标签:png div 现在 了解 输入 过程 str tran int
目前机器学习、深度学习在业界使用的越来越广泛,做为一个有着技术追求的it人,我觉得有必要学习和了解一下这块的知识,今天就从最简单的单层神经网络开始介绍。
在介绍人工神经网络之前,首先认知下神经元。
不知道大家还有印象这个图吗?这个是出现在我们生物课本中的一幅图。
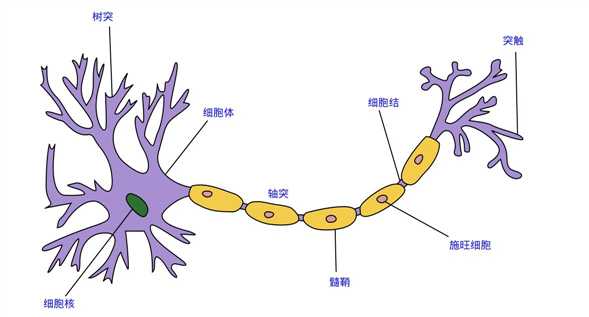
一个神经元的组成基本就是上图这些东西组成。
通常一个神经元具有多个树突,主要用来接受传入信息信息,信息通过轴突传递进来后经过一系列的计算(细胞核)最终产生一个信号传递到轴突,轴突只有一条,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。轴突末梢跟其他神经元的树突产生连接,从而传递信号。这个连接的位置在生物学上叫做“突触”。
也就是说一个神经元接入了多个输入,最终只变成一个输出,给到了后面的神经元,那么基于此,我们尝试去构造一个类似的结构。
神经元的树突我们类比为多条输入,而轴突可以类比为最终的输出。
这里我们构造一个典型的神经元模型,该模型包含有3个输入,1个输出,以及中间的计算功能。
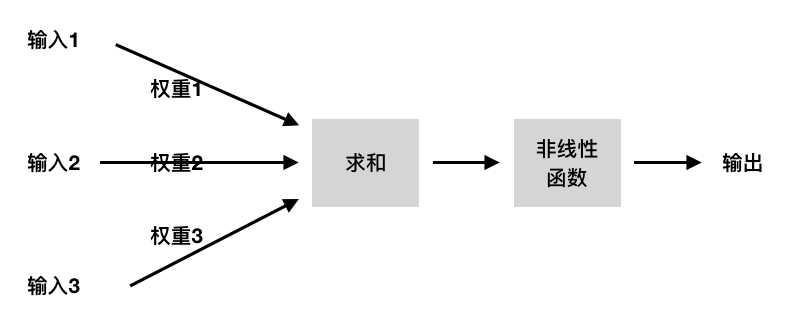
注意在每一个输入的“连接”上,都有一个对应的“权值”。
说个通俗的例子来理解下权值。比如今天你要决定今是否要去看电影,可能要考虑这3个因素: 1、女朋友有没有时间,2、有没有好看的电影,3、今天工作忙不忙; 而这三个因素对于每个人来说权重都是不同的,因为有的人看重工作、有的人看重家人,不同的权重最终的结果也会不一样。
因此权重的大小是比较关键的。而一个神经网络的训练算法就是让权重的值调整到最佳,以便使得整个网络的预测效果最好。
接下里,我们用数学的方式来表示一下神经元,我们定义 w为权重,x为输入
$$ w = \begin{bmatrix} w_{1} \\ ... \\ w_{m} \end{bmatrix} , x = \begin{bmatrix} x_{1} \\ ... \\ x_{m} \end{bmatrix}$$
$$ z = w_{1} * x_{1} + ... + w_{m} * x_{m} $$
z输入的总和,也就是这两个矩阵的点乘,也叫内积。这里补充点数学知识。
?$$ z = w_{1} * x_{1} + ... + w_{m} * x_{m} = \sum\limits_{j=1}^{m} w_{j} * w_{j} = w^{T}*x $$
$\phi$(z) = { 1 if z>=θ; -1 otherwise
注意这里有一个阈值 θ ,阈值的确定也需要在训练过程中进行完成。
那么如何进行训练,这里的我们需要用到感知器(preceptron)算法,具体过程分为下面这么几个步骤:
1、首先将权重向量w进行初始化,可以为0或者是[0,1]之间的随机数;
2、将训练样本输入感知器(计算内积后输入激活函数得到最终结果),最后得到分类的结果(结果为1 或 -1);
3、根据分类的结果再次更新权重向量w;
前面提到激活函数是当z值大于一定的阈值? θ 后,才进行激活或者不激活。因此为了计算方便呢,我们再多加入一组向量,w0 和 x0 ,w 取 -θ ,x0 取 1;将其放到等式左边,这样当 z>0 的时候 激活函数输出 1,而 z<0 激活函数输出 -1。
$$ z = w_{0} * x_{0} + w_{1} * x_{1} + ... + w_{m} * x_{m} $$
$\phi$(z) = { 1 if z>=0; -1 otherwise
权重更新
好,前面所有的准备都已经完成,接下来我们看下刚才提到的第三步,权重向量的更新,其实也就是神经网络训练的过程:
权重的更新每一轮迭代 Wj = Wj+ ? ▽Wj
而 ▽Wj = η * ( y - y‘ ) * Xj
上式中 η 叫做学习率,是[0, 1]之间的一个小数,由我们自己定义;y是真实 的样本分类,而 y’ 是感知器计算出来的分类。
