标签:返回 std reload tde unicode py3 rac image sci
看了以下两篇博文的基础上,感觉自己明白了点。记录下。
http://www.cnblogs.com/yuanchenqi/articles/5938733.html
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
python2的编解码的几个问题:
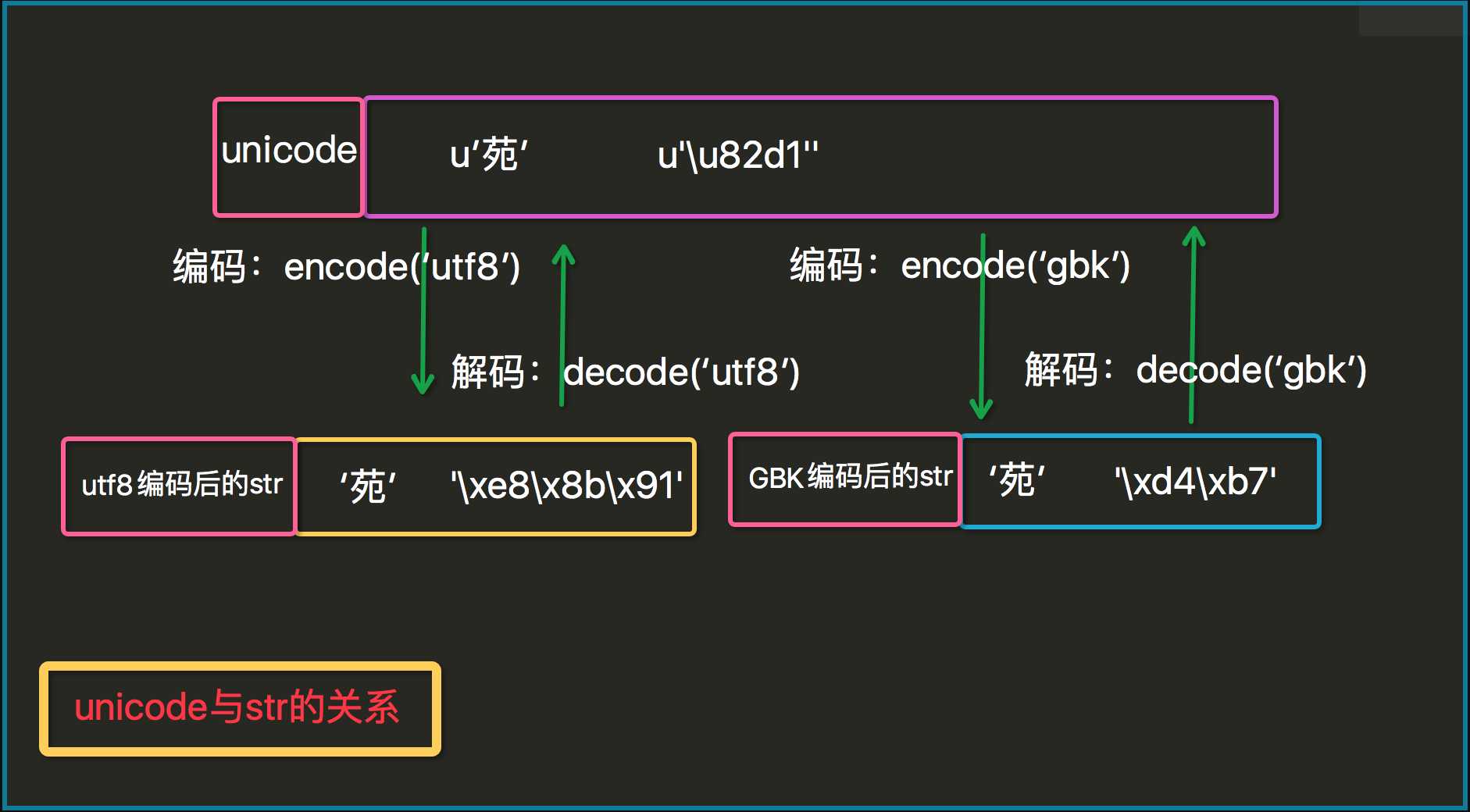
(1)两种数据类型unicode 和 str。
unicode-->str 的过程是编码,可以用encode(‘utf8‘)这种方式表示,也可以用str()把unicode变成str类型,
另外,str-->unicode 是解码过程,unicode(str),或者str.decode(‘utf8‘) 都可以。
但是python2中系统默认的编码是ASCII码,即使你在编辑.py 文件里声明了coding是utf8,那么在执行str(u‘\uXXXX’) 或者 unicode()时,默认还是使用ASCII码进行编解码。
除非使用代码改变system的default encoding。
如果变量是英文的,相应的编解码test如下:

import sys print(sys.getdefaultencoding()) # 定义a1是英文 str类型 a1 = "hello world" print "-----a1--------" print a1 print type(a1) print repr(a1) # str(str类型)直接返回str类型 print "-----b1--------" b1 = str(a1) print b1 print type(b1) print repr(b1) #unicode(str类型)返回通过ASCII解码方式成unicode print "-----c1--------" c1 = unicode(a1) print c1 print type(c1) print repr(c1) #用decode方式,把str解码成unicode,对应c1 print "-----d1--------" d1 = a1.decode(‘utf8‘) print d1 print type(d1) print repr(d1) # 定义a2是英文 unicode类型 print "-----a2--------" a2 = u‘hello world‘ print a2 print type(a2) print repr(a2) # str(unicode类型)相当于用默认的ASCII码编码成str print "-----b2--------" b2 = str(a2) print b2 print type(b2) print repr(b2) #unicode unicode类型)不变 print "-----c2--------" c2 = unicode(a2) print c2 print type(c2) print repr(c2) # 用encode编码,对应b2部分 print "-----d2--------" d2 = a2.encode(‘utf8‘) print d2 print type(d2) print repr(d2) 运行结果: ascii -----a1-------- hello world <type ‘str‘> ‘hello world‘ -----b1-------- hello world <type ‘str‘> ‘hello world‘ -----c1-------- hello world <type ‘unicode‘> u‘hello world‘ -----d1-------- hello world <type ‘unicode‘> u‘hello world‘ -----a2-------- hello world <type ‘unicode‘> u‘hello world‘ -----b2-------- hello world <type ‘str‘> ‘hello world‘ -----c2-------- hello world <type ‘unicode‘> u‘hello world‘ -----d2-------- hello world <type ‘str‘> ‘hello world‘
