标签:distinct strong 集合 流式 div super list() vat 写法
java8新增一种流式数据,让操作集合数据更简单方便。
定义基本对象:
public class Peo { private String name; private String id; public Peo() { super(); } public Peo(String name, String id) { super(); this.name = name; this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getId() { return id; } public void setId(String id) { this.id = id; } }
1.toMap的使用
使用toMap方法将list集合转出对应的map
import java.util.ArrayList; import java.util.List; import java.util.Map; import java.util.stream.Collectors; public class Stemap { public static void main(String[] args) { List<Peo> list = new ArrayList<>(); list.add(new Peo("a", "1")); list.add(new Peo("b", "2")); list.add(new Peo("c", "3")); list.add(new Peo("d", "4")); Map<String, Peo> map = list.stream().collect(Collectors.toMap(Peo::getId, s -> s)); map.keySet().forEach(s->{ System.out.println(s); }); } }
使用
Collectors.toMap方法将list转成Map,key = Id,value = Peo对象
注意key值不能有重复,如果有重复就会报错,为了解决这种问题,我们可以使用以下的写法:
Map<String, Peo> map = list.stream().collect(Collectors.toMap(Peo::getId, s -> s,(s1,s2)->s1));
多加的一个方法(s1,s2)->s1,是指当遇到key值相同时,value使用已经添加的,忽略后面的对象,如果这么写(s1,s2)->s2,将会把后面的对象替换到map中,如下:
import java.util.ArrayList; import java.util.List; import java.util.Map; import java.util.stream.Collectors; public class Stemap { public static void main(String[] args) { List<Peo> list = new ArrayList<>(); list.add(new Peo("a", "1")); /* list.add(new Peo("b", "2")); list.add(new Peo("c", "3")); list.add(new Peo("d", "4"));*/ list.add(new Peo("e", "1")); Map<String, Peo> map1 = list.stream().collect(Collectors.toMap(Peo::getId, s -> s,(s1,s2)->s1)); System.out.println(map1.get("1").getName()); Map<String, Peo> map2 = list.stream().collect(Collectors.toMap(Peo::getId, s -> s,(s1,s2)->s2)); System.out.println(map2.get("1").getName()); /*map1.values().forEach(s->{ System.out.println(s); });*/ } }
输出如下:

2.groupBy
import java.util.ArrayList; import java.util.List; import java.util.Map; import java.util.stream.Collectors; public class Stemap { public static void main(String[] args) { List<Peo> list = new ArrayList<>(); list.add(new Peo("a", "1")); list.add(new Peo("b", "2")); list.add(new Peo("c", "3")); list.add(new Peo("d", "4")); list.add(new Peo("e", "1")); Map<String, List<Peo>> map1 = list.stream().collect(Collectors.groupingBy(Peo::getId)); System.out.println("map 数量:"+map1.size()); System.out.println("key = 1 数量:"+map1.get("1").size()); map1.get("1").forEach(p ->{ System.out.println(p.getName()); }); /*map1.values().forEach(s->{ System.out.println(s); });*/ } }
输出如下:
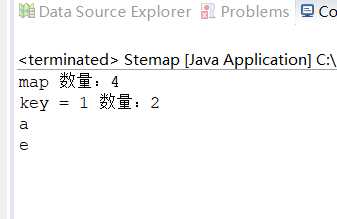
我们可以通过groupBy方法对list数据分组,指定分组的key。
3.filter
import java.util.ArrayList; import java.util.List; import java.util.stream.Collectors; public class Stemap { public static void main(String[] args) { List<Peo> list = new ArrayList<>(); list.add(new Peo("a", "1")); list.add(new Peo("b", "2")); list.add(new Peo("c", "3")); list.add(new Peo("d", "4")); list.add(new Peo("e", "1")); list = list.stream().filter(peo -> "1".equals(peo.getId())).collect(Collectors.toList());; list.forEach(p ->{ System.out.println(p.getName()); }); /*map1.values().forEach(s->{ System.out.println(s); });*/ } }
输出:
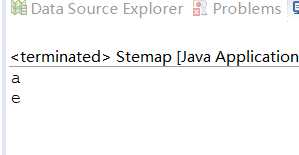
可用通过filter过滤出满足一定条件的数据。
后续还有关于distinct、limit、skip、allMatch等等方法,后面继续补充
标签:distinct strong 集合 流式 div super list() vat 写法
原文地址:https://www.cnblogs.com/wangzun/p/10529550.html