标签:false 方法 背景 移除 pkg schedule effect 阅读 pts
继上一篇《Kubernetes的污点和容忍(上篇)》,这是https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/ 译文的下半部分。
经常看外文文档或书籍多了,会产生一个问题:“不方便沟通。”不太会用大家习惯的表述方式来阐述一个问题。所以需要定期看一些中文书籍来学习「行话」。
污点和容忍是一种让Pod不被调度到指定node或者是把不该在某个node上运行的Pod踢掉的灵活方法。下面列举一些使用场景。
指定node:如果想为特殊的用户指定一组node,可以添加一个污点到这组node上(运行命令: kubectl taint nodes nodename dedicated=groupName:NoSchedule)。然后添加对应的容忍到这个Pod上(这个最容易实现的方法是写一个客户端准入控制器)。带有相应容忍的Pod就可以像被调度到集群中其他node一样被调度到带有相应污点的node上。
特殊硬件的node:在一个有一小组特殊硬件(例如GPU)的集群中,更希望将没有特殊硬件需求的Pod不调度到这些node上,留出空间给后来的需要这些特殊硬件的Pod。这个通过给特殊硬件打上污点(例如:kubectl taint nodes nodename special=true:NoSchedule or kubectl taint nodes nodename special=true:PreferNoSchedule),然后添加相应的容忍到Pod上来实现。在这些使用场景,最容易实现的方法是使用客户端准入控制器来实现。例如,推荐使用Extended Resources 来代表特殊硬件,将带有扩展资源名的硬件打上污点。然后运行ExtendedResourceToleration准入控制器. 现在,由于这些node已经被打上污点了,没有容忍的Pod不会被调度到上面。但是当你提交了一个需要扩展资源的Pod,ExtendedResourceToleration准入控制器会自动的添加正确的容忍到Pod上,Pod就可以被调度到这个特殊硬件的node上了。这会确保这些特殊硬件的node是需要相应的硬件的,并且不需要手动给Pod添加容忍。
基于污点的驱逐(beta版本特性):下面我们会介绍当node发生故障时基于单个Pod配置的驱逐行为。
早期我们提到了NoExecute污点的effect会影响已经在node上运行的Pod。
不能容忍污点的Pod会被立即驱逐。
Pod上的容忍没有指定tolerationSeconds会好好的呆在node上。
Pod上的容忍带有tolerationSeconds的会在node上停留指定的时间。
另外,Kubernets 1.6 引入了代表node问题的污点(在1.6版本是alpha版试用)。换句话说,node控制器当某种条件成立的时候会自动的给node打上污点。下面是其中内置的污点:
node.kubernetes.io/not-ready:node不是ready状态。对应于node的condition ready=false.
node.kubernetes.io/unreachable:node controller与node失联了。对应于node的condition ready=unknown
node.kubernetes.io/out-of-disk:node磁盘空间不足了。
node.kubernetes.io/network-unavailable:node的网断了
node.kubernets.io/unschedulable:node不是可调度状态
node.cloudprovider.kubernetes.io/uninitalized:kubelet是由外部云提供商提供的时候,刚开始的时候会打上这个污点来标记还未被使用。当cloud-controller-manager控制器初始化完这个node,kubelet会自动移除这个污点。
在1.13版本中,「基于污点的驱逐」特性被提升至beta版,并且被默认开启。因为这些污点会被自动添加到node控制器(或kubelet)中。而之前的常使用的逻辑:基于condition中ready状态来驱逐pod也被禁用了。
注意:
为了维持在node故障时对存在的Pod驱逐做限流,系统实际上是用限速的方法来添加污点的。这种措施防止了master与node脑裂而产生的大规模驱逐Pod的场景。
这个beta版本特性再结合tolerationSeconds,可以使得pod指定当node节点出现问题的时候一个pod能在node上呆多久。
举个栗子:
一个有很多本地状态的应用可能想在产生网络脑裂的时候还能在node上呆很久。这样是希望脑裂会恢复,从而避免pod被驱逐。为了达到这个目的,可以这样用:
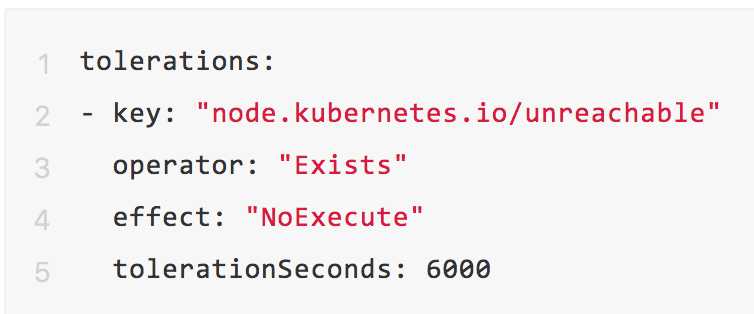
Kubernetes会自动给pod添加容忍:node.kubernetes.io/not-ready 实效是tolerationSeconds=300。但是如果用户自己给这个pod添加了node.kubernets.io/not-ready的容忍,用户的配置不会被覆盖。
类似的,它也会自动给pod添加容忍:node.kubernetes.io/unreachable 实效是tolerationSeconds=300。但是如果用户自己给这个pod添加了node.kubernetes.io/unreahable,用户的配置不会被覆盖。
这种自动添加容忍机制确保了默认pod如果宿主机发生故障在5分钟之内不会被自动驱逐。这两个默认的容忍都是https://github.com/kubernetes/kubernetes/tree/master/plugin/pkg/admission/defaulttolerationseconds (DefaultTolerationSeconds admission controller)这个控件来添加的。
DaemonSet的pod会默认添加一个NoExecute不带有tolerationSeconds的容忍:
node.kubernetes.io/unreachable
node.kubernetes.io/not-ready
这种方式确保了DaemonSet的Pod在发生故障的时候永远不会被驱逐。
在版本1.12中,「condition驱动的污点」特性被提升到beta版,node的生命周期控制器自动的创建condition相应的污点。类似的,调度器并不检查node的condition,而是检查污点。这种方式是用来保证node的condition不会影响已经调度到这台node的Pod。用户可以用添加合适的容忍来忽视node的一些问题(condition是其中的代表)。在这个版本中「condition驱动的污点」只是打上了effect=NoSchedule的污点。而在1.13版本中才将effect=NoExcute作为beta版默认开启。
从Kubernetes1.8版本开始,DaemonSet控制器自动的添加了NoSchedule容忍到所有的daemon线程来避免DaemonSets中断。
node.kubernetes.io/memory-pressure
node.kubernetes.io/disk-pressure
node.kubernetes.io/out-of-disk(只对重要的pod生效)
node.kubernetes.io/unschedulable(1.10版本后生效)
node.kubernetes.io/network-unavailable(只针对主机网络)
添加这些容忍确保了向后兼容,用户可以随意对DaemonSets添加容忍。
相关阅读
 作者是一个有美国硅谷、日本东京工作经验,十二年坚持一线写代码的程序媛。坚持原创文章。欢迎技术交流!
作者是一个有美国硅谷、日本东京工作经验,十二年坚持一线写代码的程序媛。坚持原创文章。欢迎技术交流!
标签:false 方法 背景 移除 pkg schedule effect 阅读 pts
原文地址:https://www.cnblogs.com/xiexj/p/10561237.html