标签:group by not 顺序 开始 order 交集 函数 ade 数据源
SELECT语句执行顺序
SELECT语句中子句的执行顺序与SELECT语句中子句的输入顺序是不一样的,所以并不是从SELECT子句开始执行的,而是按照下面的顺序执行:
开始->FROM子句->WHERE子句->GROUP BY子句->HAVING子句->ORDER BY子句->SELECT子句->LIMIT子句->最终结果
每个子句执行后都会产生一个中间结果,供接下来的子句使用,如果不存在某个子句,就跳过
对比了一下,mysql和sql执行顺序基本是一样的, 标准顺序的 SQL 语句为:
select 考生姓名, max(总成绩) as max总成绩 from tb_Grade where 考生姓名 is not null group by 考生姓名 having max(总成绩) > 600 order by max总成绩
在上面的示例中 SQL 语句的执行顺序如下:
(1). 首先执行 FROM 子句, 从 tb_Grade 表组装数据源的数据
(2). 执行 WHERE 子句, 筛选 tb_Grade 表中所有数据不为 NULL 的数据
(3). 执行 GROUP BY 子句, 把 tb_Grade 表按 "学生姓名" 列进行分组(注:这一步开始才可以使用select中的别名,他返回的是一个游标,而不是一个表,所以在where中不可以使用select中的别名,而having却可以使用,感谢网友 zyt1369 提出这个问题)
(4). 计算 max() 聚集函数, 按 "总成绩" 求出总成绩中最大的一些数值
(5). 执行 HAVING 子句, 筛选课程的总成绩大于 600 分的.
(7). 执行 ORDER BY 子句, 把最后的结果按 "Max 成绩" 进行排序.
SQL JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
最常见的 JOIN 类型:SQL INNER JOIN(简单的 JOIN)、SQL LEFT JOIN、SQL RIGHT JOIN、SQL FULL JOIN,其中前一种是内连接,后三种是外链接。
假设我们有两张表,Table A是左边的表,Table B是右边的表。
| id | name |
| 1 | |
| 2 | 淘宝 |
| 3 | 微博 |
| 4 |
| id | address |
| 1 | 美国 |
| 5 | 中国 |
| 3 | 中国 |
| 6 | 美国 |
INNER JOIN
内连接是最常见的一种连接,只连接匹配的行。
inner join语法
select column_name(s) from table 1 INNER JOIN table 2 ON table 1.column_name=table 2.column_name
注释:INNER JOIN与JOIN是相同
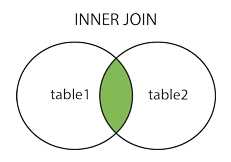
INNER JOIN产生的结果集中,是1和2的交集。
select * from Table A inner join Table B on Table A.id=Table B.id
执行以上SQL输出结果如下:
| id | name | address |
| 1 | 美国 | |
| 3 | 微博 | 中国 |
LEFT JOIN
LEFT JOIN返回左表的全部行和右表满足ON条件的行,如果左表的行在右表中没有匹配,那么这一行右表中对应数据用NULL代替。
LEFT JOIN 语法
select column_name(s) from table 1 LEFT JOIN table 2 ON table 1.column_name=table 2.column_name
注释:在某些数据库中,LEFT JOIN 称为LEFT OUTER JOIN
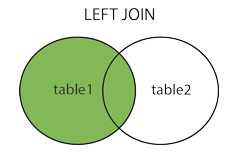
LEFT JOIN产生表1的完全集,而2表中匹配的则有值,没有匹配的则以null值取代。
select * from Table A left join Table B on Table A.id=Table B.id
执行以上SQL输出结果如下:
| id | name | address |
| 1 | 美国 | |
| 2 | 淘宝 | null |
| 3 | 微博 | 中国 |
| 4 | null |
RIGHT JOIN
RIGHT JOIN返回右表的全部行和左表满足ON条件的行,如果右表的行在左表中没有匹配,那么这一行左表中对应数据用NULL代替。
RIGHT JOIN语法
select column_name(s) from table 1 RIGHT JOIN table 2 ON table 1.column_name=table 2.column_name
注释:在某些数据库中,RIGHT JOIN 称为RIGHT OUTER JOIN
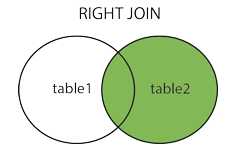
RIGHT JOIN产生表2的完全集,而1表中匹配的则有值,没有匹配的则以null值取代。
select * from Table A right join Table B on Table A.id=Table B.id
执行以上SQL输出结果如下:
| id | name | address |
| 1 | 美国 | |
| 5 | null | 中国 |
| 3 | 微博 | 中国 |
| 6 | null | 美国 |
FULL OUTER JOIN
FULL JOIN 会从左表 和右表 那里返回所有的行。如果其中一个表的数据行在另一个表中没有匹配的行,那么对面的数据用NULL代替
FULL OUTER JOIN语法
select column_name(s) from table 1 FULL OUTER JOIN table 2 ON table 1.column_name=table 2.column_name
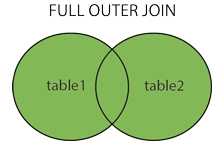
FULL OUTER JOIN产生1和2的并集。但是需要注意的是,对于没有匹配的记录,则会以null做为值。
select * from Table A full outer join Table B on Table A.id=Table B.id
执行以上SQL输出结果如下:
| id | name | address |
| 1 | 美国 | |
| 2 | 淘宝 | null |
| 3 | 微博 | 中国 |
| 4 | null | |
| 5 | null | 中国 |
| 6 | null | 美国 |
标签:group by not 顺序 开始 order 交集 函数 ade 数据源
原文地址:https://www.cnblogs.com/yszr/p/10527377.html