标签:font sort 垃圾收集 pat 最大 12px tin 包括 any
1、python常用的数据类型。
int、float、str、set、list、dict、tuple、frozenset、bool、None。
2、docstring是什么?
Docstring是一种文档字符串,用于解释构造的作用。我们在函数、类或方法中将它放在首位来描述其作用。我们用三个单引号或双引号来声明docstring。
要想获取一个函数的docstring,我们使用它的_doc_属性。
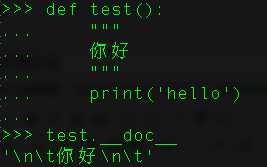
3、PYTHONPATH变量是什么?
PYTHONPATH是Python中一个重要的环境变量,用于在导入模块的时候搜索路径。因此它必须包含Python源库目录以及含有Python源代码的目录。你可以手动设置PYTHONPATH,但通常Python安装程序会把它呈现出来。

可以看到,路径列表的第一个元素为空字符串,代表的是相对路径下的当前目录.
由于在导入模块的时候,解释器会按照列表的顺序搜索,直到找到第一个模块,所以优先导入的模块为同一目录下的模块.
导入模块时搜索路径的顺序也可以改变.这里分两种情况:
1>通过sys.path.append(),sys.path.insert()等方法来改变,这种方法当重新启动解释器的时候,原来的设置会失效.
2>改变PYTHONPATH,这种设置方法永久有效:
4、什么是切片?
切片是Python中的一种方法,能让我们只检索列表、元素或字符串的一部分。在切片时,我们使用切片操作符[]。
只有str、tuple、list等序列组合具有切片的功能。
5、什么是namedtuple ?
namedtuple类位于collections模块,有了namedtuple后通过属性访问数据能够让我们的代码更加的直观更好维护。
namedtuple能够用来创建类似于元祖的数据类型,除了能够用索引来访问数据,能够迭代,还能够方便的通过属性名来访问数据。
在python中,传统的tuple类似于数组,只能通过下标来访问各个元素,我们还需要注释每个下表代表什么数据。通过使用namedtuple,每个元素有了自己的名字。类似于C语言中的struct,这样数据的意义就可以一目了然。声明namedtuple是非常简单方便的。
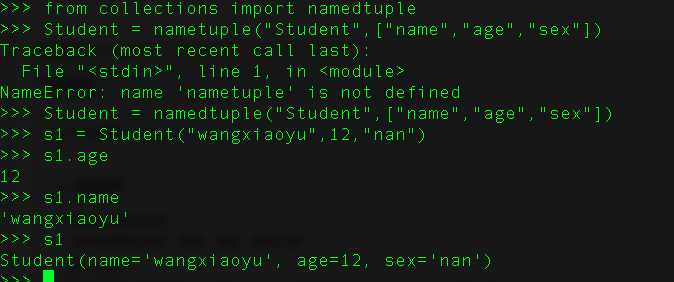
Q 6. 在Python中如何声明一条注释?
单行注释
Python编程语言的单行注释常以#开头,单行注释可以作为单独的一行放在被注释代码行之上,也可以放在语句或者表达式之后。
实例:
# -*- coding: UTF-8 -*-
print ("hello world!"); #您好,世界
多行注释
Python中多行注释使用三个单引号(’’’)或者三个双引号(”””)来标记,而实际上这是多行字符串的书写方式,并不是Python本身提倡的多行注释方法。
实例:
‘‘‘
这是多行注释,使用单引号。
这是多行注释,使用单引号。
‘‘‘
"""
这是多行注释,使用双引号。
这是多行注释,使用双引号。
"""
编码注释
在进行Python开发时,需进行编码声明,如采用UTF-8编码,需在源码上方进行 # -*- coding: UTF-8 -*- 声明,从Python3开始,Python默认使用UTF-8编码,所以Python3.x的源文件不需要特殊声明UTF-8编码。
平台注释
如果需要使Python程序运行在Windows平台上,需在Python文件的上方加上 #!/usr/bin/python 注释说明。
Python注释除了可以起到说明文档的作用外,还可以进行代码的调试,将一部分代码注释掉,对剩余的代码进行排查,从而找出问题所在,进行代码的完善!
7、 在Python中怎样将字符串转换为整型变量?
如果字符串只含有数字字符,可以用函数int()将其转换为整数。
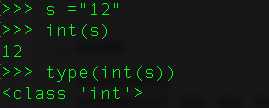
8、在Python中怎样获取输入?
