.xml文件了,到底如何找到下面会讲。接下来我们来看下configureAndRefreshWebApplicationContext方法的实现如下:
protected void configureAndRefreshWebApplicationContext(ConfigurableWebApplicationContext wac, ServletContext sc) {
if (ObjectUtils.identityToString(wac).equals(wac.getId())) {
// The application context id is still set to its original default value
// -> assign a more useful id based on available information
String idParam = sc.getInitParameter(CONTEXT_ID_PARAM);
if (idParam != null) {
wac.setId(idParam);
}
else {
// Generate default id...
wac.setId(ConfigurableWebApplicationContext.APPLICATION_CONTEXT_ID_PREFIX +
ObjectUtils.getDisplayString(sc.getContextPath()));
}
}
wac.setServletContext(sc);
String configLocationParam = sc.getInitParameter(CONFIG_LOCATION_PARAM);
if (configLocationParam != null) {
wac.setConfigLocation(configLocationParam);
}
// The wac environment‘s #initPropertySources will be called in any case when the context
// is refreshed; do it eagerly here to ensure servlet property sources are in place for
// use in any post-processing or initialization that occurs below prior to #refresh
ConfigurableEnvironment env = wac.getEnvironment();
if (env instanceof ConfigurableWebEnvironment) {
((ConfigurableWebEnvironment) env).initPropertySources(sc, null);
}
customizeContext(sc, wac);
wac.refresh();
}在这个方法中我们只要关注两个地方,第一个:
String configLocationParam = sc.getInitParameter(CONFIG_LOCATION_PARAM);
if (configLocationParam != null) {
wac.setConfigLocation(configLocationParam);
}这块代码块就是,讲我们配置在web.xml里面的参数set到我们的变量中去。第二个地方就是:
wac.refresh();调用这个执行后续的加载文件操作等后续操作。
Spring是如何找到applicationContext.xml文件
? 其实,从refresh到Spring里去查找配置文件路径之间,有很多步骤,这些也都要花点时间去理解的,在这里不展开讲,我们只要知道,XmlWebApplicationContext会委托给XmlBeanDefinitionReader类去解析配置文件,在XmlWebApplicationContext类里面有个方法loadBeanDefinitions如下:
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws IOException {
String[] configLocations = getConfigLocations();
if (configLocations != null) {
for (String configLocation : configLocations) {
reader.loadBeanDefinitions(configLocation);
}
}
}该方法就是将一个个的配置文件委托给XmlBeanDefinitionReader去解析配置文件,但是解析之前有句代码String[] configLocations = getConfigLocations();这个就是查找我们的配置的文件的方法,
protected String[] getConfigLocations() {
return (this.configLocations != null ? this.configLocations : getDefaultConfigLocations());
}实现很简单,就是我们有配置该位置地址就会去读我们配置的路径,否则就会去读默认的配置文件路径,这就是开篇说到的要是没配置路径也能读取到配置文件,前提就是要跟Spring默认定义好的文件路径及文件名保持一致才行。getDefaultConfigLocations函数的实现也很简单:
/** Default config location for the root context */
public static final String DEFAULT_CONFIG_LOCATION = "/WEB-INF/applicationContext.xml";
/** Default prefix for building a config location for a namespace */
public static final String DEFAULT_CONFIG_LOCATION_PREFIX = "/WEB-INF/";
/** Default suffix for building a config location for a namespace */
public static final String DEFAULT_CONFIG_LOCATION_SUFFIX = ".xml";
protected String[] getDefaultConfigLocations() {
if (getNamespace() != null) {
return new String[] {DEFAULT_CONFIG_LOCATION_PREFIX + getNamespace() + DEFAULT_CONFIG_LOCATION_SUFFIX};
}
else {
return new String[] {DEFAULT_CONFIG_LOCATION};
}
}如果配置了namespace就会去找这个名字的xml配置文件,如果没有配置就去找默认的配置文件。所以不管如何,这个配置文件是必须在spring项目中的。至此,配置文件基本将完,接下来就是重头戏了,就是解析xml以及xml里面的节点,并注册到spring的bean容器中去。
将xml文件转成Document处理对象
如何将xml转成Document对象,这个也是很复杂的操作,首先将resource读取InputStream流,在将InputStream流包装成InputSource对象,在处理成Document对象,直接上代码:
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
InputStream inputStream = encodedResource.getResource().getInputStream();//获取流
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}接下来又到doLoadBeanDefinitions(inputSource, encodedResource.getResource());方法去了,该方法就是生成Doucument对象的,然后就是解析具体的节点了,部分源码如下:
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
Document doc = doLoadDocument(inputSource, resource);//这就是解析成Document对象的操作
return registerBeanDefinitions(doc, resource);
......
