标签:补充 com 一个 位置 构造 区别 编译器 不同 源码剖析
引言: 在c++中司空见惯的事情就是:可以通过指针和引用可以实现多态,而对象不可以。 那为什么?让我们来解开这神秘的暗纱!
在一个类的实例中,只会存放非静态的成员变量。 如果该类中存在虚函数的话,再多加一个指向虚函数列表指针—vptr。
例如声明如下两个类,并分别实例化两个对象,它们的内存分配大致如下:(vptr具体在什么位置,与编译器有关,大多数都在开始处)
class base { public: virtual ~base() {}; virtual string GetName() { return "base"; } GetA(); int a; }; class derived : public base { public: virtual ~derived() {}; virtual string GetName() { return "derived";} GetB(); int b; };
base B1, B2;
derived D1, D2;
内存分布大致如下:
1. 类对象中,只有成员变量与vptr.
2. 普通成员函数在内存的某一位置放着。它们与c语言中定义的普通函数没有区别。 当我们通过对象或对象指针调用普通成员函数时, 编译器会拿到它。怎么拿到呢?当然是通过名字了,编译器都会对我们写的函数的名字进行修饰映射,让它们变成内存中唯一的函数名。
3. 无论基类还是子类,每一种类类型的虚函数表只有一份,它里面存放了基类的类型信息和指向基类中的虚函数的指针。 某一类类型的所有对象都指向了相同的虚函数表。
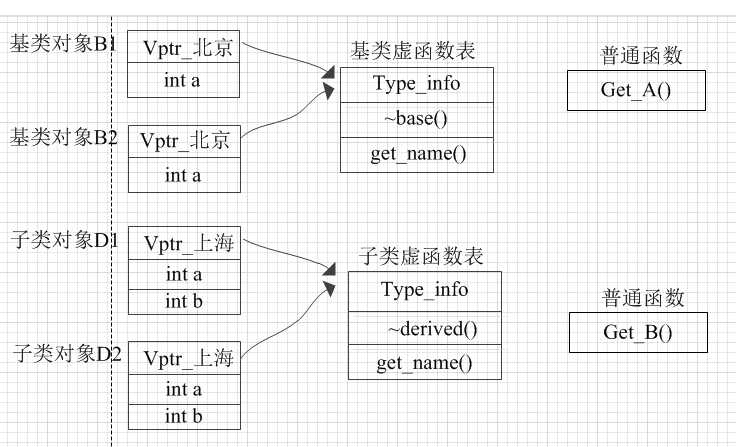
例如:下面的 base类型的对象B1或指针pB1,只能使用GetName() 和GetA()方法。 无论它们是如何来的!!!!!
// 直接构造得到 base B1; base* pB1 = new base(); // 即使从子类转换而来, 通过B1或pB1也永远访问不到GetB()方法。 derived d1; B1 = d1; pB1 = new derived();
本质上它们没有任何区别,在32/64位系统中都是4/8字节的一个变量。 唯一不同的就是编译器解释它们的方式,即通过指针来寻址出来的对象类型不同,大小不同 ,指针类型来告诉编译器如何解释该指针。
有代码如下 :
derived* _pD = new derived(); base* _pB = _pD; _pB.GetName(); // 返回 derived.
想要知道如何通过指针来实现的多态,就要看看对基类指针赋值是发生了什么! 具体来说 如下图所示:
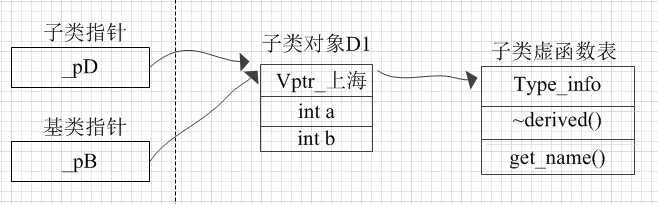
我们会发现,对指针的赋值,仅仅是让基类指针_pB指向的子类对象的地地址。 当我们使用基类指针调用GetName()函数(该函数是虚函数,它的地址在函数表中)时, 会由_pB指向的地址找到子类的虚函数表指针vptr_上海,再由vptr_上海在虚函数表中找到子类的GetName(),从而调用它。就这样实现了多态。
有代码如下:
base B1; derived D1; B1 = D1; B1.GetName(); // 返回 base base B2 = D1 B2.GetName(); // 返回 base
上面代码中无论赋值操作还是赋值构造时, 只会处理成员变量,一个类对象里面的vptr永远不会变,永远都会指向所属类型的虚函数表,操作如下图所示:
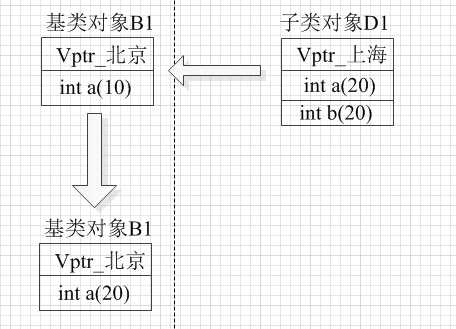
因此,通过对象调用虚函数时,就没有必要进行动态解析了,白白增加了间接性,浪费性能。编译器直接在编译时就可以确认具体调用哪一个函数了,因此没有所谓的多态。
补充说明:
1. 引用本质上也是通过指针来实现的,可以<<参考std源码剖析》一本书,所以引用也可以实现多态。
2. 即使通过 基类的指针调用基类的虚函数 或 通过子类的指针调用子类的虚函数 以及通过子类指针调用基类的虚函数, 也是通过多态机制来完成的(即一步步的间接性来完成)。
3. 一个空的class的对象的大小为1个字节, 编译器之所以要这么做,是为了区别同一个类类型的不同对象!
标签:补充 com 一个 位置 构造 区别 编译器 不同 源码剖析
原文地址:https://www.cnblogs.com/yinheyi/p/10525543.html