使用input()。在python2中还可以使用raw_input()用来回去输入的整数。在python3中得使用int()来转换
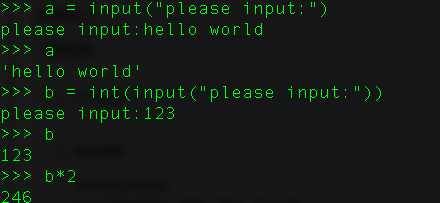
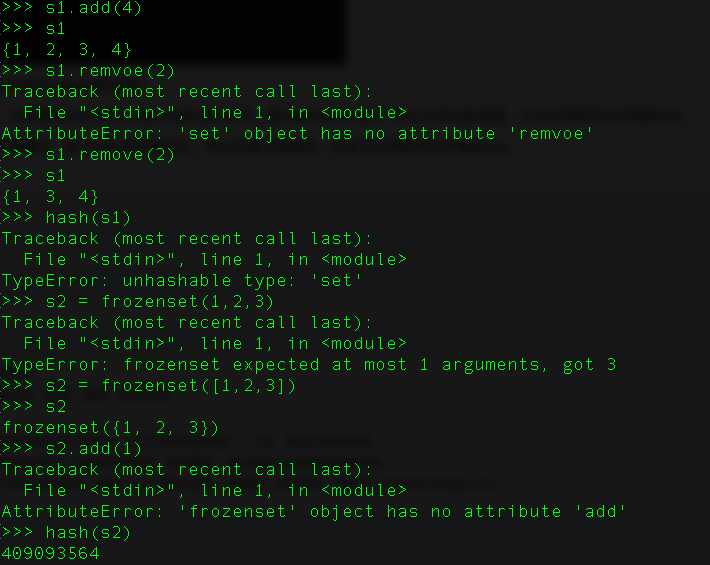
9、python中的set和frozenset的区别?
set是可变集合,可以使用add,remove等方法来进行修改。因为是可以修改的,所以不存在哈希值,不可以用来作为字典的key。
forzenset是不可变集合,是不可以进行修改的,所以它是可哈希的,并且可以用来作为字典的key。
集合都是不支持索引的,同时是具有去重功能的。
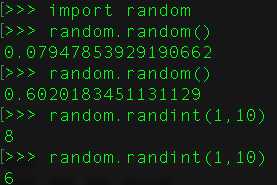
10、在Python中如何生成一个随机数?
要想生成随机数,我们可以从random模块中导入函数random()。
11、怎样将字符串中第一个字母大写?
最简单的方法就是用capitalize()方法。

12、如何检查字符串中所有的字符都为字母数字?
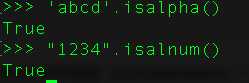
还有其他很多的关于字符串的方法,可以使用dir函数来查看,并继续测试。
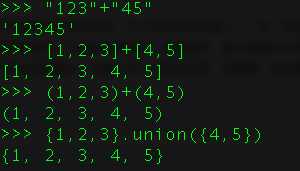
13、 什么是Python中的连接(concatenation)?
Python中的连接就是将两个序列连在一起,我们使用+运算符完成。
同样是str、tuple、list等序列组合可以使用。而set并不可以,如果要连接两个set,使用union()求并集的方法。
14、 什么是函数?
当我们想执行一系列语句时,我们可以为其赋予一个名字。
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
我们以自定义一个求绝对值的my_abs函数为例:
def my_abs(x):
if x >= 0:
return x
else:
return -x
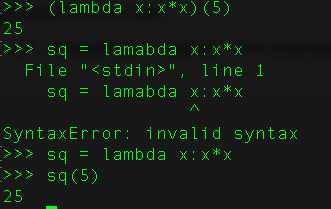
15、解释拉姆达表达式,什么时候会用到它?
如果我们需要一个只有单一表达式的函数,我们可以匿名定义它。拉姆达表达式通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
16、 什么是递归?
在调用一个函数的过程中,直接或间接地调用了函数本身这个就叫递归。但为了避免出现死循环,必须要有一个结束条件,举个例子:
使用递归函数的斐波那契数列
def fab(n):
if n == 1:
return 1
else:
return fab(n-2) + fab(n-1)
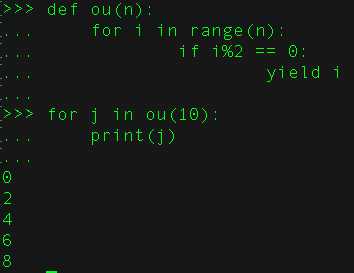
17、什么是生成器?
