标签:出现 多行 ima order by logs ros 自己 htm char
转自:https://www.cnblogs.com/w-gao/p/7288293.html
max(字段值) -- 求最大值
min(字段值) -- 求最小值
sum(字段值) -- 求总和
avg(字段值) -- 求平均值
count(字段值) -- 求个数
group by : 用于对查询的结果分组统计
having 子句:用于过滤分组显示的结果
案例:
1.显示每个部门的平均工资和最高工资?
select avg(sal),max(sal) from emp group by deptno
2.显示每个部门的每种岗位的平均工资和最低工资?
select avg(sal),min(sal) from emp group by deptno,job
3.显示平均工资低于2000的部门号和它的平均工资?
select avg(sal) deptno from emp group by deptno having avg(sal) < 2000;

原理:
笛卡儿积: 在多表查询的时候,如果不带任何条件,则会出现笛卡儿积现象。
规定: 多表查询的条件至少不能少于表的个数-1;
案例:
1.显示雇员名,雇员工资及所在部门的名字?
select e.ename,e.sal, d.deptno
from emp e,dept d
where e.deptno = d.deptno
order by d.deptno;
2.显示部门号为10的部门名、员工名和工资?
select d.dname, e.ename, e.sa
l from emp e, dept d
where e.deptno = d.deptno and d.deptno = 10;
3.显示各个员工的姓名,工资,及其工资的级别?
select emp.ename ,emp.sal , salgrade.grade
from emp,salgrade
where emp.sal between salgrade.losal and salgrade.hisal;
案例:
1.显示“FORD”的上级?
select * from emp where emp.empno =
(select mgr from emp where ename = ‘FORD‘);
2.显示各员工的姓名和他上级领导的姓名?
select worker.ename, boss.ename
from emp worker ,emp boss
where worker.mgr = boss.empno;
嵌入到其他sql语句的select语句,也叫嵌套查询。
定义: 返回一行数据的子查询
案例:
如何显示SMITH同一部门的所有员工?
select * from emp where emp.deptno =
(select deptno from emp where ename = ‘SMITH’) and ename != ‘SMITH‘;
定义:返回多行数据的子查询
案例:
显示10号部门的工作相同的员工姓名,工作?
select ename,job from emp where job in (
select job from emp where deptno = 10);
all( 大于最大的):
如何显示工资比30号部门高的员工的姓名、工资、部门号
select ename,sal,deptno from emp where sal > all(select sal from emp where emp.deptno = 30);
等效于
select ename,sal,deptno from emp where sal > (
select max(sal) from emp where deptno =30);
any( 大于最小的):
如何显示工资比30号部门任意员工高的员工的姓名、工资、部门号
select ename,sal,deptno from emp where sal > anyl(select sal from emp where emp.deptno = 30);
等效于
select ename,sal,deptno from emp where sal > (
select min(sal) from emp where deptno =30);
如何查询与smith的部门和岗位完全相同的所有雇员
select * from emp where (deptno,job) =
(select deptno,job from emp where ename = ‘SMITH’);
----------------------------------------------------
注: “(deptno,job) =(select deptno,job ”是有顺序的
定义: 将select查询结果当作一个虚表处理
案例:
显示高于自己部门的平均工资的员工信息?
select t1.ename, t1.sal,t2.myavg from
emp t1,( select avg(sal) myavg ,deptno from emp group by deptno) t2
where t1.deptno = t2.deptno and t1.sal > t2.myavg;
显示每个部门的信息(编号,名称) 和人数?
select t1.dname, t1.deptno,t2.num from dept t1 , (select count(*) num,deptno from emp group by deptno) t2
where t1.deptno = t2.deptno(+);
--------------------------------------------------------
(+) 在左表示右外连接,在右表示左外连接
mysql:
select * from 表名 where 条件 limit 从第几条取,取几条
sql server:
select top 4 * from 表名 where id not in (select top 4 id from 表名 where 条件)
---------------------------
排除前4条,再取4条,实际上是5-8条
oracle:
格式:
select * from (select rownum rn,t1.* from (select * from 表名 [ where 条件]) where rownum <= 末尾) t2 where t2.rn >= 开始;
---------------------------
rownum:伪列,用于显示数据的行索引。
select * from emp where rownum > = 3
说明: 因为oracle的行索引(rownum)是从第1开始索引的,所以不能用>=(条件无法成立),可以用<=。
解决: 采取截取结果集的方式,将已经查询好的查询结果再进行过滤。
三层:
第一层: select * from 表名 [ where 条件] --放条件,比如排序等
第二层: select rownum rn,t1.* from (select * from 表名 [ where 条件]) where rownum <= 末尾 --决定末尾位置
第三层: select * from (select rownum rn,t1.* from (select * from 表名 [ where 条件]) where rownum <= 末尾) t2
where t2.rn >= 开始; --决定开始位置
拓展:
复制表: create table mytest as select empno,ename,sal,comm,deptno from emp;
插入表:insert into mytest(empno,ename,sal,comm,deptno) select empno,ename,sal,comm,deptno from mytest;
内连接: 笛卡儿积过滤后的连接
案例:
select * from emp inner join dept on emp.deptno = dept.deptno;
等效于
select * from emp,dept where emp.deptno = dept.deptno
外连接:
案例:
测试表
学生表:
create table stu (id number,name varchar2(32));
insert into stu values(1,’tom’);
insert into stu values(2,’jerry’);
insert into stu values(3,’jack’);
insert into stu values(4,’rose’);
成绩表
create table exam(id number,grade number(6,2));
insert into exam(1,56);
insert into exam(2,76);
insert into exam(11,86);
要求1:显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号,成绩为空
select stu.id,stu.name,exam.grade from stu inner join exam on stu.id = exam.id;
结果:
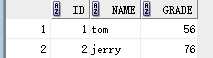
原因:在笛卡儿积连接之后,相同条件的才会匹配
左连接:select stu.id,stu.name,exam.grade from stu left join exam on stu.id = exam.id;
另一种写法: select stu.id,stu.name,exam.grade from stu , exam where stu.id = exam.id(+);
结果:
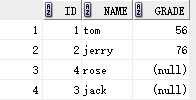
原因:连接后的数据以左边表为基准,即使对应的右边没有数据,也要显示为空。
要求2:显示所有成绩,如果没有名字匹配,显示空
右连接:select stu.id,stu.name,exam.grade from stu right join exam on stu.id = exam.id;
另一种写法: select stu.id,stu.name,exam.grade from stu , exam where stu.id(+) = exam.id;
结果:
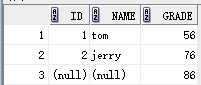
原因:连接后的数据以右边表为基准,即使对应的左边没有数据,也要显示为空。
小结: 左右外连接可以互为转换
比如:显示所有成绩,如果没有名字匹配,显示空
可以写出:select stu.id,stu.name,exam.grade from exam left join stu on stu.id = exam.id;
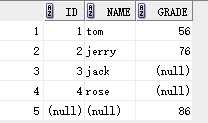
案例3:显示所有的成绩和所有人的名字,如果没有匹配值,就显示空
完全外连接:两个表查询,不管有么有匹配,都显示。
select stu.id,stu.name,exam.grade from exam full outer join stu on stu.id = exam.id;
结果:
标签:出现 多行 ima order by logs ros 自己 htm char
原文地址:https://www.cnblogs.com/sharpest/p/10508331.html