标签:tensor dma register amp manual gnu inter 转换 flat
本文是基于TensorRT 5.0.2基础上,关于其内部的uff_custom_plugin例子的分析和介绍。
本例子展示如何使用cpp基于tensorrt python绑定和UFF解析器进行编写plugin。该例子实现一个clip层(以CUDA kernel实现),然后封装成一个tensorrt plugin,然后生成一个动态共享库,用户可以动态的在python中链接该库,将该plugin注册到tensorrt的plugin registry中,并让UFF解析器能够使用。
该例子还是有些知识点未消化,后续接着研究研究。
假设当前路径为:
TensorRT-5.0.2.6/samples其对应当前例子文件目录树为:
# tree python
python
├── common.py
├── uff_custom_plugin
│?? ├── CMakeLists.txt
│?? ├── __init__.py
│?? ├── lenet5.py
│?? ├── mnist_uff_custom_plugin.py
│?? ├── plugin
│?? │?? ├── clipKernel.cu
│?? │?? ├── clipKernel.h
│?? │?? ├── customClipPlugin.cpp
│?? │?? └── customClipPlugin.h
│?? ├── README.md
│?? └── requirements.txt其中:
plugin包含Clip 层的plugin:
- clipKernel.cu 实现的cuda kernel;
- clipKernel.h 导出cuda kernel为cpp代码;
- customClipPlugin.cpp 实现clip tensorrt plugin,内部使用cuda kernel;
- customClipPlugin.h CliPlugin的头文件
- lenet5.py 使用ReLU6激活函数去训练MNIST;
mnist_uff_custom_plugin.py 将训练好的模型转换成UFF模型,并用tensorrt运行
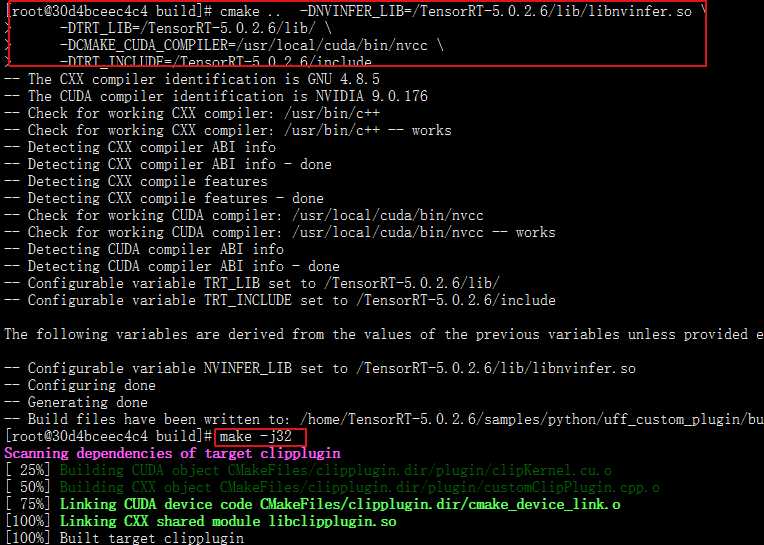
- 创建build文件夹,然后进入该文件夹
mkdir build && pushd build
- cmake生成对应Makefile,此处可以自由设定一些参数。如果其中有些依赖不在默认位置路径上,可以cmake手动指定,关于Cmake的文档,可参考
cmake .. -DNVINFER_LIB=/TensorRT-5.0.2.6/lib/libnvinfer.so -DTRT_LIB=/TensorRT-5.0.2.6/lib/ -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc -DTRT_INCLUDE=/TensorRT-5.0.2.6/include注意cmake打出的日志中的VARIABLE_NAME-NOTFOUND
- 进行编译
make -j32
- 跳出build
popd首先看看CMakeLists.txt。其中关于find_library, include_directories, add_subdirectory的可以参考cmake-command文档
# cmake 3.8 已经将CUDA 作为第一类语言了
cmake_minimum_required(VERSION 3.8 FATAL_ERROR)
project(ClipPlugin LANGUAGES CXX CUDA)
# 开启所有编译警告
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -Wno-long-long -pedantic -Werror")
# 设定一个宏set_ifndef,用于操作当变量未找到时的行为:此处将未找到变量var 设定为val
macro(set_ifndef var val)
if (NOT ${var})
set(${var} ${val})
endif()
message(STATUS "Configurable variable ${var} set to ${${var}}")
endmacro()
# -------- CONFIGURATION --------
set_ifndef(TRT_LIB /usr/lib/x86_64-linux-gnu)
set_ifndef(TRT_INCLUDE /usr/include/x86_64-linux-gnu)
# 寻找依赖:
message("\nThe following variables are derived from the values of the previous variables unless provided explicitly:\n")
# TensorRT's nvinfer lib
find_library(_NVINFER_LIB nvinfer HINTS ${TRT_LIB} PATH_SUFFIXES lib lib64)
set_ifndef(NVINFER_LIB ${_NVINFER_LIB})
# -------- BUILDING --------
# 将其他include文件夹增加到编译寻找路径中
include_directories(${CUDA_INC_DIR} ${TRT_INCLUDE} ${CMAKE_SOURCE_DIR}/plugin/)
# 从对应源码生成clipplugin library target
add_library(clipplugin MODULE
${CMAKE_SOURCE_DIR}/plugin/clipKernel.cu
${CMAKE_SOURCE_DIR}/plugin/customClipPlugin.cpp
${CMAKE_SOURCE_DIR}/plugin/clipKernel.h
${CMAKE_SOURCE_DIR}/plugin/customClipPlugin.h
)
target_compile_features(clipplugin PUBLIC cxx_std_11) # 指定使用C++11
# Link TensorRT's nvinfer lib
target_link_libraries(clipplugin PRIVATE ${NVINFER_LIB})
# We need to explicitly state that we need all CUDA files
# to be built with -dc as the member functions will be called by
# other libraries and executables (in our case, Python inference scripts)
set_target_properties(clipplugin PROPERTIES
