标签:follow 之间 master 代码 ast ati 文化 lan 传递
在以前的文章中,我写过一篇使用selenium来模拟登录知乎的文章,然后在很长一段时间里都没有然后了。。。
不过在最近,我突然觉得,既然已经模拟登录到了知乎了,为什么不继续玩玩呢?所以就创了一个项目,用来采集知乎的用户公开信息,打算用这些数据试着分析一下月入上万遍地走、清华北大不如狗的贵乎用户像不像我们想象中的那么高质量。
第一步:首先是爬虫抓取用户信息,能用图解释的绝不多废话:
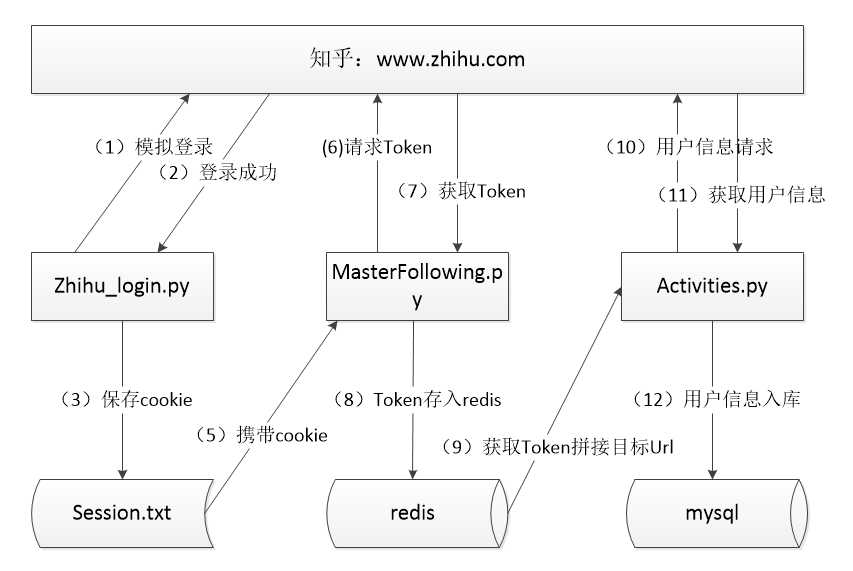
但是还是得主要说下:
首先:个人感觉,在写一些小的demo时用框架就反而更显得繁琐,所以我没有使用框架,而是自己使用requests来发起请求的。
然后简要解释一下整体流程:
(1)zhihu_login.py 是我模拟登录的脚本,并且在前三步中,理想状态下是利用schedule写一个定时执行框架,定期的更换session.txt中的cookie以供后边的抓取脚本使用,然而非常无奈,
这个方法是我在最后数据抓取基本结束时才想到的,所以没有用到,所以我在抓取数据时使用了代理IP.的。
(2)画图时将错误的将第4步写成了第5步。。。MasterFollowing.py是用来获取用户唯一标示:Token的,原理是:以一个用户的url作为起始地址发起请求,遍历该用户的关注列表,将关注列表中的所有用户Token都存入redis中,
下一次请求时,将会从redis中随机取出一个Token拼接成目标url再遍历关注列表将Token存入redis中,因为理论上从redis中取出一个Token就会向里边塞入少则几十多达上百个Token(视该用户关注人数而定),所以理论上redis中的Token值会越来越多,
且我是以set类型来存Token的,所以会自动去重,非常方便。
(3)activities.py是用来抓取最终用户信息的,它每次redis中获取一个Token,拼接成目标Url,请求用户详情页面,采集到用户信息,将其存入到数据库中。
(4)因为两个脚本之间使用redis进行数据共享,即使有哪个蜘蛛宕掉,也不会造成数据丢失,达到了断点续传的效果。
(5)整个过程中,唯一扯淡的是,知乎似乎对并发数做出了限制,当并发请求超过某一阀值时,请求就会被重定向到验证页面,即使使用了代理IP也没用。不过我想,如果用我最终想到的方法每隔一段时间模拟请求,更换cookie的话,
这个问题有可能会得到解决。
整个爬虫项目我在个人github上边扔着,大家可以去拉下来玩玩,感兴趣的可以帮我把代码完善下,把那个定时更新cookie的代码加上,或者各位有什么更好的方法,也可以告诉我。
github地址:https://github.com/songsa1/zhihu_user_relationship
第二步:使用抓取下的数据进行简单分析
大概抓了20w左右的数据,并且数据分析的代码也在上边那个项目中丢着,制作图表使用了matplotlib.
首先我们知道,知乎个人信息中,所属行业一共分为了14大类、98小类:

我们先看看按照小类来分的话,知乎用户群体主要是做什么的呢?
