标签:input idt def identity 结构 怎么 认知 turn range
resnet 又叫深度残差网络
据说是目前世界上图像识别准确率最高的,主要作者是国人哦
深度网络的退化问题
深度网络难以训练,梯度消失,梯度爆炸,老生常谈,不多说
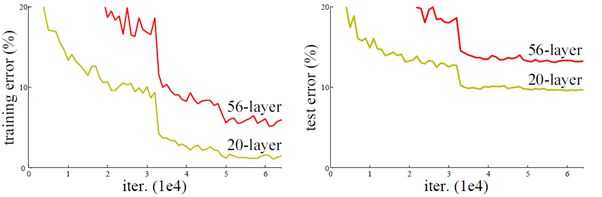
resnet 解决了这个问题,并且将网络深度扩展到了最多152层。怎么解决的呢?
残差学习
结构如图
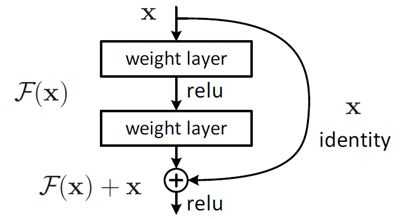
在普通的卷积过程中加入了一个x的恒等映射(identity mapping)
专家把这称作 skip connections 或者 shortcut connections
为什么要这样呢?下面我从多个角度阐述这个问题。
生活角度
每学习一个模型,我都希望能用日常的生活去解释为什么模型要这样,一是加深对模型的理解,二是给自己搭建模型寻找灵感,三是给优化模型寻找灵感。
resnet 无疑是解决很难识别的问题的,那我举一个日常生活中人类也难以识别的问题,看看这个模型跟人类的识别方法是否一致。
比如人类识别杯子里的水烫不烫
一杯水,我摸了一下,烫,好,我的神经开始运转,最后形成理论杯子里的水烫,这显然不对
又一杯水,我一摸,不烫,好嘛,这咋办,认知混乱了,也就是无法得到有效的参数,
那人类是怎么办呢?
我们不止是摸一摸,而且在摸过之后还要把杯子拿起来仔细看看,有什么细节可以帮助我们更好的识别,这就是在神经经过运转后,又把x整体输入,
当然即使我们拿起杯子看半天,也可能看不出任何规律来帮助我们识别,那人类的作法是什么呢?我记住吧,这种情况要小心,这就是梯度消失了,学习不到任何规律,记住就是恒等映射,
这个过程和resnet是一致的。
网络结构角度
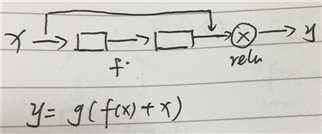
当梯度消失时,f(x)=0,y=g(x)=relu(x)=x,怎么理解呢?
1. 当梯度消失时,模型就是记住,长这样的就是该类别,是一个大型的过滤器
2. 在网络上堆叠这样的结构,就算梯度消失,我什么也学不到,我至少把原来的样子恒等映射了过去,相当于在浅层网络上堆叠了“复制层”,这样至少不会比浅层网络差。
3. 万一我不小心学到了什么,那就赚大了,由于我经常恒等映射,所以我学习到东西的概率很大。
数学角度

可以看到 有1 的存在,导数基本不可能为0
那为什么叫残差学习呢
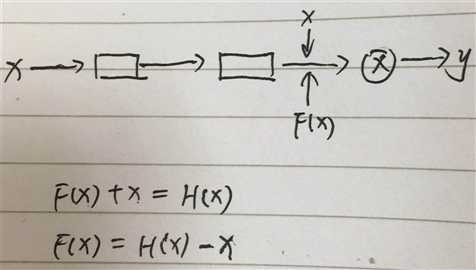
可以看到 F(x) 通过训练参数 得到了 H(x)-x,也就是残差,所以叫残差学习,这比学习H(x)要简单的多。
等效映射 identity mapping
上面提到残差学习中需要进行 F(x)+x,在resnet中,卷积都是 same padding 的,当通道数相同时,直接相加即可,
但是通道数不一样时需要寻求一种方法使得 y=f(x)+wx
实现w有两种方式
1. 直接补0
2. 通过使用多个 1x1 的卷积来增加通道数。
网络结构
block
block为一个残差单元,resnet 网络由多个block 构成,resnet 提出了两种残差单元

左边针对的是ResNet34浅层网络,右边针对的是ResNet50/101/152深层网络,右边这个又被叫做 bottleneck
整体结构
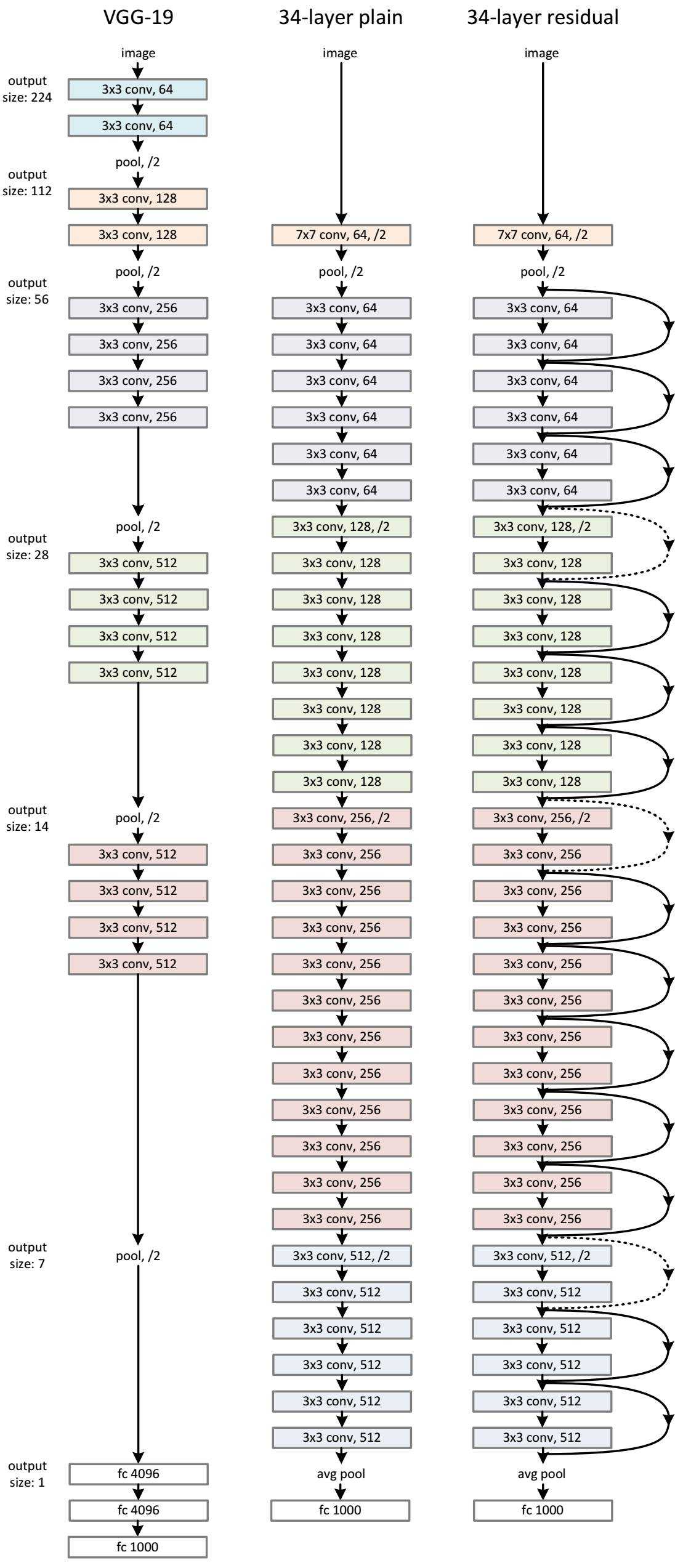
1. 与vgg相比,其参数少得多,因为vgg有3个全连接层,这需要大量的参数,而resnet用 avg pool 代替全连接,节省大量参数。
2. 参数少,残差学习,所以训练效率高
resnet50示例代码
注意我标注的层数
class ResNet50(object): def __init__(self, inputs, num_classes=1000, is_training=True, scope="resnet50"): self.inputs =inputs self.is_training = is_training self.num_classes = num_classes with tf.variable_scope(scope): # construct the model ### 1层 net = conv2d(inputs, 64, 7, 2, scope="conv1") # -> [batch, 112, 112, 64] net = tf.nn.relu(batch_norm(net, is_training=self.is_training, scope="bn1")) net = max_pool(net, 3, 