标签:适用于 容量 阈值 返回 数量级 情况 connect 无法 适应
神经网络既是计算密集型又是内存密集型,使得它们难以在嵌入式系统上部署。此外,传统网络在训练开始之前固定架构;因此,训练无法改善架构。为了解决这些限制,我们描述了一种方法,通过仅学习重要连接,将神经网络所需的存储和计算减少一个数量级而不影响其准确性。我们的方法使用三步法修剪冗余连接。首先,我们训练网络以了解哪些连接很重要。接下来,我们修剪不重要的连接。最后,我们重新训练网络以微调剩余连接的权重。在ImageNet数据集上,我们的方法将AlexNet的参数数量从6100万减少到670万,而不会导致精度损失。与VGG-16类似的实验发现,参数总数可以减少13,从1.38亿减少到1030万,同样不会损失准确性。
为了实现这一目标,我们提出了一种以保持原始准确度的方式修剪网络连接的方法。 在初始训练阶段之后,我们删除所有权重低于阈值的连接。 这种修剪将密集的,完全连接的层转换为稀疏层。 第一阶段学习网络的拓扑 - 学习哪些连接很重要并删除不重要的连接。 然后我们重新训练稀疏网络,以便剩余的连接可以补偿已被删除的连接。 可以迭代地重复修剪和再训练的阶段以进一步降低网络复杂性。 实际上,这个训练过程除了权重之外还学习网络连接 - 就像在哺乳动物大脑中[8] [9]一样,在孩子发育的最初几个月中创建突触,然后逐渐修剪小孩 - 使用过的连接,降到典型的成人价值观。
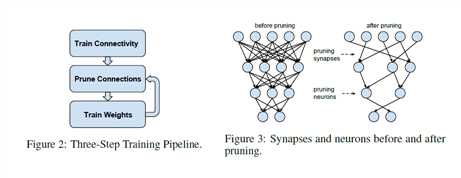
我们的修剪方法采用三步流程,如图2所示,首先通过正常的网络训练学习连接。 然而,与传统训练不同,我们没有学习权重的最终值,而是我们正在学习哪些联系很重要。
第二步是修剪低重量连接。 权重低于阈值的所有连接都将从网络中删除 - 将密集网络转换为稀疏网络,如图3所示。最后一步重新训练网络以了解剩余稀疏连接的最终权重。 这一步至关重要。 如果在没有重新训练的情况下使用修剪过的网络,则精度会受到很大影响。
选择正确的正规化会影响修剪和再训练的效果。 L1正则化惩罚非零参数,导致更多参数接近零。 这在修剪后但在重新训练之前提供了更好的准确性。 但是,其余的连接不如L2正则化,导致重新训练后的精度较低。 总的来说,L2正则化提供了最好的修剪结果。 这在实验部分中进一步讨论。
Dropout [23]被广泛用于防止过度拟合,这也适用于再训练。 但是,在再学习期间,必须调整dropout率以考虑模型容量的变化。 在dropout时,每个参数在训练期间都会被概率性地丢弃,但会在推理期间返回。 在修剪中,修剪后参数会永久丢失,并且在训练和推理期间都无法返回。 随着参数变得稀疏,分类器将选择信息量最大的预测器,因此具有更少的预测方差,这减少了过度拟合。 由于修剪已经减少了模型容量,因此再训练的dropout率应该更小。
在重新训练期间,最好保留初始训练阶段的权重,以便在修剪过程中保持连接,而不是重新初始化修剪过的层。 CNN包含脆弱的共同适应特征[24]:当网络初始训练时,梯度下降能够找到一个好的解决方案,但是在重新初始化一些层并重新训练后不能。 因此,当我们重新训练修剪过的图层时,我们应该保留幸存的参数,而不是重新初始化它们。
从保留的权重开始重新训练修剪的层需要较少的计算,因为我们不必反向传播通过整个网络。 此外,随着网络越来越深入,神经网络容易遭受消失的梯度问题[25],这使得深度网络的修剪错误更难恢复。 为了防止这种情况,我们修复了CONV层的参数,并且仅在修剪FC层后重新训练FC层,反之亦然。
学习正确的连接是一个反复的过程。 修剪后再进行再训练是一次迭代,经过许多这样的迭代后,可以找到最小数量的连接。 在不损失准确性的情况下,与单步修剪相比,此方法可以将AlexNet上的修剪率从5提高到9。 每次迭代都是一次贪婪的搜索,因为我们找到了最好的连接。 我们还根据其绝对值对概率修剪参数进行了实验,但这会产生更糟糕的结果。
修剪连接后,可以安全地修剪零输入连接或零输出连接的神经元。 通过去除与修剪过的神经元之间的所有连接来进一步修剪这种修剪。再训练阶段自动到达结果,其中死神经元将具有零输入连接和零输出连接。 这是由于梯度下降和正则化而发生的。 具有零输入连接(或零输出连接)的神经元将对最终损失没有贡献,导致其输出连接(或输入连接)的梯度分别为零。 只有正则化项才会将权重推到零。 因此,在重新训练期间将自动移除死神经元。
Learning bothWeights and Connections for Efficient Neural Networks 论文阅读
标签:适用于 容量 阈值 返回 数量级 情况 connect 无法 适应
原文地址:https://www.cnblogs.com/dushuxiang/p/10548136.html