CUDA_SEPARABLE_COMPILATION ON
)运行得:
import tensorflow as tf
import numpy as np
import os
MODEL_DIR = os.path.join(
os.path.dirname(os.path.realpath(__file__)),
'models'
)
def load_data():
# 导入mnist数据集
# 手动下载aria2c -x 16 https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
# 将mnist.npz移动到~/.keras/datasets/
# tf.keras.datasets.mnist.load_data会去读取~/.keras/datasets/mnist.npz,而不从网络下载
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = np.reshape(x_train, (-1, 1, 28, 28))
x_test = np.reshape(x_test, (-1, 1, 28, 28))
return x_train, y_train, x_test, y_test
def build_model():
# 基于keras构建模型
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.InputLayer(input_shape=[1, 28, 28], name="InputLayer"))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(512))
model.add(tf.keras.layers.Activation(activation=tf.nn.relu6, name="ReLU6"))
model.add(tf.keras.layers.Dense(10, activation=tf.nn.softmax, name="OutputLayer"))
return model
def train_model():
''' 1 - 构建和编译模型 '''
model = build_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
''' 2 - 装载数据 '''
x_train, y_train, x_test, y_test = load_data()
''' 3 - 模型训练 '''
model.fit(
x_train, y_train,
epochs = 10,
verbose = 1
)
'''4 - 在测试样本上验证'''
test_loss, test_acc = model.evaluate(x_test, y_test)
print("Test loss: {}\nTest accuracy: {}".format(test_loss, test_acc))
return model
def maybe_mkdir(dir_path):
if not os.path.exists(dir_path):
os.makedirs(dir_path)
def save_model(model):
output_names = model.output.op.name
sess = tf.keras.backend.get_session()
graphdef = sess.graph.as_graph_def()
frozen_graph = tf.graph_util.convert_variables_to_constants(sess, graphdef, [output_names])
frozen_graph = tf.graph_util.remove_training_nodes(frozen_graph)
# Make directory to save model in if it doesn't exist already
maybe_mkdir(MODEL_DIR)
model_path = os.path.join(MODEL_DIR, "trained_lenet5.pb")
with open(model_path, "wb") as ofile:
ofile.write(frozen_graph.SerializeToString())
if __name__ == "__main__":
model = train_model()
save_model(model)
上述可直接训练得到模型

#ifndef CLIP_KERNEL_H
#define CLIP_KERNEL_H
#include "NvInfer.h"
//其就是提供一个函数声明,以供后续调用
int clipInference(
cudaStream_t stream,
int n,
float clipMin,
float clipMax,
const void* input,
void* output);
#endif对应的clipKernel.cu
include <clipKernel.h>
//以模板形式实现min,max等函数
template <typename T>
__device__ __forceinline__ const T& min(const T& a, const T& b)
{
return (a > b) ? b : a;
}
template <typename T>
__device__ __forceinline__ const T& max(const T& a, const T& b)
{
return (a > b) ? a : b;
}
//clipKernel函数的定义
template <typename T, unsigned nthdsPerCTA>
__launch_bounds__(nthdsPerCTA)
__global__ void clipKernel(
int n,
const T clipMin,
const T clipMax,
const T* input,
T* output)
{
for (int i = blockIdx.x * nthdsPerCTA + threadIdx.x; i < n; i += gridDim.x * nthdsPerCTA)
{
output[i] = min<T>(max<T>(input[i], clipMin), clipMax);
}
}
//建立gpu网格,调用上面的kernel
int clipInference(
cudaStream_t stream,
int n,
float clipMin,
float clipMax,
const void* input,
void* output)
{
const int blockSize = 512;