生成器会生成一系列的值用于迭代,这样看它又是一种可迭代对象。它是在for循环的过程中不断计算出下一个元素,并在适当的条件结束for循环。
1>使用yield来创建迭代器。
例子:求整数n中的所有偶数。
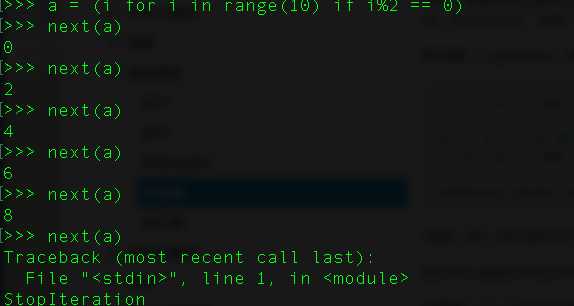
2、使用()来创建
18、什么是迭代器?
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。我们使用iter()函数创建迭代器。
list、dict、str等数据类型是可迭代对象,并不是迭代器。可以用方法isinstance()来进行判断
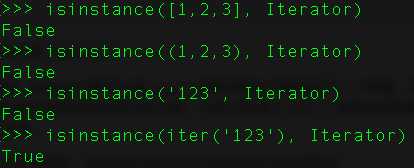
为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
19、请说说生成器和迭代器之间的区别?
生成器是迭代器的一种。
生成器是用函数中yield语句来创建的。迭代器的创建首先跟函数无关,可以用iter([1,2])来创建。
迭代器更能节约内存,并且它的计算是惰性的,只有在需要返回下一个数据时它才会计算。
生成器中有多少‘yield’语句,你可以自定义。
20、谈谈Python的不足之处。
1>运行速度,有速度要求的话,用C++改写关键部分吧。不过对于用户而言,机器上运行速度是可以忽略的。因为用户根本感觉不出来这种速度的差异。
2>python的开源性是的Python语言不能加密,但是目前国内市场纯粹靠编写软件卖给客户的越来越少,网站和移动应用不需要给客户源代码,所以这个问题就是问题了。国随着时间的推移,很多国内软件公司,尤其是游戏公司,也开始规模使用他。
3>构架选择太多(没有像C#这样的官方.net构架,也没有像ruby由于历史较短,构架开发的相对集中。Ruby on Rails 构架开发中小型web程序天下无敌)。不过这也从另一个侧面说明,python比较优秀,吸引的人才多,项目也多。
21、 函数zip()的是干嘛的?
zip()可以返回元组的迭代器。用next方法,或者for循环进行遍历。当然也可以使用list,将它转换为列表。但是转化计算只能进行一次,需要保存至变量中。
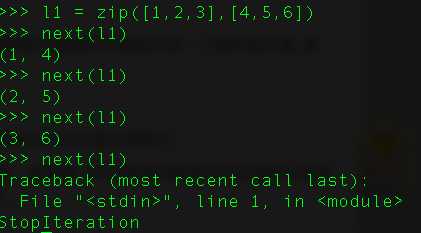
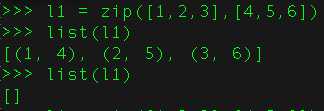
22、如果你困在了死循环里,怎么打破它?
control + c
23、解释Python的参数传递机制
python不允许程序员选择采用传值还是传引用。Python参数传递采用的肯定是“传引用”的方式。这种方式相当于传值和传引用的一种综合。如果函数收到的是一个可变对象(比如字典或者列表)的引用,就能修改对象的原始值--相当于通过“传引用”来传递对象。如果函数收到的是一个不可变对象(比如数字、字符或者元组)的引用,就不能直接修改原始对象--相当于通过“传值‘来传递对象,其实也是“传引用”,可以通过id()函数来查看发现属于同一个地址,只是它属于不可变的类型,看起来跟“传值”的用法一样。
可变的是用的引用传递,例如:lst和set等
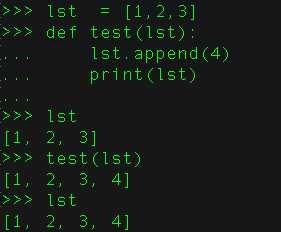
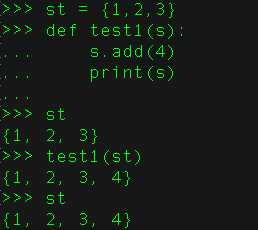
不可变的是用的传递,例如:tuple,int,str等。
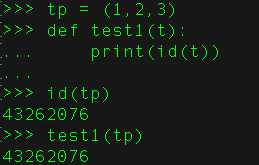
24、如何用Python找出你目前在哪个目录?
import os
os.getcwd()
用os.chdir()来修改当前目录。
25、 怎样发现字符串中与‘cake’押韵的第一个字?
import re
ke = re.search(".ake", "I hate the cake")
ke.group()
26、如何以相反顺序展示一个文件的内容?