}解析Document不展开讲了,不是本篇的重点,重点是下面的,spring如何解析xml文件的bean及注解的bean然后注册到容器中去,registerBeanDefinitions(doc, resource)是下面的重点。
解析Document里面的节点
XmlBeanDfinitionReader本身又不是直接取解析document的,他是委托给了DefaultBeanDefinitionDocumentReader类去实现,源代码中,会去创建DefaultBeanDefinitionDocumentReader对象实例,然后调用实例的注册方法,代码如下:
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}首先,我们必须知道,spring的xml文件里面有两种类型的节点,一种是默认节点,相对于默认节点之外的节点统称自定义节点,这可以从源码里面知道,而默认节点有以下几个:beans、import、alias、bean这几个节点是默认节点,而相对于这几个节点之外的都是默认节点,applicationContext里面有几个自定义节点,如下:property-placeholder、property-override、annotation-config、component-scan、load-time-weaver、spring-configured、mbean-export、mbean-server,这里面常见的有component-scan等,为什么spring要分成默认和自定义节点呢,是因为自定义节点都有特定的业务,比如component-scan,他是去扫描程序包,加载用注解定义的bean,例如开发中的service等bean,所以这些自定义节点都配备了解析器,这些解析器预先初始化好的,解析到什么节点就去获取相应的解析器去处理相应的业务,自定义节点解析器配置如下:
@Override
public void init() {
registerBeanDefinitionParser("property-placeholder", new PropertyPlaceholderBeanDefinitionParser());
registerBeanDefinitionParser("property-override", new PropertyOverrideBeanDefinitionParser());
registerBeanDefinitionParser("annotation-config", new AnnotationConfigBeanDefinitionParser());
registerBeanDefinitionParser("component-scan", new ComponentScanBeanDefinitionParser());
registerBeanDefinitionParser("load-time-weaver", new LoadTimeWeaverBeanDefinitionParser());
registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());
registerBeanDefinitionParser("mbean-export", new MBeanExportBeanDefinitionParser());
registerBeanDefinitionParser("mbean-server", new MBeanServerBeanDefinitionParser());
}从以上源码分析,我们可以得到一个推论:
我们自己可以自定义xml的节点,spring可以去解析我们自定义的xml节点。
其实这个推论明显成立,我们可以看到spring里面到处都是这种自定义的节点的。
这里又引申出一个问题:spring怎么去区分默认节点和自定义节点的呢?答案是通过节点的namespaceUri属性去判断,namespaceUri是什么东东?我们来看下,默认节点的namespaceUri是怎么样的,源码是这样定义的:
public static final String BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans";是不是很熟悉,这货就是我们配置文件里面的beans根节点会写的东西,如下:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
</beans>但是问题又来了,子节点上我们根本没配置这货,但是也能读取到,以下是个人推论:
子节点会继承父节点的属性,这就说的通,子节点即使没配置那一堆东西也能判断为默认节点。
接下来,就是解析Document的元素,从root元素开始解析,这时候spring是创建了一个解析类的代理类,所有的比较和解析操作都有该类完成,我们来看下spring的源码实现:
protected void doRegisterBeanDefinitions(Element root) {
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isInfoEnabled()) {
logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}解析节点的过程是个递归的过程,每次都要记录节点的父节点,首先会创建一个delegate对象,然后再去解析节点,调用parseBeanDefinitions(root, this.delegate);这个方法进行解析操作;
继续来看下parseBeanDefinitions(root, this.delegate);的实现:
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}很简单,可以很清晰的看出,解析是分默认节点和自定义节点分开解析的,而自定义的节点的解析其实就是找到对应的解析器各自处理对应的业务,如component-scan会找到ComponentScanBeanDefinitionParser类来处理对应的扫描包注册bean的操作,而默认的节点的处理有如下几种,代码如下:
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
//处理import
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
//处理alias
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
//处理bean
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
//处理beans
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}import的处理相对其他几种比较复杂点,但最终还是处理变成其他3种的处理,而beans的处理就重新递归上面提到的方法,最重要的是bean的处理,bean的处理其实就是下面要讲的内容,解析bean并注册bean definition的过程。
注册bean