const int gridSize = (n + blockSize - 1) / blockSize;
clipKernel<float, blockSize><<<gridSize, blockSize, 0, stream>>>(n, clipMin, clipMax,
static_cast<const float*>(input),
static_cast<float*>(output));
return 0;
}接着看customClipPlugin.h
#ifndef CUSTOM_CLIP_PLUGIN_H
#define CUSTOM_CLIP_PLUGIN_H
#include "NvInferPlugin.h"
#include <string>
#include <vector>
using namespace nvinfer1;
// One of the preferred ways of making TensorRT to be able to see
// our custom layer requires extending IPluginV2 and IPluginCreator classes.
// For requirements for overriden functions, check TensorRT API docs.
//创建ClipPlugin类
class ClipPlugin : public IPluginV2
{
public:
ClipPlugin(const std::string name, float clipMin, float clipMax);
ClipPlugin(const std::string name, const void* data, size_t length);
// 无参构造函数无意义,所以这里删除默认构造函数.
ClipPlugin() = delete;
int getNbOutputs() const override;
Dims getOutputDimensions(int index, const Dims* inputs, int nbInputDims) override;
int initialize() override;
void terminate() override;
size_t getWorkspaceSize(int) const override { return 0; };
int enqueue(int batchSize, const void* const* inputs, void** outputs, void* workspace, cudaStream_t stream) override;
size_t getSerializationSize() const override;
void serialize(void* buffer) const override;
void configureWithFormat(const Dims* inputDims, int nbInputs, const Dims* outputDims, int nbOutputs, DataType type, PluginFormat format, int maxBatchSize) override;
bool supportsFormat(DataType type, PluginFormat format) const override;
const char* getPluginType() const override;
const char* getPluginVersion() const override;
void destroy() override;
nvinfer1::IPluginV2* clone() const override;
void setPluginNamespace(const char* pluginNamespace) override;
const char* getPluginNamespace() const override;
private:
const std::string mLayerName;
float mClipMin, mClipMax;
size_t mInputVolume;
std::string mNamespace;
};
//定义ClipPluginCreator类
class ClipPluginCreator : public IPluginCreator
{
public:
ClipPluginCreator();
const char* getPluginName() const override;
const char* getPluginVersion() const override;
const PluginFieldCollection* getFieldNames() override;
IPluginV2* createPlugin(const char* name, const PluginFieldCollection* fc) override;
IPluginV2* deserializePlugin(const char* name, const void* serialData, size_t serialLength) override;
void setPluginNamespace(const char* pluginNamespace) override;
const char* getPluginNamespace() const override;
private:
static PluginFieldCollection mFC;
static std::vector<PluginField> mPluginAttributes;
std::string mNamespace;
};
#endif接着看customClipPlugin.cpp
#include "customClipPlugin.h"
#include "NvInfer.h"
#include "clipKernel.h"
#include <vector>
#include <cassert>
#include <cstring>
using namespace nvinfer1;
// Clip plugin specific constants
namespace {
static const char* CLIP_PLUGIN_VERSION{"1"};
static const char* CLIP_PLUGIN_NAME{"CustomClipPlugin"};
}
// Static class fields initialization
PluginFieldCollection ClipPluginCreator::mFC{};
std::vector<PluginField> ClipPluginCreator::mPluginAttributes;