使用函数reversed()
27、 什么是Tkinter ?
TKinter是一款很知名的Python库,用它我们可以制作图形用户界面。其支持不同的GUI工具和窗口构件,比如按钮、标签、文本框等等。这些工具和构件均有不同的属性,比如维度、颜色、字体等。
我们也能导入Tkinter模块。
import Tkinter
28、请谈谈.pyc文件和.py文件的不同之处
虽然这两种文件均保存字节代码,但.pyc文件是Python文件的编译版本,它有平台无关的字节代码,因此我们可以在任何支持.pyc格式文件的平台上执行它。Python会自动生成它以优化性能(加载时间,而非运行速度)。
python把原始程序代码放在.py文件里,而在执行.py文件的时候,将.py形式的程序编译成中间式文件(byte-compiled)的.pyc文件,这么做的目的就是为了加快下次执行文件的速度。
所以,在我们运行python文件的时候,就会自动首先查看是否具有.pyc文件,如果有的话,而且.py文件的修改时间和.pyc的修改时间一样,就会读取.pyc文件,否则,Python就会读原来的.py文件。
其实并不是所有的.py文件在与运行的时候都会差生.pyc文件,只有在import相应的.py文件的时候,才会生成相应的.pyc文件
29、 如何在Python中创建自己的包?
Python中创建包是比较方便的,只需要在当前目录建立一个文件夹,文件夹中包含一个__init__.py文件和若干个模块文件,其中__init__.py可以是一个空文件,但还是建议将包中所有需要导出的变量放到__all__中,这样可以确保包的接口清晰明了,易于使用。注意:在__init__.py中是无法使用模糊引用的。
30、如何计算一个字符串的长度?
len()
31、类继承
有如下的一段代码:

如何调用类 A 的 show 方法?
obj.__class__ = A
obj.show()
__class__ 方法指向了类对象,只用给他赋值类型 A ,然后调用方法 show ,但是用完了记得修改回来。
32、方法对象
问题:为了让下面这段代码运行,需要增加哪些代码?

使用模式方法__call__
def __call__(self, num):
print(num)
33、new 和 init
问题:下面这段代码输入什么?

34、Python list 和 dict 生成
问题:下面这段代码输出什么?



35、全局和局部变量
问题:下面这段代码输出什么?

答案:
9
9
num 不是个全局变量,所以每个函数都得到了自己的 num 拷贝,如果你想修改 num ,则必须用 global 关键字声明。比如下面这样
def f1():
global num
num = 20
这样的话结果就是
9
20
36、交换两个变量的值
问题:一行代码交换两个变量值

答案:a,b = b,a
它类似于
tup = (a,b)
a = tup[1]
b = tup[0]
只不过a,b = b,a这种形式可以省略一个变量的内存。
37、默认方法
问题:如下的代码


问题:写一个函数,接收整数参数 n ,返回一个函数,函数的功能是把函数的参数和 n 相乘并把结果返回。
def f1(n)
def f2(m):
return n * m
return f2
39、性能
问题:解析下面的代码慢在哪

44、python中match()和search()的区别?
match()函数只检测字符串开头位置是否匹配,匹配成功才会返回结果,否则返回None
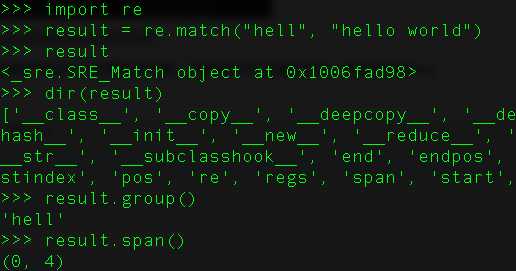
search()函数会在整个字符串内查找模式匹配,直到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
45、一个函数接收文件夹的名称作为参数,返回该文件中所有文件的全路径,请补全缺失的代码。
def print_directry_contents(spath):
import os
files_list = os.listdir(spath)
for file in files_list:
print(os.path.realpath(file))
46、阅读下面的代码,写出A0,A1至An的最终值
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。
功能:1.引入日志;2.函数执行时间统计;3.执行函数前预备处理;4.执行函数后清理功能;5.权限校验;6.缓存
51、你对多线程和多进程的理解。
1>进程是系统进行资源分配和调度的一个独立单位,线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源;
2>一个程序至少有一个进程,一个进程至少有一个线程;
3>线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高;
4>进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率 ;
5>线线程不能够独立执行,必须依存在进程中
6>优缺点:线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
52、线程中start方法和run方法的区别?