相对应的,如果变量是中文的,那么相应的编解码结果如下:
# -*- coding:utf-8 -*- import sys print(sys.getdefaultencoding()) # 定义a1是英文 str类型 a1 = "I am 熊猫" print "-----a1--------" print a1 print type(a1) print repr(a1) # str(str类型)直接返回str类型 print "-----b1--------" b1 = str(a1) print b1 print type(b1) print repr(b1) # #unicode(str类型)返回通过ASCII解码方式成unicode # print "-----c1--------" # c1 = unicode(a1) #运行结果:UnicodeDecodeError: ‘ascii‘ codec can‘t decode byte 0xe7 in position 5: ordinal not in range(128) # print c1 # print type(c1) # print repr(c1) #用decode方式,把str解码成unicode,对应c1 print "-----d1--------" d1 = a1.decode(‘utf8‘) print d1 print type(d1) print repr(d1) # 定义a2是英文 unicode类型 print "-----a2--------" a2 = u‘I am 熊猫‘ print a2 print type(a2) print repr(a2) # # str(unicode类型)相当于用默认的ASCII码编码成str # print "-----b2--------" # b2 = str(a2) #运行结果:UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 5-6: ordinal not in range(128) # print b2 # print type(b2) # print repr(b2) #unicode unicode类型)不变 print "-----c2--------" c2 = unicode(a2) print c2 print type(c2) print repr(c2) # 用encode编码,对应b2部分 print "-----d2--------" d2 = a2.encode(‘utf8‘) print d2 print type(d2) print repr(d2) 运行结果: ascii -----a1-------- I am 熊猫 <type ‘str‘> ‘I am \xe7\x86\x8a\xe7\x8c\xab‘ -----b1-------- I am 熊猫 <type ‘str‘> ‘I am \xe7\x86\x8a\xe7\x8c\xab‘ -----d1-------- I am 熊猫 <type ‘unicode‘> u‘I am \u718a\u732b‘ -----a2-------- I am 熊猫 <type ‘unicode‘> u‘I am \u718a\u732b‘ -----c2-------- I am 熊猫 <type ‘unicode‘> u‘I am \u718a\u732b‘ -----d2-------- I am 熊猫 <type ‘str‘> ‘I am \xe7\x86\x8a\xe7\x8c\xab‘
对于带有中文的部分,如果修改相应的系统默认编码,那么使用str或者unicode也不会出错:
# -*- coding:utf-8 -*- import sys print(sys.getdefaultencoding()) reload(sys) sys.setdefaultencoding(‘utf8‘) print(sys.getdefaultencoding()) # 定义a1是英文 str类型 a1 = "I am 熊猫" print "-----a1--------" print a1 print type(a1) print repr(a1) # str(str类型)直接返回str类型 print "-----b1--------" b1 = str(a1) print b1 print type(b1) print repr(b1) #unicode(str类型)返回通过ASCII解码方式成unicode print "-----c1--------" c1 = unicode(a1) print c1 print type(c1) print repr(c1) #用decode方式,把str解码成unicode,对应c1 print "-----d1--------" d1 = a1.decode(‘utf8‘) print d1 print type(d1) print repr(d1) # 定义a2是英文 unicode类型 print "-----a2--------" a2 = u‘I am 熊猫‘ print a2 print type(a2) print repr(a2) # str(unicode类型)相当于用默认的ASCII码编码成str print "-----b2--------" b2 = str(a2) print b2 print type(b2) print repr(b2) #unicode unicode类型)不变 print "-----c2--------" c2 = unicode(a2) print c2 print type(c2) print repr(c2) # 用encode编码,对应b2部分 print "-----d2--------" d2 = a2.encode(‘utf8‘) print d2 print type(d2) print repr(d2) 运行结果: ascii utf8 -----a1-------- I am 熊猫 <type ‘str‘> ‘I am \xe7\x86\x8a\xe7\x8c\xab‘ -----b1-------- I am 熊猫 <type ‘str‘> ‘I am \xe7\x86\x8a\xe7\x8c\xab‘ -----c1-------- I am 熊猫 <type ‘unicode‘> u‘I am \u718a\u732b‘ -----d1-------- I am 熊猫 <type ‘unicode‘> u‘I am \u718a\u732b‘ -----a2-------- I am 熊猫 <type ‘unicode‘> u‘I am \u718a\u732b‘ -----b2-------- I am 熊猫 <type ‘str‘> ‘I am \xe7\x86\x8a\xe7\x8c\xab‘ -----c2-------- I am 熊猫 <type ‘unicode‘> u‘I am \u718a\u732b‘ -----d2-------- I am 熊猫 <type ‘str‘> ‘I am \xe7\x86\x8a\xe7\x8c\xab‘
(2)python2,当unicode和str 相连时,默认的,Python2会按照默认编码,把str先变成unicode进行相连。
(4)无论py2,还是py3,与明文直接对应的就是unicode数据,打印unicode数据就会显示相应的明文(包括英文和中文)
(5)当使用print时,print A 相当于 sys.stdout.write(str(A))
(6)在windows cmd窗口的中文乱码问题。
(7)open文件时的中文乱码问题
(8)print list和dict时中文乱码问题
标签:返回 std reload tde unicode py3 rac image sci
原文地址:https://www.cnblogs.com/zhangqiella/p/10524760.html