REGISTER_TENSORRT_PLUGIN(ClipPluginCreator);
// 帮助函数,用于序列化plugin
template<typename T>
void writeToBuffer(char*& buffer, const T& val)
{
*reinterpret_cast<T*>(buffer) = val;
buffer += sizeof(T);
}
// 帮助函数,用于反序列化plugin
template<typename T>
T readFromBuffer(const char*& buffer)
{
T val = *reinterpret_cast<const T*>(buffer);
buffer += sizeof(T);
return val;
}
/*开始实现ClipPlugin类中成员函数的定义*/
ClipPlugin::ClipPlugin(const std::string name, float clipMin, float clipMax)
: mLayerName(name)
, mClipMin(clipMin)
, mClipMax(clipMax)
{
}
ClipPlugin::ClipPlugin(const std::string name, const void* data, size_t length)
: mLayerName(name)
{
// Deserialize in the same order as serialization
const char *d = static_cast<const char *>(data);
const char *a = d;
mClipMin = readFromBuffer<float>(d);
mClipMax = readFromBuffer<float>(d);
assert(d == (a + length));
}
const char* ClipPlugin::getPluginType() const
{
return CLIP_PLUGIN_NAME;
}
const char* ClipPlugin::getPluginVersion() const
{
return CLIP_PLUGIN_VERSION;
}
int ClipPlugin::getNbOutputs() const
{
return 1;
}
Dims ClipPlugin::getOutputDimensions(int index, const Dims* inputs, int nbInputDims)
{
// Validate input arguments
assert(nbInputDims == 1);
assert(index == 0);
// Clipping doesn't change input dimension, so output Dims will be the same as input Dims
return *inputs;
}
int ClipPlugin::initialize()
{
return 0;
}
int ClipPlugin::enqueue(int batchSize, const void* const* inputs, void** outputs, void*, cudaStream_t stream)
{
int status = -1;
// Our plugin outputs only one tensor
void* output = outputs[0];
// Launch CUDA kernel wrapper and save its return value
status = clipInference(stream, mInputVolume * batchSize, mClipMin, mClipMax, inputs[0], output);
return status;
}
size_t ClipPlugin::getSerializationSize() const
{
return 2 * sizeof(float);
}
void ClipPlugin::serialize(void* buffer) const
{
char *d = static_cast<char *>(buffer);
const char *a = d;
writeToBuffer(d, mClipMin);
writeToBuffer(d, mClipMax);
assert(d == a + getSerializationSize());
}
void ClipPlugin::configureWithFormat(const Dims* inputs, int nbInputs, const Dims* outputs, int nbOutputs, DataType type, PluginFormat format, int)
{
// Validate input arguments
assert(nbOutputs == 1);
assert(type == DataType::kFLOAT);
assert(format == PluginFormat::kNCHW);
// Fetch volume for future enqueue() operations
size_t volume = 1;
for (int i = 0; i < inputs->nbDims; i++) {
volume *= inputs->d[i];
}
mInputVolume = volume;
}
bool ClipPlugin::supportsFormat(DataType type, PluginFormat format) const
{
// This plugin only supports ordinary floats, and NCHW input format
if (type == DataType::kFLOAT && format == PluginFormat::kNCHW)
return true;
else
return false;
}
void ClipPlugin::terminate() {}
void ClipPlugin::destroy() {
// This gets called when the network containing plugin is destroyed
delete this;
}
IPluginV2* ClipPlugin::clone() const
{
return new ClipPlugin(mLayerName, mClipMin, mClipMax);
}
void ClipPlugin::setPluginNamespace(const char* libNamespace)
{
mNamespace = libNamespace;
}