若调用start,则先执行主进程,后执行子进程;
若调用run,相当于正常的函数调用,将按照程序的顺序执行
53、python中如何拷贝一个对象?(赋值,浅拷贝,深拷贝的区别)
答:赋值(=),就是创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。
浅拷贝:创建一个新的对象,但它包含的是对原始对象中包含项的引用(如果用引用的方式修改其中一个对象,另外一个也会修改改变){1,完全切片方法;2,工厂函数,如list();3,copy模块的copy()函数}
深拷贝:创建一个新的对象,并且递归的复制它所包含的对象(修改其中一个,另外一个不会改变){copy模块的deep.deepcopy()函数}
54、介绍一下except的用法和作用?
捕获try except中间代码发生的异常,如果发生异常执行except的代码,不管是否发生异常都执行finally中的代码
except可以有0个或多个,如果有多个从上到下依次根据异常类型匹配,匹配某个Exception这执行对应的except中代码
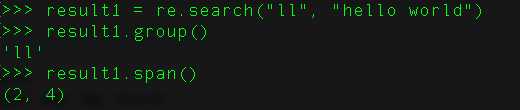
55、用python匹配HTML tag的时候,<.*>和<.*?>有什么区别?
贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。
费贪婪匹配:就是匹配到结果就好,就少的匹配字符。
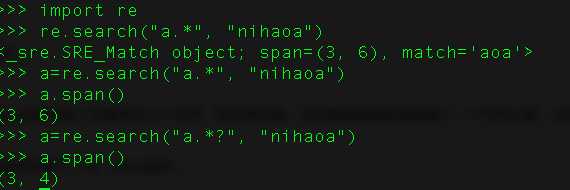
默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。
56、python是怎么进行内存管理的?
引用计数:python使用引用计数来保持追踪内存中的对象。Python内部记录了对象有多少个引用,即引用计数,当对象被创建时就创建了一个引用计数,当对象不再需要时,这个对象的引用计数为0时,它被垃圾回收。
使用sys.getrefcount(obj) - 1来查看引用计数。因为在使用的时候还引用了一次,所以减去1。
1>引用计数加1的情况:
对象被创建:x = 4
对象被引用:y=x
对象被作为参数,传入到一个函数中,例如func(a)
对象作为一个元素,存储在容器中,例如list1=[a,a]
2>导致引用计数-1的情况
对象的别名被显式销毁,例如del a
对象的别名被赋予新的对象,例如a=24
一个对象离开它的作用域,例如f函数执行完毕时,func函数中的局部变量(全局变量不会)
对象所在的容器被销毁,或从容器中删除对象
垃圾回收
1>当内存中有不再使用的部分时,垃圾收集器就会把他们清理掉。它会去检查那些引用计数为0的对象,然后清除其在内存的空间。当然除了引用计数为0的会被清除,还有一种情况也会被垃圾收集器清掉:当两个对象相互引用时,他们本身其他的引用已经为0了。
2>垃圾回收机制还有一个循环垃圾回收器, 确保释放循环引用对象(a引用b, b引用a, 导致其引用计数永远不为0)。
内存池机制
在Python中,许多时候申请的内存都是小块的内存,这些小块内存在申请后,很快又会被释放,由于这些内存的申请并不是为了创建对象,所以并没有对象一级的内存池机制。这就意味着Python在运行期间会大量地执行malloc和free的操作,频繁地在用户态和核心态之间进行切换,这将严重影响Python的执行效率。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
1>Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
2>Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的 malloc。另外Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
57、有一个纯字符串,编写一段代码,列出其所有字符的大小写组合。
total_str = 2**len(a) #总共有多少总情况。
max_byte_len = len(bin(total_str - 1)) - 2
for i in range(total_str):
by = bin(i)[2:] #转换成二进制字符串表示
by = by.zfill(max_byte_len) #对字符串前面进行补0
s = ‘‘
for j in range(len(by)):
if by[j] == "0":
s+=a[j].lower()
else:
s+=a[j].upper()
print(s)
58、简述一下你熟悉的NOSQL,它有什么优点和缺点?