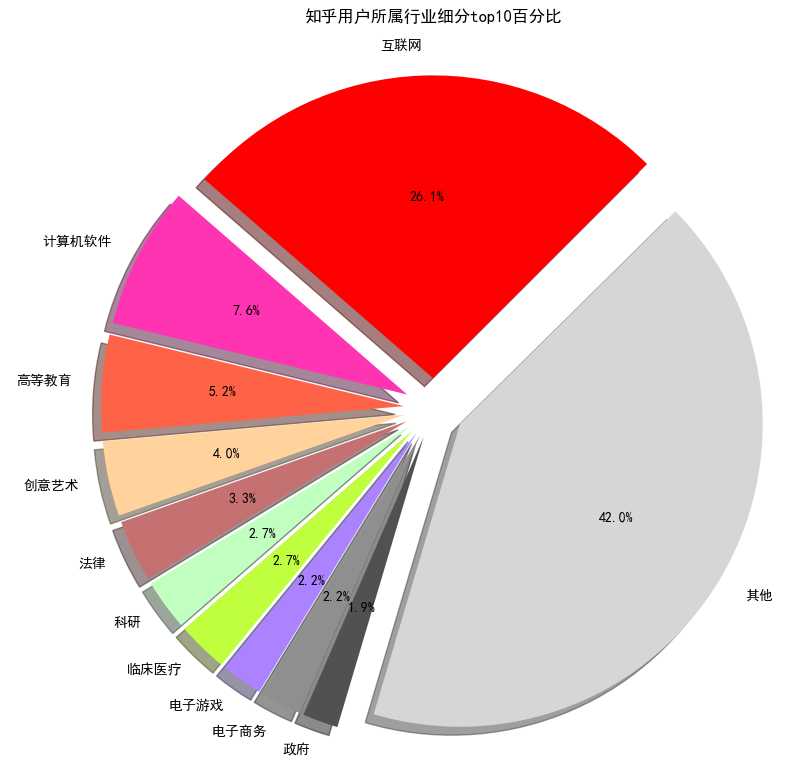
不出所料啊,互联网行业果然是最多的,当然,也有存在误差的可能,我是以我的知乎用户作为起点来抓取的,我关注的人中基本都是互联网圈中的,这样传递下去,采集到的数据中IT圈中的人估计会多一些,不过窥一斑而知全豹,真实情况估计也差不太多。
这次按照14大类来瞅一下:
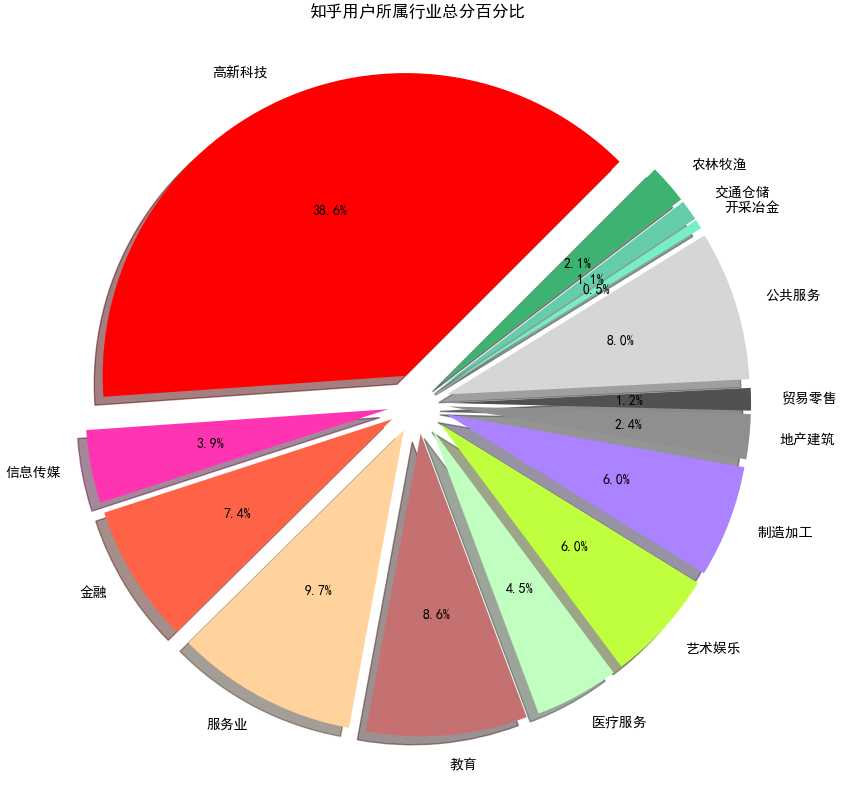
依旧是高新科技位居第一啊,教育行业和服务行业紧随其后。
然后我们再来看看知乎用户群体的性别比例:
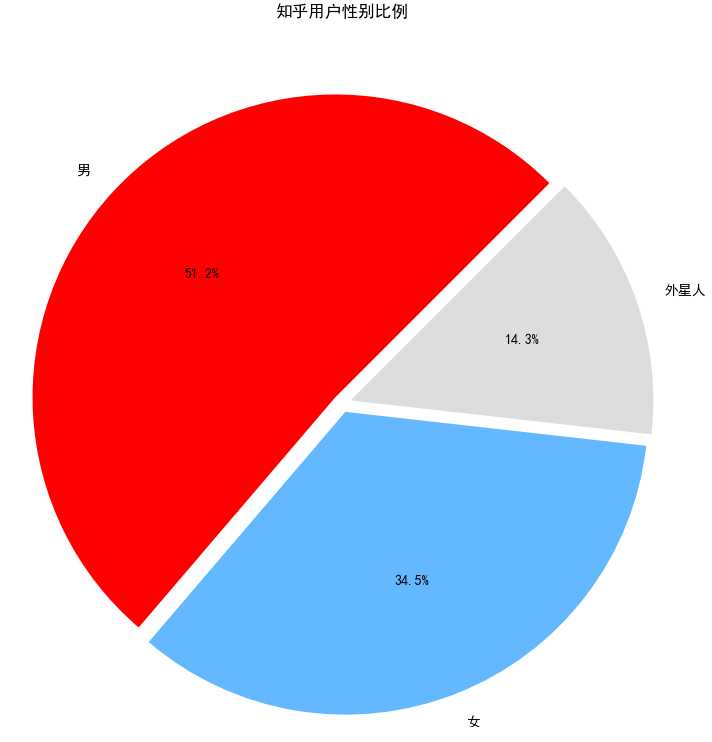
果然男性用户占据了一半还多,女性用户只占了34%,当然还有14%没有填性别的外星人。
