标签:i++ class 图片 派生类 gcc编译 容量 ref 语句 存储器
值传递要拷贝对象,引用传递不用
i++开辟了临时变量,效率低
内联函数直接会直接展开,不需要函数调用的开销
函数调用需要两次跳转,外加栈帧的内存操作
理由和上面一样
转载自:https://www.jb51.net/article/54773.htm
当对一个类对象初始化时,如果“=”右边不是一个类对象时,会先调用转换构造函数生成一个临时变量作为拷贝构造函数的形参,再调用拷贝构造函数;编译器可能会给你优化,把 ClassTest ct2 = "ab"; 优化为 ClassTest ct2("ab") ,就不会有上述的过程,但有的编译器它也不优化
dynamic_cast运算符用于将基类的指针或引用安全地转换成派生类的指针或引用,这种转换是非常低效的,对程序的性能影响也比较大,尽量少用
vector的swap操作,它只是将两个vector指向空间等等信息交换了一下,而不会引起元素的拷贝,它的操作是常数级的,和交互对象中元素数目无关
gcc编译的时候有O1~O3的优化选项,O0为不优化,gcc编译时的默认值
//代码1 for(int i = 0; i < n; ++i) { fun1(); fun2(); } //代码2 for(int i = 0; i < n; ++i) { fun1(); } for(int i = 0; i < n; ++i) { fun2(); }
1)如果这多个函数的代码语句很少,则代码1的运行效率高一些,但是若fun1和fun2的语句有很多,规模较大,则代码2的运行效率会比代码1显著高得多
2)由于CPU只能从内存在读取数据,而CPU的运算速度远远大于内存,所以为了提高程序的运行速度有效地利用CPU的能力,在内存与CPU之间有一个叫Cache的存储器,它的速度接近CPU。而Cache中的数据是从内存中加载而来的,这个过程需要访问内存,速度较慢
3)Cache的设计原理:时间局部性和空间局部性,时间局部性是指如果一个存储单元被访问,则可能该单元会很快被再次访问,这是因为程序存在着循环。空间局部性是指如果一个储存单元被访问,则该单元邻近的单元也可能很快被访问,这是因为程序中大部分指令是顺序存储、顺序执行的,数据也一般也是以向量、数组、树、表等形式簇聚在一起的
4)如果fun1和fun2的代码量很大,例如都大于Cache的容量,则在代码1中,就不能充分利用Cache了(由时间局部性和空间局部性可知),因为每循环一次,都要把Cache中的内容踢出,重新从内存中加载另一个函数的代码指令和数据,而代码2则更很好地利用了Cache,利用两个循环语句,每个循环所用到的数据几乎都已加载到Cache中,每次循环都可从Cache中读写数据,访问内存较少,速度较快,理论上来说只需要完全踢出fun1的数据1次即可
局部变量使用的是栈,当一个数据被反复读取的时候,数据会留在CPU的Cache中,访问速度非常快。这样来看就是局部变量效率更高了
转载自:https://blog.csdn.net/yunhua_lee/article/details/6381866
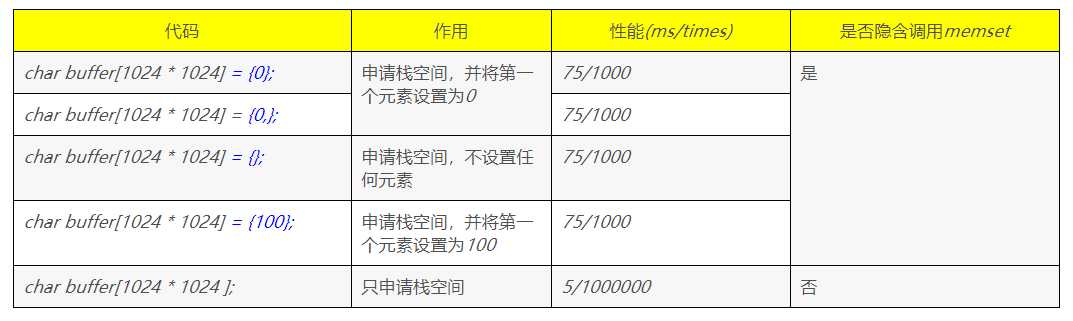
字符数组如果可以不初始化就不进行初始化,即使你初始化部分数组的元素,底层默认也会调用memset()帮你初始化其他元素为0,增大开销
标签:i++ class 图片 派生类 gcc编译 容量 ref 语句 存储器
原文地址:https://www.cnblogs.com/Joezzz/p/10568057.html