标签:成本 splay 连接 数据库连接池 联网 问题: 运用 注意 读数
对于“读写分离”了解不多,认为数据库的负载问题都可以使用“读写分离”来解决。
这样做是不正确的,而我们就产生了这样的一个误区。我们要用“读写分离”,首先应该明白“读写分离”是用来解决什么样的问题的,而不是仅仅会用这个技术。
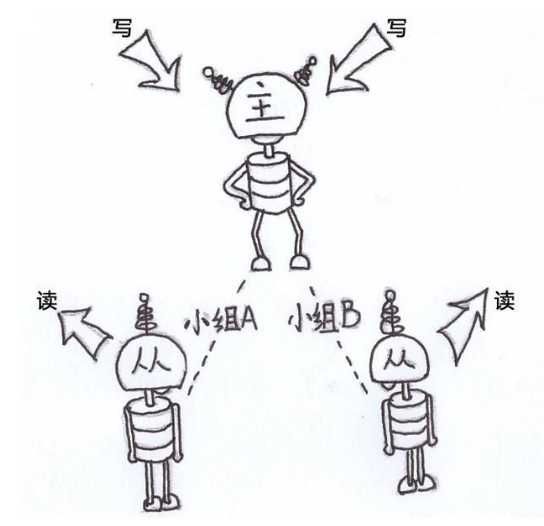
大多数互联网业务,往往读多写少,这时候,数据库的读会首先称为数据库的瓶颈,这时,如果我们希望能够线性的提升数据库的读性能,消除读写锁冲突从而提升数据库的写性能,那么就可以使用“分组架构”(读写分离架构)。
用一句话概括,读写分离是用来解决数据库的读性能瓶颈的。

但是,不是任何读性能瓶颈都需要使用读写分离,我们还可以有其他解决方案。
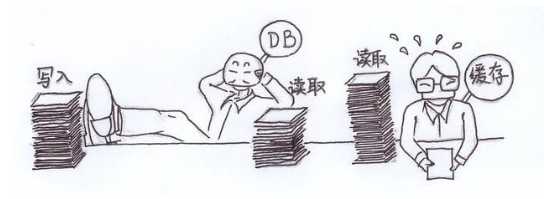
在这么多的问题需要考虑的情况下,如果我们仅仅是为了解决“数据库读的瓶颈问题”,为什么不选择使用缓存呢?
缓存,也是互联网中常常使用到的一种架构方式,同“读写分离”不同,读写分离是通过多个读库,分摊了数据库读的压力,而存储则是通过缓存的使用,减少了数据库读的压力。他们没有谁替代谁的说法,但是,如果在缓存的读写分离进行二选一时,还是应该首先考虑缓存。
为什么呢?

其实是数据容量的瓶颈。例如订单表,数据量只增不减,历史数据又必须要留存,非常容易成为性能的瓶颈,而要解决这样的数据库瓶颈问题,“读写分离”和缓存往往都不合适,最适合的是什么呢?
数据库水平切分。
大部分的互联网业务,数据量都非常大,单库容量最容易成为瓶颈,当单库的容量成为了瓶颈,我们希望提高数据库的写性能,降低单库容量的话,就可以采用水平切分了。
而有少部分程序员,会没有分析数据库的性能瓶颈是什么,就贸贸然的使用“读写分离”,殊不知“水平切分”才是正道。
标签:成本 splay 连接 数据库连接池 联网 问题: 运用 注意 读数
原文地址:https://www.cnblogs.com/donlyluik/p/database_split.html