59、使用一个正则表达式设计一个程序,将字符串"<a href=www.baidu.com>正则表达式题库</a><a href=www.cdtest.cn></a>"的www.baidu.com和www.cdtest.cn同时匹配出来。

60、设计一个程序,求出1+3!+5!+7!+9!+50!的和。
def factorial(n):
result = 1
for i in range(1, n+1):
result *= i
return result
print(1+factorial(3)+ factorial(5)+ factorial(7)+ factorial(9) + factorial(50))
61、把字符串“HELLO PYTHON”从大写字母全部转换成小写字母并换行显示,然后输出到计算机c盘的hello.txt文件中保存。
s = ‘HELLO PYTHON‘
f = open("/Users/walle/desktop/hello.txt", "w")
f.write(s.lower()+‘\n‘)
f.close()
62、设计一个小程序,采用任意数据结构方法,输入年、月、日后能判定当前日期在本年是第几天。
months = (
[0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31],
[0, 31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31],
)
def get_days(year,month,day):
run_year = 0
if (year%4 ==0 and year%100 !=0) or (year%400 == 0):
run_year = 1
for i in range(1, month):
day += months[run_year][i]
return day
print(get_days(2019,3,11))
63、给定一个值为整数的数组int_array,找出int_array中第二大的整数。
说明:如果最大的整数在int_array中出现不止一次,则最大整数为第二大整数。
例:
输入:[1,2,3,4,5]
输出:4
输入:[5,5,4,4,3]
输出:5
答案:
int_array.sort()
in_array[-2]
或者用两个变量,一个保存最大的数,一个保存第二大的数。
64、使用python将字符串“1.2.3.4.5”转换为字符串“5|4|3|2|1”
s = "1.2.3.4.5"
s1 = ""
for i in range(len(s)-1, -1, -1):
if s[i] == ‘.‘:
s1+= "|"
else:
s1 += s[i]
65、使用python编写一个装饰器,打印被装饰函数的输入与输出。
def printl(f):
def wrap(*arg,**ka):
print(arg,ka)
result = f(*arg,**ka)
print(result)
return result
return wrap
66、阐述range和xrange的区别,并且用Python仿写xrange函数。
Python3 range() 函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表。
Python3 list() 函数是对象迭代器,可以把range()返回的可迭代对象转为一个列表,返回的变量类型为列表。
Python2 range() 函数返回的是列表。
Iterator返回。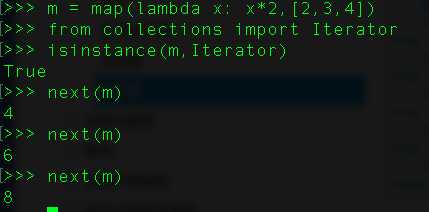
filter(function, iterable) # 将 function依次作用于iterable的每个元素,如果返回值为true, 保留元素,否则从Iterator里面删除
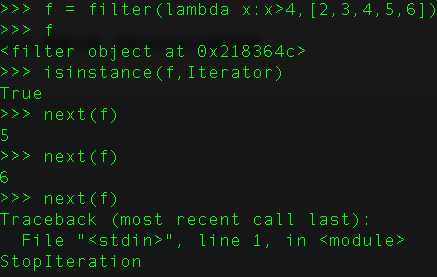
77、写一段代码实现单例模式。
class Sing:
def __new__(cls, *arg, **kwarg):
if not hasattr(Sing, "_instance"):
cls._instance = super(Sing, cls).__new__(cls, *args, **kwargs)
return cls._instance
s1= Sing()
s2 = Sing()
print(s1 is s2)
78、@classmethod、@staticmethod、@property都是啥意思?