2, scope="maxpool1") # -> [batch, 56, 56, 64] ### 每个bottleneck3层, 16 * 3 = 48层 net = self._block(net, 256, 3, init_stride=1, is_training=self.is_training, scope="block2") # -> [batch, 56, 56, 256] net = self._block(net, 512, 4, is_training=self.is_training, scope="block3") # -> [batch, 28, 28, 512] net = self._block(net, 1024, 6, is_training=self.is_training, scope="block4") # -> [batch, 14, 14, 1024] net = self._block(net, 2048, 3, is_training=self.is_training, scope="block5") # -> [batch, 7, 7, 2048] net = avg_pool(net, 7, scope="avgpool5") # -> [batch, 1, 1, 2048] net = tf.squeeze(net, [1, 2], name="SpatialSqueeze") # -> [batch, 2048] # 1层 self.logits = fc(net, self.num_classes, "fc6") # -> [batch, num_classes] self.predictions = tf.nn.softmax(self.logits) def _block(self, x, n_out, n, init_stride=2, is_training=True, scope="block"): with tf.variable_scope(scope): h_out = n_out // 4 out = self._bottleneck(x, h_out, n_out, stride=init_stride, is_training=is_training, scope="bottlencek1") for i in range(1, n): out = self._bottleneck(out, h_out, n_out, is_training=is_training, scope=("bottlencek%s" % (i + 1))) return out def _bottleneck(self, x, h_out, n_out, stride=None, is_training=True, scope="bottleneck"): """ A residual bottleneck unit""" n_in = x.get_shape()[-1] if stride is None: stride = 1 if n_in == n_out else 2 with tf.variable_scope(scope): # 3层 h = conv2d(x, h_out, 1, stride=stride, scope="conv_1") h = batch_norm(h, is_training=is_training, scope="bn_1") h = tf.nn.relu(h) h = conv2d(h, h_out, 3, stride=1, scope="conv_2") h = batch_norm(h, is_training=is_training, scope="bn_2") h = tf.nn.relu(h) h = conv2d(h, n_out, 1, stride=1, scope="conv_3") h = batch_norm(h, is_training=is_training, scope="bn_3") if n_in != n_out: shortcut = conv2d(x, n_out, 1, stride=stride, scope="conv_4") shortcut = batch_norm(shortcut, is_training=is_training, scope="bn_4") else: shortcut = x return tf.nn.relu(shortcut + h)
标签:input idt def identity 结构 怎么 认知 turn range
原文地址:https://www.cnblogs.com/yanshw/p/10576354.html