终于到了最后一个内容了,也是最重要的一个内容,上面讲的所有都是为了这个而服务的,读取配置文件也是为了加载bean,然后注册到spring的容器里面,让spring统一管理我们定义的bean。大家都很明白,spring的bean的容器,但是如果没有去看源码的话,是不是都认为spring,是把每个实例对象注册到容器里面然后统一管理的?其实,spring其实不是这样的做的,spring注册的bean最终是个bean的定义,即BeanDefinition这个实例,并不是一个个类的具体实例。我们可以简单理解这些注册的bean definition是为了方便后续的实例化bean进行的一步准备操作。所谓的注册,其实就是把各种这些实例用一个Map来管理,所以,spring的bean的容器的底层存储其实是用Map来实现的(这个之前面试被问过)。接下来,看看源码的实现:
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
//这个是对bean definition进行修改如果有必要,如配置了代理的bean等
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name ‘" +
bdHolder.getBeanName() + "‘", ele, ex);
}
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}从源码里可以看出,bean的解析类代理会去解析ele元素,并返回一个BeanDefinitionHolder的实例,而这个BeanDefinitionHolder我们可以简单理解为BeanDefinition对象的持有对象。然后,通过调用BeanDefinitionReaderUtils工具类去执行具体的注册操作。继续看BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry())这个的实现如下:
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}从上面代码中,spring注册bean其实注册的是BeanDfinition,注册bean其实就是绑定bean的name和BeanDfinition的关系。那么,我们继续看看bean的具体注册过程,代码如下:
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
BeanDefinition oldBeanDefinition;
oldBeanDefinition = this.beanDefinitionMap.get(beanName);
if (oldBeanDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Cannot register bean definition [" + beanDefinition + "] for bean ‘" + beanName +
"‘: There is already [" + oldBeanDefinition + "] bound.");
}
else if (oldBeanDefinition.getRole() < beanDefinition.getRole()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if (this.logger.isWarnEnabled()) {
this.logger.warn("Overriding user-defined bean definition for bean ‘" + beanName +
"‘ with a framework-generated bean definition: replacing [" +
oldBeanDefinition + "] with [" + beanDefinition + "]");
}
}
else if (!beanDefinition.equals(oldBeanDefinition)) {
if (this.logger.isInfoEnabled()) {
this.logger.info("Overriding bean definition for bean ‘" + beanName +
"‘ with a different definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Overriding bean definition for bean ‘" + beanName +
"‘ with an equivalent definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<String>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
if (this.manualSingletonNames.contains(beanName)) {
Set<String> updatedSingletons = new LinkedHashSet<String>(this.manualSingletonNames);
updatedSingletons.remove(beanName);
this.manualSingletonNames = updatedSingletons;
}
}
}
else {
// Still in startup registration phase
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
this.manualSingletonNames.remove(beanName);
}
this.frozenBeanDefinitionNames = null;
}
if (oldBeanDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
}这段代码还是比较容易理解的,首先先判断容器里面有没这个bean,没有的话判断是否在创建过程,如果不是直接将该bean注册到容器里并设置其他信息。简单的说,其实就是将一个个的bean的定义跟bean的名称绑定起来,存放到map里面。至此,spring加载applicationContext.xml的大致流程已经说清楚了,不过这里面涉及很多比较细又难懂的类并没有体现出来,最终要的是搞清楚spring加载配置文件的过程和注册bean的过程。要想深入,可以继续研读源码。
总结
通过该篇文章,我们弄清楚了spring的applicationContext.xml文件的加载和bean的注册过程。可以说配置文件解析只是spring为了后续的bean的实例化操作的准备阶段,即为需要实例化的bean准备bean definition。
Spring源码解析-applicationContext.xml加载和bean的注册
标签:object ceo 文件的 重点 指定 gconf throw java 部分
原文地址:https://blog.51cto.com/13981400/2360281