标签:范围查询 必须 定义 就会 遇到 iam 它的 b+tree 解决
众所周知,二叉查找树是每个结点最多有两个子树的树结构,通常子树被称为左子树或者右子树。二叉查找树的重要知识:对于树中的每一个节点,其左子树任意节点的值均小于该节点,其右子树的任意节点的值均大于该节点。大致结构如下图:
该图为平衡二叉树,即任意节点的左子树和右子树的高度相差不超过1。
二叉查找树的查找用的是二分查找,比如查询结点6,从根节点开始查找,因为6>5,所以从右孩子开始查找,下一步7>6 ,找到7的左孩子,因此定位到6。其时间复杂度为O(logn),查询效率高。
下面讲一下二叉查找树的缺点。当二叉树的将节点2和节点6删除时,再插入节点11、13等值,其结构变为一个线性的二叉树,如下图:
此时,查询时间复杂度变成O(n),大大降低了查询效率。
你可能会说,可以利用树的旋转的特性,来保持该树为平衡二叉树,这样其时间复杂度为维持在O(logn)。这样确实解决了查询效率的问题,但还有一个问题未解决,现在假定这些索引块都在磁盘中,以上面查找节点6为例,每次查询会进行一次IO操作,将节点读到内存中,5 -> 7 ->6的查询进行了三次IO操作,随着树的深度不断增加,大大增加了IO操作次数, 这样的检索性能比全表扫描要慢得多,无法满足优化查询的需求。
B-Tree需求遵守以下的约束:
a) 根节点至少包括两个孩子
b) 树中每个节点最多含有m 个孩子 (m>=2)
c) 除根节点和叶节点外,其他每个节点至少有ceil(m/2)个孩子
(ceil指取上限,如果m=3,则ceil(m/2)=2 )
d) 所有叶子节点都位于同一层
下图为3阶B-Tree,每个节点最多3个孩子。当然现实场景中,每个节点的孩子数n肯定远大于3,称为n阶B-Tree。每个存储块主要包含了关键字指向孩子的指针。遵守B-Tree的这些约束的目的只有一个:就是让每个索引块尽可能存储更多的信息,让树的高度尽可能减少IO次数。

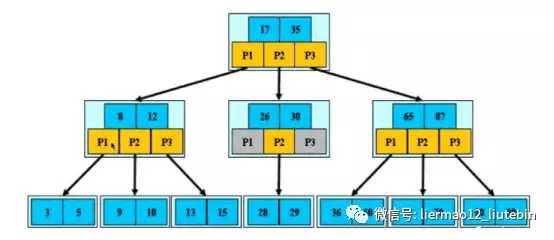
假设每个非终端结点中包含有n个关键字信息,其中
a) Ki(i=1...n)为关键字,且关键字按顺序升序排序K(i-1)<Ki, 如上图的8<12
b) 关键字的个数n必须满足:[ceil(m/2)-1]<= n <= m-1,如上图关键字8和12比P1、P2、P3少一个
c) 非叶子结点的指针:P[1],P[2],....P[M] ;其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1],K[i])的子树,如上图3和5均小于8和12,而13和15均大于8和12,9和10位于8和12的区间内。
现在如果要查询15,则路径为:[17,35]:P1->[8,12]:P3->13->15,查询效率也是O(logn)。
当数据发生变动的时候,必然会存在现有结构被打乱的情况,如果是二叉查找树,可能会被打乱成线性的,则B-Tree则有相应的策略通过合并、分裂、上移、下移节点来保持其特征,不会变成线性的结构,远比二叉树矮得多。
B+树是B树的变体,其定义基本与B树相同,除了:
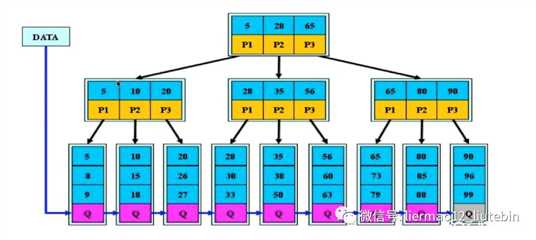
a)非叶子节点的子树指针与关键字个数相同
b)非叶子节点的子树指针P[i],指向关键字值[K[i],K[i+1])的子树,如下图 10 对应的子树中的值均小于20,同时均大于等于10。
c)非叶子节点仅用来索引,数据都保存在叶子节点中,因此B+树所有的检索都是从根部开始一直检索到叶子节点,非叶子节点仅用来存储索引,不存储数据,便可以存储更多的关键字,使得B+树相对于B树来说更矮。
d)所有叶子节点均有一个链指针指向下一个叶子节点,方便我们直接在叶子节点做范围统计。比如检索大于或等于10的数据,则在下图的第二个叶子节点直接开始从左往右检索。
结论:
B+Tree更适合用来做存储索引:
a) B+树的磁盘读写代价更低,因为B+树不存放索引的数据,只存放索引信息,因此内部节点相比B树更小 ,如果把所有同一内部节点的关键字存放在同一盘块中,这个盘块所能容纳的关键字数量也越多,一次性读入内存中的需要查找的关键字也就越多,相对来说,IO读写次数也就降低了。
b) B+树的查询效率更加稳定,由于内部节点并不是最终指向文件内容的节点,而只是叶子节点中关键字的索引,所以任何关键字的查找必须走一条从根节点到叶子节点的树,所有关键字查询的长度相同,导致每个关键字的查询效率都是相同的、稳定的O(logn)
c) B+树更有利于对数据库的扫描,因为B+树只需要遍历叶子节点便可以实现对全部关键字的扫描,比如在范围查询有更高的性能,因而B+树是现在主流的数据库索引结构。
四、Hash索引
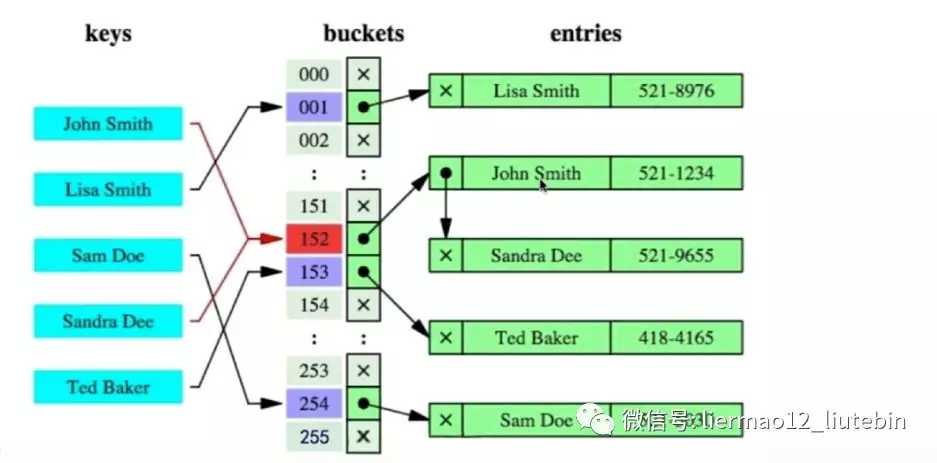
根据哈希函数的运算,只需经过一次定位,便能找到需要查询数据所在的桶,不像B+索引需要从根节点到非叶子节点再到叶子节点才能找到数据, 这样可能会造成多次的IO访问,所以Hash索引的查询效率理论上高于B+树。
但Hash索引的缺点导致它不能做为主流索引:
a)仅仅能满足“=”,“IN”,不能使用范围查询
b)无法被用来避免数据的排序操作,因为索引的值是被Hash运算过,所以值并无规律。
c)不能利用部分索引键查询,比如组合索引会被一起被Hash运算,通过其中一个索引无法找到对应的哈希值。
d)不能避免表扫描
e)遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高
五、BitMap索引
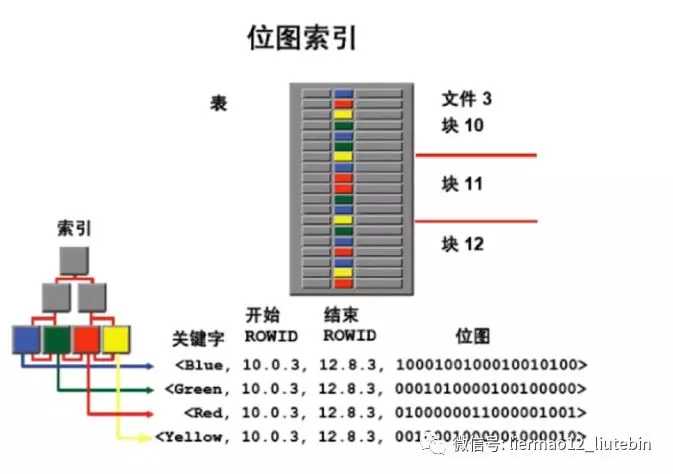
当表中的某个字段只有几种值的时候,比如性别字段只有男和女两种情况,如果仅仅是在这个字段实现高效的统计,此时用位图索引是一个最佳的选择,但目前很少数据库支持位图索引,比较主流的是Oracle数据库。
位图索引有一个很大的缺陷,它的锁的力度非常强大,当尝试新增或者修改某条数据的时候,通常与它在同一个位图的数据操作都会被锁住,所以它并不适合高并发系统,而适合低并发且统计需求高的系统。
更多内容请扫描二维码关注“码农TT”

标签:范围查询 必须 定义 就会 遇到 iam 它的 b+tree 解决
原文地址:https://www.cnblogs.com/liermao12/p/10504121.html