@classmethod:类方法,类方法是给类用的,类在使用时会将类本身当做参数传给类方法的第一个参数,python为我们内置了函数classmethod来把类中的函数定义成类方法。
cookie保存在浏览器端,session保存在服务器端,但是为了区分不同的客户端,服务器会在浏览器中发送一个对应的sessionid保存到cookies中,下次浏览器请求服务器的时候会将sessionid一并发送给服务器。所以session机制依赖于cookie机制。
csrf的攻击和防范方法
下图简单阐述了CSRF攻击的思想:
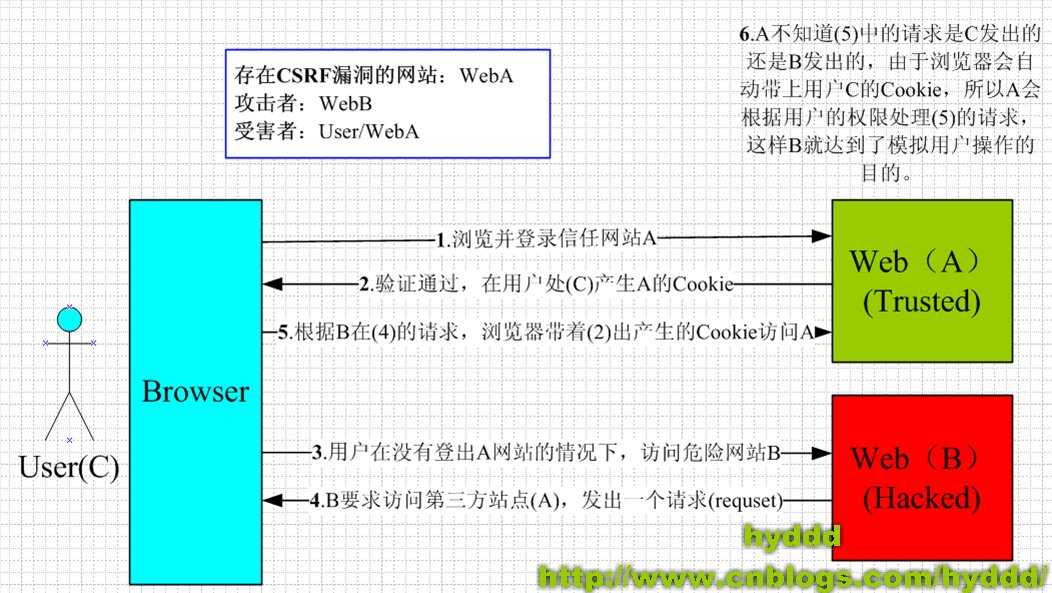
从上图可以看出,要完成一次CSRF攻击,受害者必须依次完成两个步骤:
1.登录受信任网站A,并在本地生成Cookie。
2.在不登出A的情况下,访问危险网站B。
看到这里,你也许会说:“如果我不满足以上两个条件中的一个,我就不会受到CSRF的攻击”。是的,确实如此,但你不能保证以下情况不会发生:
1.你不能保证你登录了一个网站后,不再打开一个tab页面并访问另外的网站。
2.你不能保证你关闭浏览器了后,你本地的Cookie立刻过期,你上次的会话已经结束。(事实上,关闭浏览器不能结束一个会话,但大多数人都会错误的认为关闭浏览器就等于退出登录/结束会话了......)
3.上图中所谓的攻击网站,可能是一个存在其他漏洞的可信任的经常被人访问的网站。
防范:
1.服务端进行CSRF防御
服务端的CSRF方式方法很多样,但总的思想都是一致的,就是在客户端页面增加伪随机数。
(1).Cookie Hashing(所有表单都包含同一个伪随机值):
(2).验证码
(3).One-Time Tokens(不同的表单包含一个不同的伪随机值)
80、在判断object是否是class的instances时,type和isinstance函数的区别?
type(obj) => <type ‘instance‘>
type(cls) => <type ‘classobj‘>
由上可知,所有obj type后统一为 instance type; 而cls type后统一为classobj type
isinstance(obj,class),如果object是class的instance,返回True。
81、通过重写内置函数,实现文件open之前查找文件格式?
def open(filename, mode):
import __builtin__
file = __builtin__ .open(filename, mode)
if file.read(5) not in (‘‘GIF87", "GIF89")
raise TypeError("not a gif file")
file.seek(0)
return file
82、重新实现str.strip(),注意不能使用string.*strip()
def strip(s, p = ‘ ‘):
sindex, eindex = 0, 0
for i in range(len(s)):
if s[i] != p:
sindex = i
break
for j in range(len(s)-1, -1, -1):
if s[j] != p:
eindex = j
break
return s[sindex:eindex+1]
print(strip("000abd000", "0"))
83、deepcopy 和 copy的区别
copy 仅拷贝对象本身,而不拷贝对象中引用的其它对象。
deepcopy 除拷贝对象本身,而且拷贝对象中引用的其它对象。
84、同步与异步
同步和异步关注的是消息通信机制
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。
换句话说,就是由调用者主动等待这个调用的结果。
而异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
85、python适合的场景有哪些?当遇到计算密集型任务怎么办?