我们一直说逼乎贵乎,一听起来就很有档次的感觉,不负众望,知乎用户群体的文化程度还是非常高的,果然清华北大遍地走,985、211不如狗啊,有图为证(词云中字体越大表明权重越大):
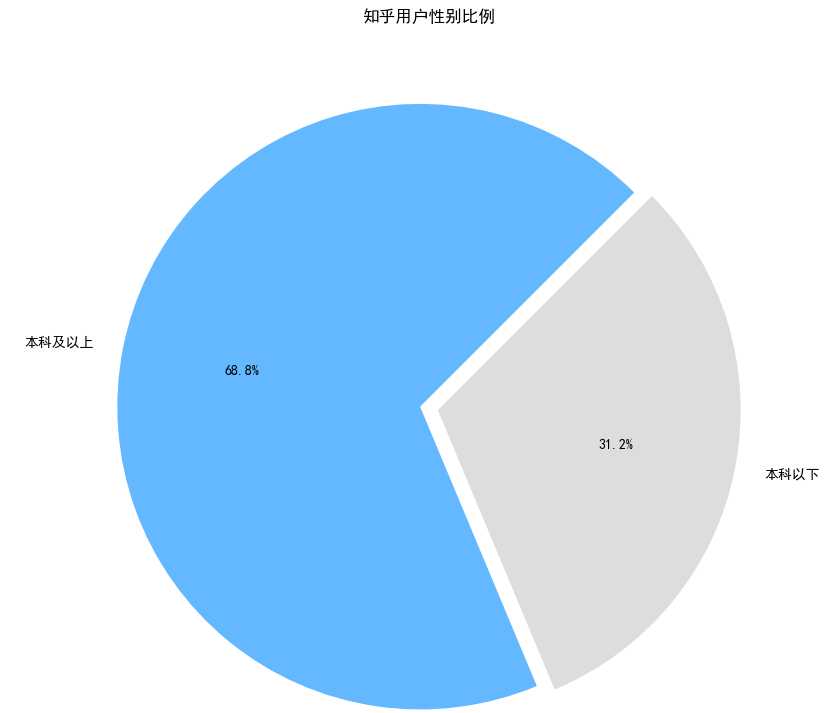

最后我们来看看知乎用户群体大概居住地,目测北上广等一线新一线比较多:

好了,这一次大概就说这么多,想要了解更多python爬虫、数据分析那些事儿,请关注我的个人微信公众号:进阶的爬虫

标签:follow 之间 master 代码 ast ati 文化 lan 传递
原文地址:https://www.cnblogs.com/ss-py/p/10498728.html