const char* ClipPlugin::getPluginNamespace() const
{
return mNamespace.c_str();
}
/*开始实现ClipPluginCreator类中成员函数定义*/
ClipPluginCreator::ClipPluginCreator()
{
// Describe ClipPlugin's required PluginField arguments
mPluginAttributes.emplace_back(PluginField("clipMin", nullptr, PluginFieldType::kFLOAT32, 1));
mPluginAttributes.emplace_back(PluginField("clipMax", nullptr, PluginFieldType::kFLOAT32, 1));
// Fill PluginFieldCollection with PluginField arguments metadata
mFC.nbFields = mPluginAttributes.size();
mFC.fields = mPluginAttributes.data();
}
const char* ClipPluginCreator::getPluginName() const
{
return CLIP_PLUGIN_NAME;
}
const char* ClipPluginCreator::getPluginVersion() const
{
return CLIP_PLUGIN_VERSION;
}
const PluginFieldCollection* ClipPluginCreator::getFieldNames()
{
return &mFC;
}
IPluginV2* ClipPluginCreator::createPlugin(const char* name, const PluginFieldCollection* fc)
{
float clipMin, clipMax;
const PluginField* fields = fc->fields;
// Parse fields from PluginFieldCollection
assert(fc->nbFields == 2);
for (int i = 0; i < fc->nbFields; i++){
if (strcmp(fields[i].name, "clipMin") == 0) {
assert(fields[i].type == PluginFieldType::kFLOAT32);
clipMin = *(static_cast<const float*>(fields[i].data));
} else if (strcmp(fields[i].name, "clipMax") == 0) {
assert(fields[i].type == PluginFieldType::kFLOAT32);
clipMax = *(static_cast<const float*>(fields[i].data));
}
}
return new ClipPlugin(name, clipMin, clipMax);
}
IPluginV2* ClipPluginCreator::deserializePlugin(const char* name, const void* serialData, size_t serialLength)
{
// This object will be deleted when the network is destroyed, which will
// call ClipPlugin::destroy()
return new ClipPlugin(name, serialData, serialLength);
}
void ClipPluginCreator::setPluginNamespace(const char* libNamespace)
{
mNamespace = libNamespace;
}
const char* ClipPluginCreator::getPluginNamespace() const
{
return mNamespace.c_str();
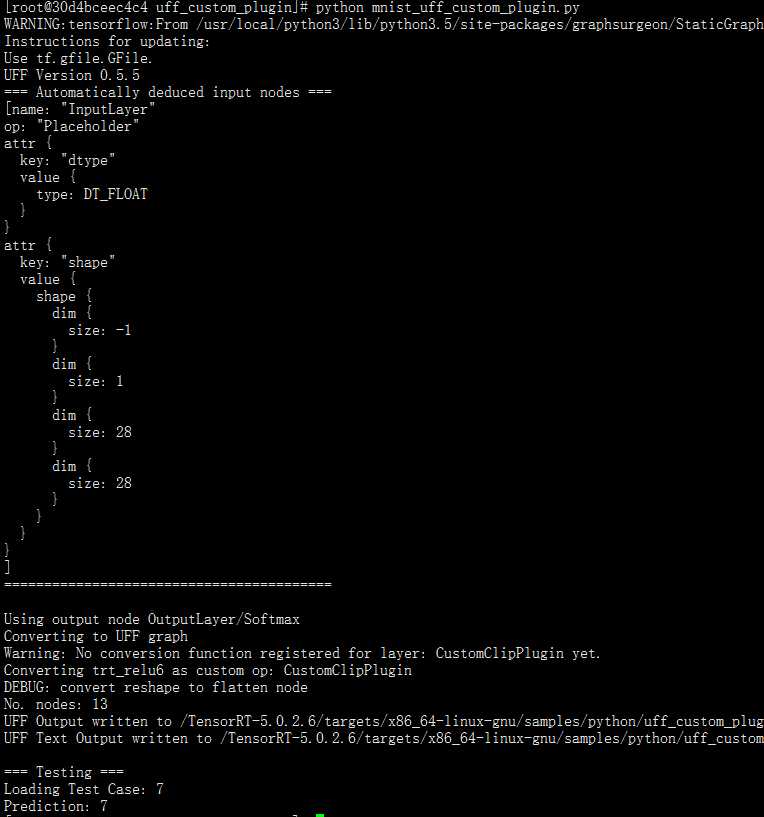
}最后我们看看mnist_uff_custom_plugin.py
import sys
import os
import ctypes
from random import randint
from PIL import Image
import numpy as np
import tensorflow as tf
import pycuda.driver as cuda
import pycuda.autoinit
import tensorrt as trt
import graphsurgeon as gs
import uff
# ../common.py
sys.path.insert(1,
os.path.join(
os.path.dirname(os.path.realpath(__file__)),
os.pardir
)
)
import common
# lenet5.py
import lenet5
MNIST_IMAGE_SIZE = 28
MNIST_CHANNELS = 1
MNIST_CLASSES = 10
# clipplugin动态链接库的位置
CLIP_PLUGIN_LIBRARY = os.path.join(
os.path.dirname(os.path.realpath(__file__)),
'build/libclipplugin.so'
)
# 生成的模型的位置
MODEL_PATH = os.path.join(
os.path.dirname(os.path.realpath(__file__)),
'models/trained_lenet5.pb'
)
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
class ModelData(object):
INPUT_NAME = "InputLayer"
INPUT_SHAPE = (MNIST_CHANNELS, MNIST_IMAGE_SIZE, MNIST_IMAGE_SIZE)
RELU6_NAME = "ReLU6"
OUTPUT_NAME = "OutputLayer/Softmax"
OUTPUT_SHAPE = (MNIST_IMAGE_SIZE, )
DATA_TYPE = trt.float32
'''main中第二步,被model_to_uff调用 '''
# 将未支持的tf操作映射到tensorrt plugin
def prepare_namespace_plugin_map():