适用场景:网站运维,金融分析,服务器编写,爬虫
当遇到io密集型任务时,涉及到的大多是网络,磁盘等任务,这一类任务的特性是cpu小号低,使用多线程.
计算密集型的任务主要是消耗cpu性能,谁要运用多进程,当然运用python语言的运行效率很低,所以一般对于计算密集型任务,可以使用c语言编写。
86、在python中,如何交换两个变量的值?
a,b = b, a
87、字符串的拼接–如何高效的拼接两个字符串?
尽量不要使用+。因为字符串是不变的数据类型。使用+会生成大量的对象,占用很多内存。
应该使用join()方法或者format()方法。
88、list = ["a","a","a",1,2,3,4,5,"A","B","C"]提取出”12345”
a,b,c,*n,e,f,d = ["a","a","a",1,2,3,4,5,"A","B","C"]
89、多线程?
多线程可以共享进程的内存空间,因此要实现多个线程之间的通信相对简单,比如设置一个全局变量,多个线程共享这个全局变量。但是当多个线程共享一个资源的时候,可能导致程序失效甚至崩溃,如果一个资源被多个线程竞争使用,那么对临界资源的访问需要加上保护,否则会处于“混乱”状态。
这种情况下,锁就可以得到用处了。多线程并不能发挥cpu多核特性,因为python解释器有一个gil锁,任何线程执行前必须获得GIL锁,然后每执行100条字节码,解释器就会自动释放GIL锁让别的线程有机会执行。
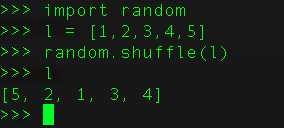
90、给定一串排好序的列表,打乱这个函数?
91、给定一串字典(或列表),找出指定的(前N个)最大值?最小值?
def get_n(lst, n):
max_n = lst[0]
min_n = lst[0]
for i in range(n):
if lst[i] > max_n:
max_n = lst[i]
if lst[i] < min_n:
min_n = lst[i]
return max_n,min_n
print(get_n([1,4,94,43,232,4,5,34,6,7,30,5], 5))
92、一个汽水是$1, 两个汽水的空瓶换一瓶可乐, 请问给一些钱, 最多能喝几瓶呢?
def get_soda_num(money):
soda_num= money #总共喝的汽水数,初始值为钱/1。也就是money
n = soda_num #总共的瓶子数。初始值等于汽水数。
while n//2 > 0:
soda_num += n//2
n = n//2 + n%2
return soda_num
print(get_soda_num(10))
93、给定一个升序排列的自然数数组, eg. [1, 3, 3, 5, 7, 7, 7, 7, 8, 14, 14],任意自然数, eg. 7
output:
数组内 值为7区域的左右边界index: [1, 3, 3, 5, 7, 7, 7, 7, 8, 14, 14]
这个例子中就是(4, 7)
def get_index(lst, n):
low, high =0, len(lst)
midindex = None
while low < high:
mid = low + (high-low) //2
if lst[mid] == n:
midindex = mid
if lst[mid] < n:
low = mid+1
else:
high = mid -1
if midindex:
lowindex = midindex
while lst[lowindex] == n:
lowindex -= 1
highindex = midindex
while lst[highindex] == n:
highindex += 1
return (lowindex+1, highindex-1)
return -1
print(get_index([1, 3, 3, 5, 7, 7, 7, 7, 8, 14, 14],7))
93、斐波那契非递归实现
def fab(n):
a, b = 0, 1
for i in range(n):
a, b = b, a+b
return b
94、N个数依次入栈,出栈顺序有多少种?
95、简述with方法打开处理文件帮我我们做了什么?
打开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的f.open写法,我们需要try,except,finally,做异常判断,并且文件最终不管遇到什么情况,都要执行finally f.close()关闭文件,with方法帮我们实现了finally中f.close
96、列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]
[i for i in map(lambda x:x**2, [1,2,3,4,5]) if i > 10]
97、re.compile作用
将正则表达式编译成一个对象。加快速度,并重复使用。
98、简述any()和all()方法
any():只要迭代器中有一个元素为真就为真
all():迭代器中所有的判断项返回都是真,结果才为真
99、简述乐观锁和悲观锁
悲观锁, 就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制,乐观锁适用于多读的应用类型,这样可以提高吞吐量。
标签:font sort 垃圾收集 pat 最大 12px tin 包括 any
原文地址:https://www.cnblogs.com/walle-zhao/p/10486539.html