我们可以简单推导一下,当 y 和 y‘ 相等,?▽Wj 的值为0,Wj则不会更新。对应的意义就是真实和预测的结果是相同的,因此权重也不需要再更新了。
这里举个例子 :
假设初始化 W = [ 0, 0, 0] , X = [1, 2, 3], 假设定义 η = 0.3,y = 1,y‘ = -1
▽W(1) = 0.3 * (1 - (-1)) * X(1) = 0.3*2*1 = 0.6; W(1) = W(1) + ▽W(1) = 0.6;
▽W(2) = 0.3 * (1 - (-1)) * X(2) = 0.3*2*2 = 1.2; W(1) = W(1) + ▽W(1) = 1.2;
▽W(3) = 0.3 * (1 - (-1)) * X(3) = 0.3*2*3 = 1.8; W(1) = W(1) + ▽W(1) = 1.8;
更新之后的向量 w = [0.6, 1.2, 1.8] 然后接着继续计算,更新。
阈值更新
前面提到,我们将阈值经过变换后变成了 w0,再每一轮的迭代训练过程中,w0也需要跟着一起更新。
最初w0 也需要初始化为0,因为x0等于1,因此 ▽W(0) = η * ( y - y‘ ) ;
这里很多人可能会和我开始有一样的疑惑,阈值不是提前定义好的吗?其实不是的,这里不断的迭代,其实就是阀值计算的过程,和权重向量一样,最终都是通过一轮一轮更新计算出来的,由于一开始我们设定的w0 = - θ,所以当最终我们的阀值更新出来后,-w0 就是我们学习出来的阀值。
看到上面的过程是否有些晕,从整体上看,其实就是这样一个过程:
初始化权重向量和阈值,然后计算预测结果和真实结果是否存在误差,有误差就根据结果不断的更新权重,直到权重计算的结果最终达到最佳,权重的值就是我们学习出的规律。
感知器目前的适用场景为线性可分的场景,就是用一条直线可以分割的二分类问题。
用python实现了上述过程,可以看下:
#-*- coding:utf-8 -*- # 简单神经网络 感知器 import numpy as np reload(sys) sys.setdefaultencoding("utf-8") class Perception(object): ‘‘‘ eta: 学习率 η time: 训练次数 w_: 权重向量 ‘‘‘ def __init__(self, eta = 0.01, time=10): self.eta = eta self.time = time pass ‘‘‘ 输入训练数据,X为输入样本向量,y对应样本分类 X:shape[n_samples, n_features] X:[[1,2,3], [4,5,6]] n_samples : 2 n_features: 3 y:[1, -1] ‘‘‘ def fit(self, X, y): # 初始化权重向量为0,加一为w0,也就是损失函数的阈值 self.w_ = np.zero[1 + X.shape[1]] self.errors_ = [] for _ in range(self.time): errors = 0 # x:[[1,2,3], [4,5,6]] # y:[1, -1] # zip(X,y) = [[1,2,3,1], [4,5,6.-1]] for xi, target in zip(X, y): # update = η * ( y - y‘ ) update = self.eta * (target - self.predict(xi)) # xi 为向量, 这里每个向量都会乘 self.w_[1:] += update * xi self.w_[0] += update; errors += int(update != 0.0) pass # 损失函数 def predict(self, X): # z = w1*x1+...+wj*xj + w0*1 z = np.dot(X, self.w_[1:]) + self.w_[0] # 损失函数 if z >= 0.0: return 1 else: return -1
标签:png div 现在 了解 输入 过程 str tran int
原文地址:https://www.cnblogs.com/by-dream/p/10497816.html