# 本例子中,唯一未支持的就是tf.nn.relu6, 所以这里创建一个新节点,告诉UffParser
# tf.nn.relu6的位置和参数
# The "clipMin" and "clipMax" fields of this TensorFlow node will be parsed by createPlugin,
# and used to create a CustomClipPlugin with the appropriate parameters.
trt_relu6 = gs.create_plugin_node(name="trt_relu6", op="CustomClipPlugin", clipMin=0.0, clipMax=6.0)
namespace_plugin_map = {
ModelData.RELU6_NAME: trt_relu6
}
return namespace_plugin_map
'''main中第二步:被model_to_uff调用 '''
# 从pb路径中获取uff路径(e.g. /a/b/c/d.pb -> /a/b/c/d.uff)
def model_path_to_uff_path(model_path):
uff_path = os.path.splitext(model_path)[0] + ".uff"
return uff_path
'''main中第二步:被build_engine调用 '''
# 使用UFF转换器将tf固化的graphdef转换成UFF格式
def model_to_uff(model_path):
# Transform graph using graphsurgeon to map unsupported TensorFlow
# operations to appropriate TensorRT custom layer plugins
dynamic_graph = gs.DynamicGraph(model_path)
dynamic_graph.collapse_namespaces(prepare_namespace_plugin_map())
# Save resulting graph to UFF file
output_uff_path = model_path_to_uff_path(model_path)
uff.from_tensorflow(
dynamic_graph.as_graph_def(),
[ModelData.OUTPUT_NAME],
output_filename=output_uff_path,
text=True
)
return output_uff_path
'''main中第二步:构建engine '''
def build_engine(model_path):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.UffParser() as parser:
builder.max_workspace_size = common.GiB(1)
uff_path = model_to_uff(model_path)
parser.register_input(ModelData.INPUT_NAME, ModelData.INPUT_SHAPE)
parser.register_output(ModelData.OUTPUT_NAME)
parser.parse(uff_path, network)
return builder.build_cuda_engine(network)
'''main第四步:读取测试样本,并归一化 '''
def load_normalized_test_case(pagelocked_buffer):
_, _, x_test, y_test = lenet5.load_data()
num_test = len(x_test)
case_num = randint(0, num_test-1)
img = x_test[case_num].ravel()
np.copyto(pagelocked_buffer, img)
return y_test[case_num]
def main():
''' 1 - 装载动态链接库'''
# By doing this, you will also register the Clip plugin with the TensorRT
# PluginRegistry through use of the macro REGISTER_TENSORRT_PLUGIN present
# in the plugin implementation. Refer to plugin/clipPlugin.cpp for more details.
if not os.path.isfile(CLIP_PLUGIN_LIBRARY):
raise IOError("\n{}\n{}\n{}\n".format(
"Failed to load library ({}).".format(CLIP_PLUGIN_LIBRARY),
"Please build the Clip sample plugin.",
"For more information, see the included README.md"
))
ctypes.CDLL(CLIP_PLUGIN_LIBRARY)
''' 2 - 判断训练好的模型是否存在'''
if not os.path.isfile(MODEL_PATH):
raise IOError("\n{}\n{}\n{}\n".format(
"Failed to load model file ({}).".format(MODEL_PATH),
"Please use 'python lenet5.py' to train and save the model.",
"For more information, see the included README.md"
))
''' 3 - 用build_engine构建engine,然后检索其中保存的模型mean值'''
with build_engine(MODEL_PATH) as engine:
''' 4 - 分配buffers, 创建一个流'''
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
with engine.create_execution_context() as context:
print("\n=== Testing ===")
''' 5 - 读取测试样本,并归一化'''
test_case = load_normalized_test_case(inputs[0].host)
print("Loading Test Case: " + str(test_case))
''' 6 -执行inference,do_inference函数会返回一个list类型,此处只有一个元素 '''
[pred] = common.do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
print("Prediction: " + str(np.argmax(pred)))
if __name__ == "__main__":
main()运行结果为:
TensorRT&Sample&Python[uff_custom_plugin]
标签:tensor dma register amp manual gnu inter 转换 flat
原文地址:https://www.cnblogs.com/shouhuxianjian/p/10532950.html